





原文:Chen, Xinlei, Saining Xie and Kaiming He. “An Empirical Study of Training Self-Supervised Vision Transformers.” ArXiv abs/2104.02057 (2021).
源码:https://github.com/facebookresearch/moco-v3
虽然标准卷积网络的训练方法已经非常成熟和稳健,但ViT(Vision Transformer)的训练方法还没有建立起来,特别是在训练变得更具挑战性的自监督场景中。本文没有提出一种新的方法,而是研究了训练自监督ViT的几个基本组件的效果。我们观察到,不稳定性是降低精度的一个主要问题,它可以被表面上良好的结果所掩盖。我们在MoCo v3和其他几个自监督框架中对ViT进行了基准测试,并在各个方面进行了消融研究。我们希望这项工作能为未来的研究提供有用的数据和经验。
★ 背景知识
★ 模型方法

算法1:MoCo v3的伪代码。
★ 实验结果
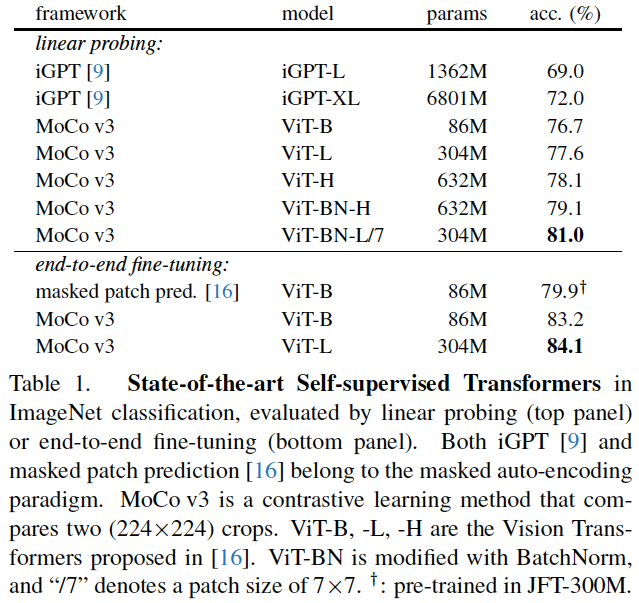
表1:ImageNet分类任务中的SOTA自监督Transformers,这里通过线性探测或端到端微调进行评估。
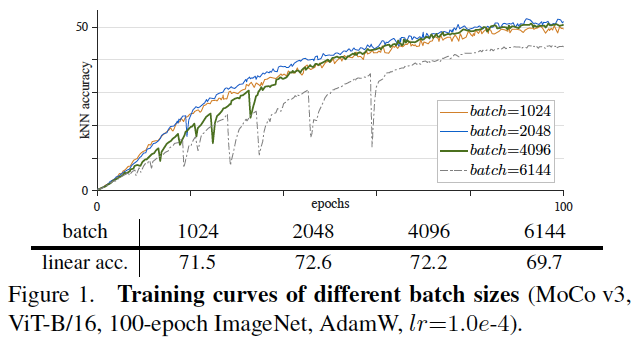
图1:不同批量大小的训练曲线(MoCo v3, ViT-B/16, 100-epoch ImageNet, AdamW, lr=1.0e-4)。
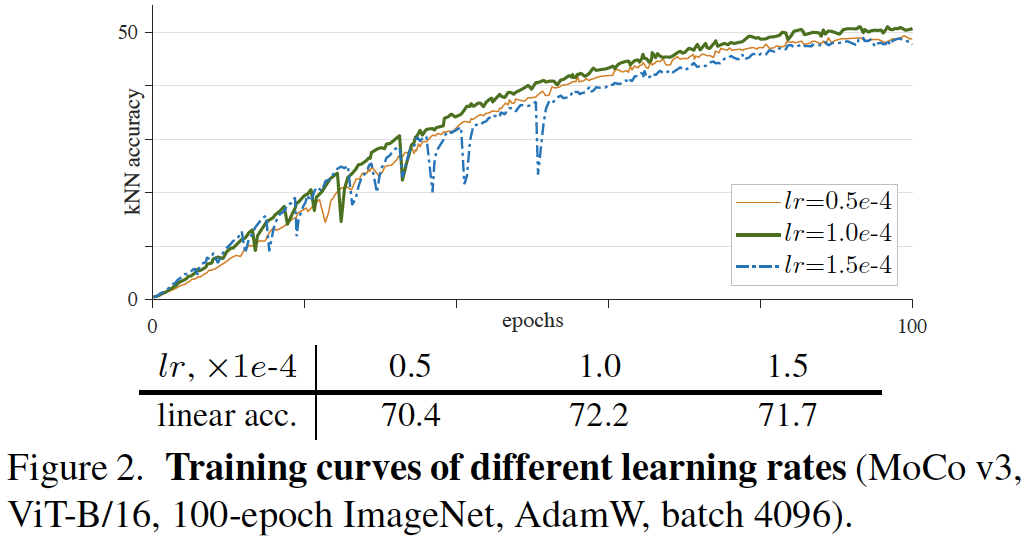
图2:不同学习率的训练曲线(MoCo v3, ViT-B/16, 100-epoch ImageNet, AdamW, batch 4096)。
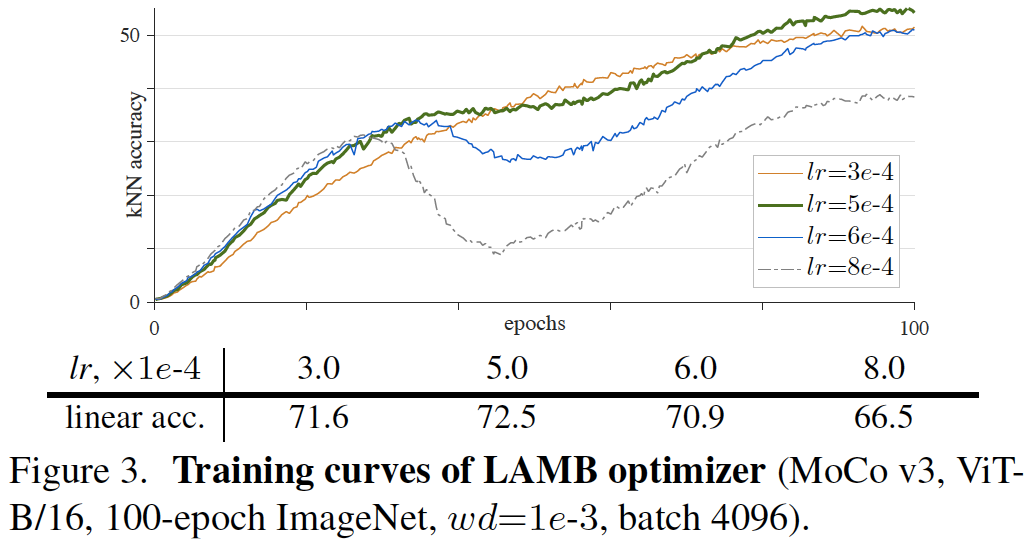
图3:LAMB优化器的训练曲线(MoCo v3, ViT-B/16, 100-epoch ImageNet, wd=1e-3, batch 4096)。
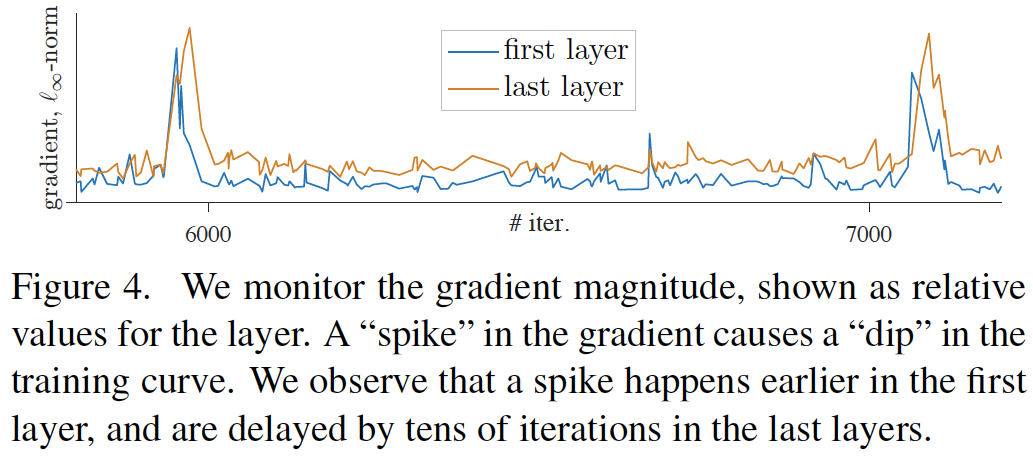
图4:我们对梯度大小进行监控,显示为该层的相对值。梯度中的“尖峰”会导致训练曲线的“下降”。我们观察到尖峰在第一层发生得更早,并且在最后一层延迟了数十次迭代。
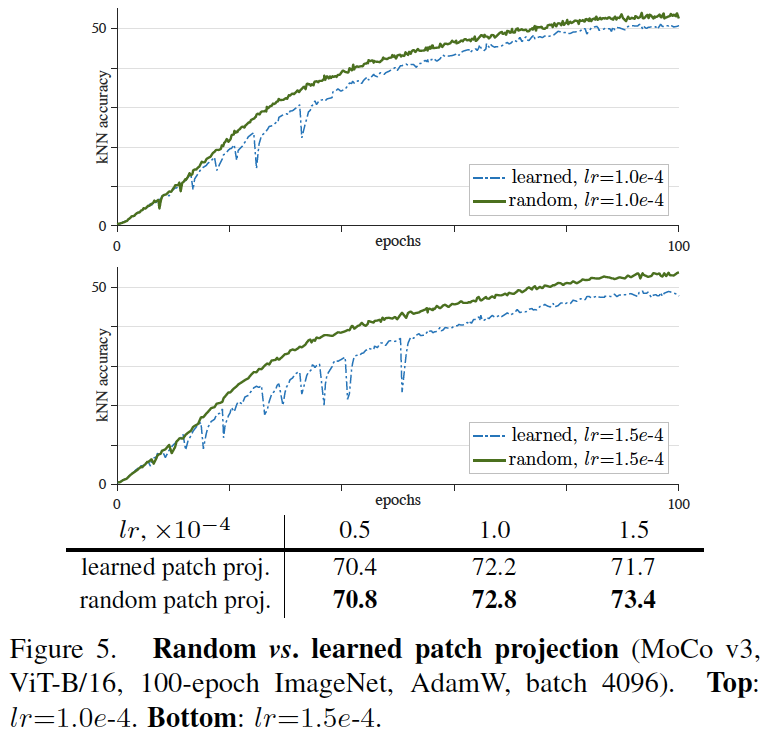
图5:随机投影与学习的投影的对比(MoCo v3, ViT-B/16, 100-epoch ImageNet, AdamW, batch 4096)。上面:lr=1.0e-4。下面:lr=1.5e-4。
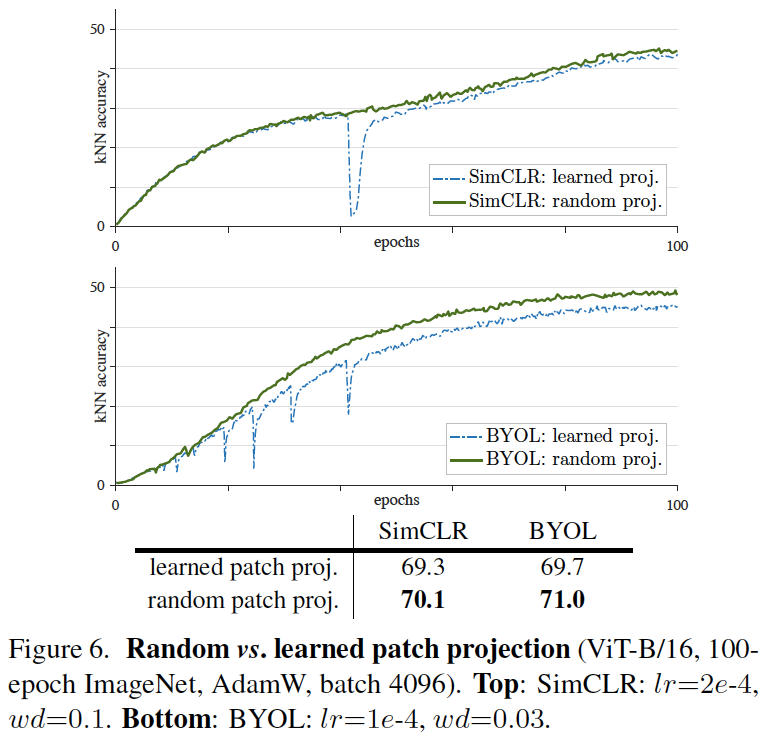
图6:随机投影与学习的投影的对比(ViT-B/16, 100-epoch ImageNet, AdamW, batch 4096)。上面:SimCLR, lr=2e-4, wd=0.1。下面:BYOL, lr=1e-4, wd=0.03。
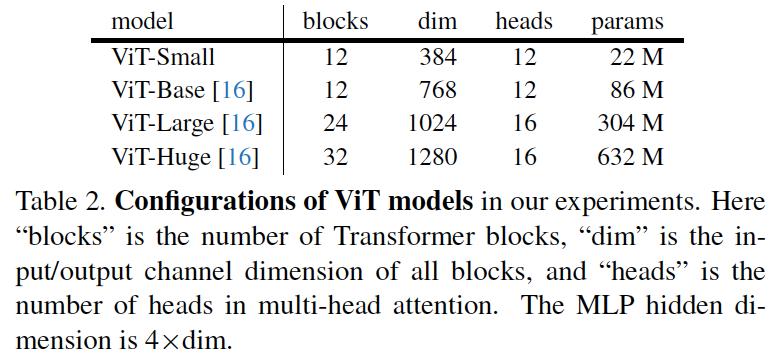
表2:实验中ViT模型的配置。这里的“blocks”是Transformer block的数量,“dim”是所有block的输入/输出通道维数,“heads”是多头注意力中head的数量。
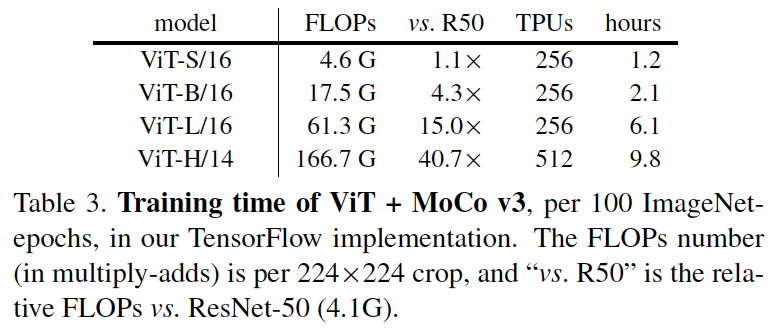
表3:基于TensorFlow实现,每100个迭代步的ViT+MoCo v3的训练时间。
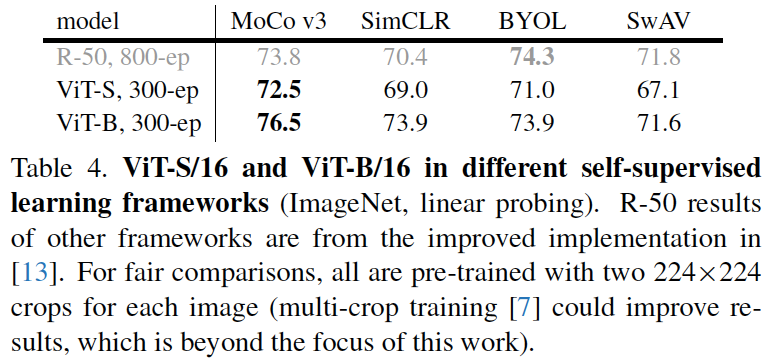
表4:ViT-S/16和ViT-B/16在不同的自监督学习框架中的性能。

图7:不同的自监督学习框架在R-50(x轴)和ViT-B(y轴)之间的表现不同(数据来自表4)。

图8:MoCo v3与SimCLR v2、BYOL性能的对比。
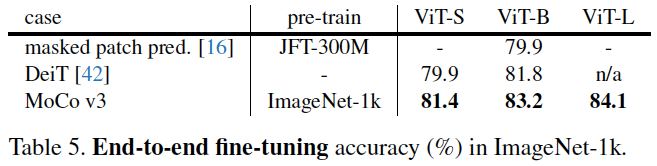
表5:不同模型在ImageNet-1k上进行端到端微调的精度。

表6:在ImageNet-1k上进行预训练,然后在四个数据集上迁移学习(端到端微调)的精度。
★ 总结讨论
我们在最近流行的自监督框架中研究了ViT的训练情况。我们围绕ViT与卷积网络、监督与自监督、对比学习与掩码自编码进行了对比研究。我们希望我们的实证研究能对社会有所帮助,以缩小视觉和语言预训练之间的差距。

多模态人工智能
为人类文明进步而努力奋斗^_^↑
50篇原创内容
欢迎关注“多模态人工智能”公众号,一起进步^_^↑

















 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









