






1.前言
最近偶然发现DMA还有一个双缓冲模式,在TI里面称为乒乓模式。感觉TI对这个描述比较形象,就像打乒乓球一样,一个球打过来,处理完再打过去。这里我画两张图来帮助大家理解这个过程,以及为什么该模式能加速整个运行效率。
在一般的运行过程中DMA将外设的数据搬运到存储器里面,然后CPU等待DMA传输完成,再进行处理,虽然DMA在执行器件CPU可以干其他事情,但是如果该外设是单一的高速信号,例如高速ADC,我们的芯片只是进行ADC处理,那么CPU必须先等待DMA搬运完成再去做别的事情,效率会大打折扣。
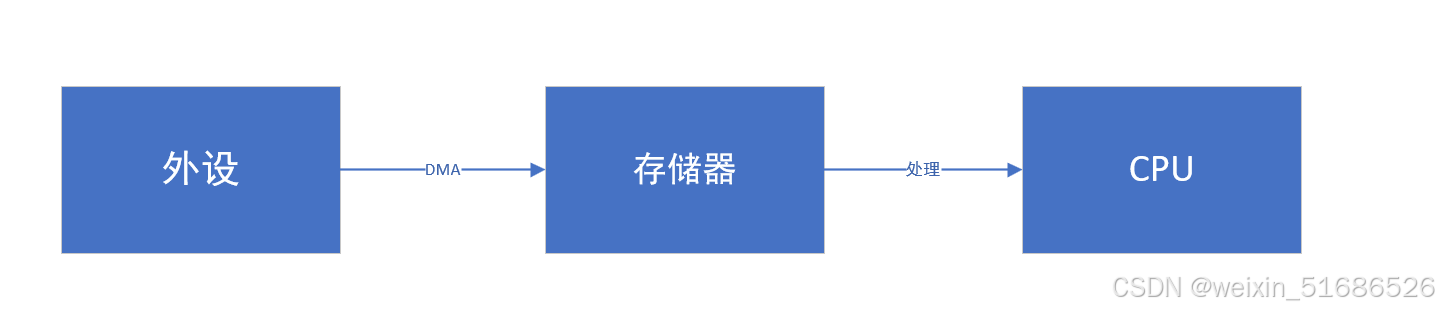
进而人们引用了另一种处理方式,首先我们需要两块存储器,DMA先将一部分数据搬运到存储器1里,而CPU先处理存储器2里已有的数据
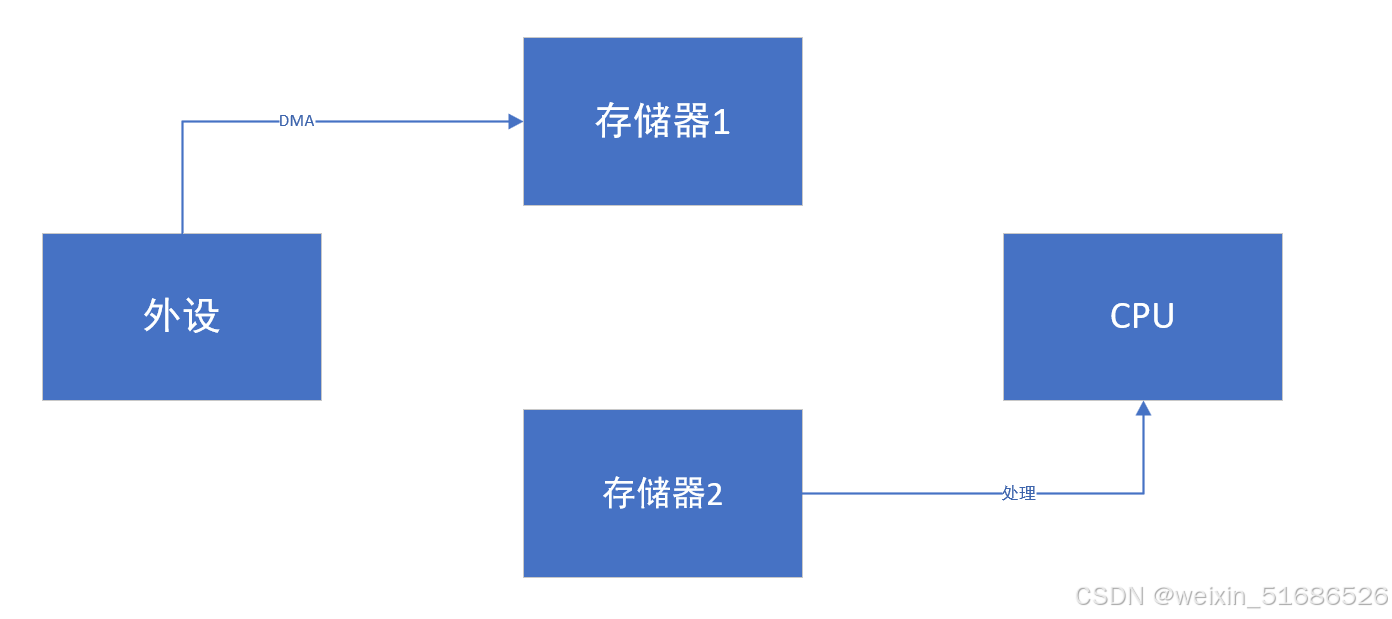
然后等DMA搬运完成后存储器1里就是最新的数据,这时CPU再处理存储器1里的数据,而DMA将外设的数据搬运到存储器2里
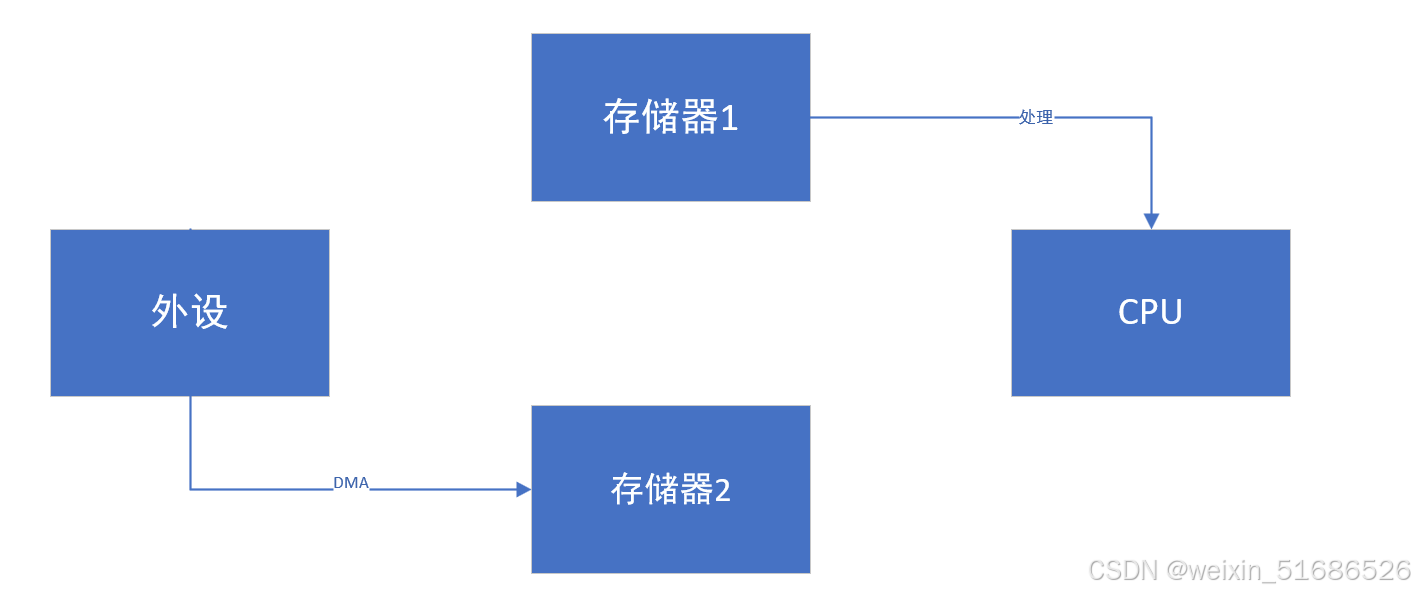 重复执行上述过程,即可比等待的效率高得多。
重复执行上述过程,即可比等待的效率高得多。
2.理论
那么我们正式开始吧,这次我以SPI发送为例。
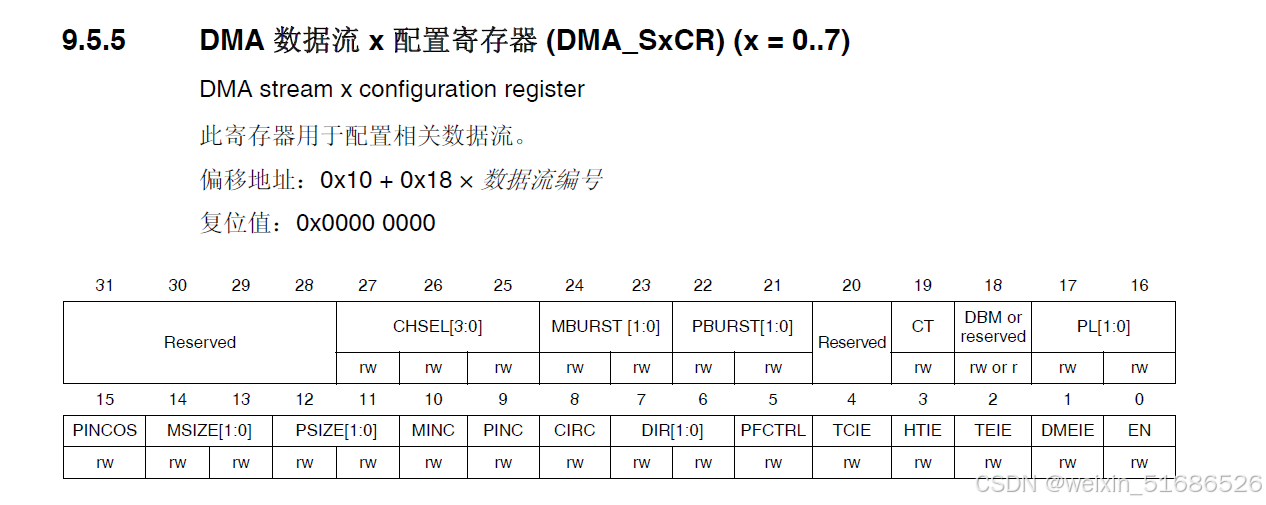
首先我们先看手册上对于双缓冲模式的描述

配置过程比较简单,只有一位DBM需要开启,然后是底线黑点处的注意点,通过控制CT位来写入两位地址。
3.程序
那么我们就正式开始写程序吧。
以下是SPI1发送端的DMA初始化过程,我用的是DMA2数据流5的通道3
//初始化DMA2 组3 通道3
//双缓冲模式
//SPI1_TX
void init_DMA2_S3C3_Dual(unsigned char *SPIData1,unsigned char *SPIData2,unsigned short SPIWEI)
{
DMA2_Stream3 ->CR = 0;//禁止数据流 ,才能写寄存器
//外设地址寄存器
//将所需寄存器的地址放入PAR寄存器
DMA2_Stream3 ->PAR = (unsigned int)(&SPI1->DR);
//数据流地址寄存器
//M1AR仅在双通道模式下有用
//将数据所在地址给M0AR寄存器
DMA2_Stream3 ->CR |= 1<<18; //开启双缓冲模式
DMA2_Stream3 ->CR |=(1<<19); //CT位置1写入M0
DMA2_Stream3 ->M0AR = (unsigned int)(SPIData1);
DMA2_Stream3 ->CR &=~(1<<19); //CT位置0写入M1
DMA2_Stream3 ->M1AR = (unsigned int)(SPIData2);
DMA2_Stream3 ->NDTR = SPIWEI; // 一次传输数量
DMA2_Stream3 ->FCR = 0x21; //FIFO所有配置失效
DMA2_Stream3 ->CR |= 1<< 6; //储存器到外设模式
//循环模式:
//当NDTR寄存器减到0时自动重装
//单次模式(普通模式):
//NDTR减到0后停止DMA
// DMA2_Stream3 ->CR &=~(1<<8); //非循环模式(无关)
DMA2_Stream3 ->CR &=~(3<<11); //外设数据长度:8位
DMA2_Stream3 ->CR &=~(3<<13); //存储器数据长度:8位
DMA2_Stream3 ->CR &= ~(1<<9); //外设非增量模式
DMA2_Stream3 ->CR |= 1<<10; //存储器增量模式,指针增加,可用于传输数组
DMA2_Stream3 ->CR |= 1<<16; //中等优先级
//突发传输
//DMA占用CPU总线时间,此时CPU无法工作
//一个节拍:传输多少次32位变量
//应用场景:从ram里读出字节
DMA2_Stream3 ->CR &= ~(3<<21); //外设突发单次传输
DMA2_Stream3 ->CR &= ~(3<23); //存储器突发单次传输
DMA2_Stream3 ->CR |= 1<<4; //开启传输完成中断
DMA2_Stream3 ->CR |= 3<<25; //通道3
DMA2_Stream3 ->CR |= 1<<0; //使能数据流
DMA2S3_InitInterrupt();
DMA2S3_Subpriority();
}
void DMA2_Stream3_IRQHandler(void)
{
if(DMA2->LISR&(1<<27))
{
while(SPI1->CR1&(1<<6));
DMA2->LIFCR|=(1<<27);
}
if(DMA2->LISR&(1<<25))
{
}
}
核心在于这两句话
//数据流地址寄存器
//M1AR仅在双通道模式下有用
//将数据所在地址给M0AR寄存器
DMA2_Stream3 ->CR |= 1<<18; //开启双缓冲模式
DMA2_Stream3 ->CR |=(1<<19); //CT位置1写入M0
DMA2_Stream3 ->M0AR = (unsigned int)(SPIData1);
DMA2_Stream3 ->CR &=~(1<<19); //CT位置0写入M1
DMA2_Stream3 ->M1AR = (unsigned int)(SPIData2);首先是开启双缓冲模式,在CR的18位

然后是19位CT

置0时是M0AR启用,置1时是M1AR启用
除此之外我建议开启中断,开启传输完成中断,首先是SPI传输最后需要等待总线空闲与关闭SPI。此外,如果存储器地址更新时CT没变对的话会触发错误中断,这样能多一层保险。

4.测试
这里我以两组5位数据为例,循环发送这两组数据
unsigned char test_data1[5]={0xa6,0xb5,0xc1,0xfb};
unsigned char test_data2[5]={0xa7,0xb6,0xc2,0xfc};测试现场,因为SPI无需应答,所以直接挂逻辑分析仪来检测数据即可

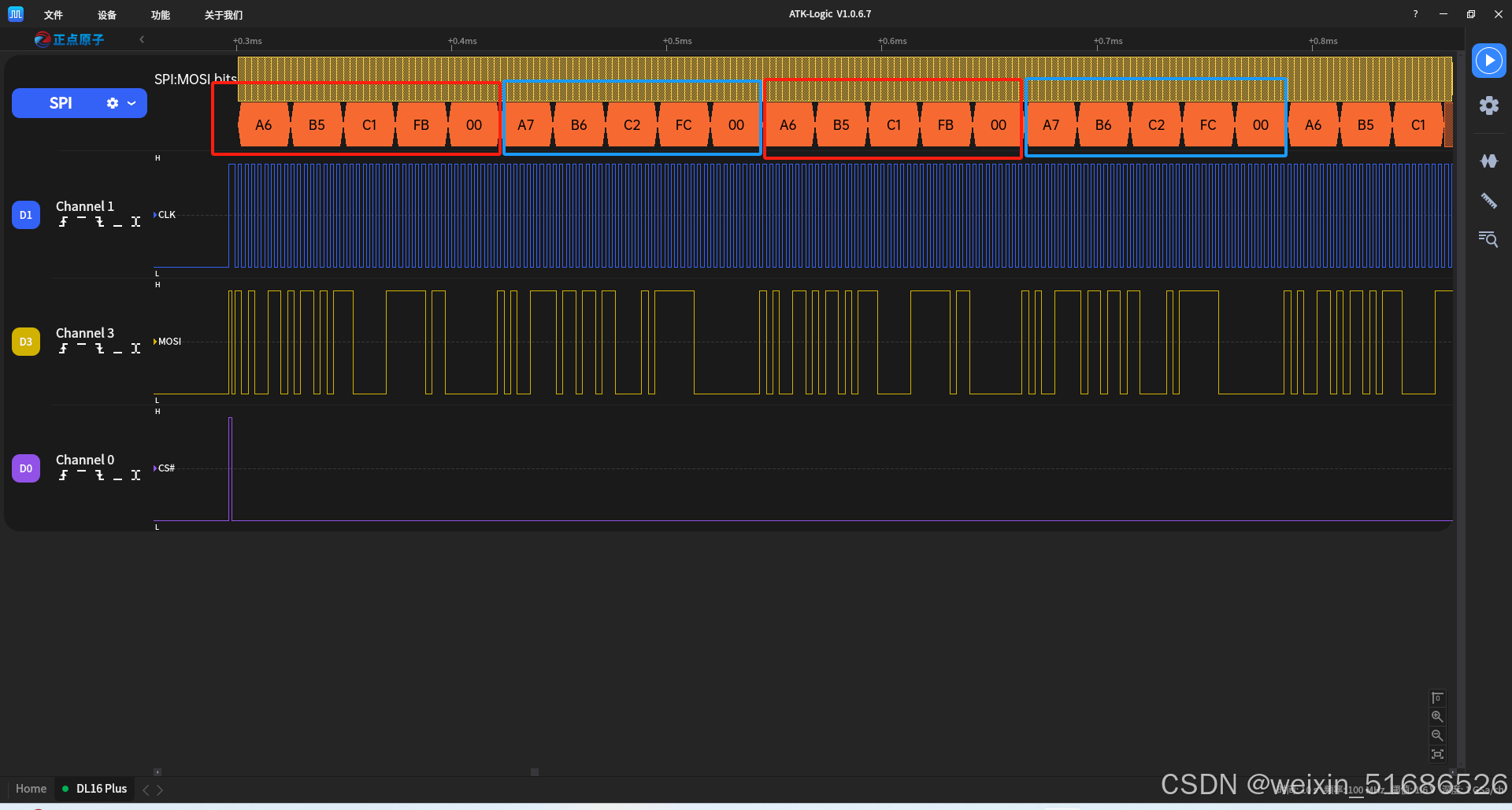
可以看到两组数据交替发送,中间没有间断,数据没有错位,非常漂亮。
5.结语
双缓冲模式几乎是以空间换时间的代表。大家如有类似的需求可以尝试一下。那么OK,还是老样子,我们下篇文章见。

















 3023
3023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









