







1. Background
- 将BERT应用到CV领域遇到的一些问题:将图片编码成向量之后不是类似语言中token的表示形式,所以无法进行预测 < m a s k > <mask> <mask>的操作。基于此,最开始在cv领域流行的对比学习模式是实例判别
- 最近半年随着VIT的发展,Constrastive Learning范式逐渐转变为Dnoise Auto-Encoding范式(类似于bert的训练方法,参考链接自动去噪编码器),因为VIT不仅可以得到token表示,还可以得到整张图片的表示
2. Recent Work
BERT+regression (*baseline)
- 问题:由于在cv中没有输出对应的词表,因此难以将输出接下游任务。
- 方法:将预测任务转变为回归任务。不去做原始的分类,而是用输出的向量直接拟合(重构)被mask的原始patch
BEIT: BERT + dVAE(*baseline)
- 问题:没有对应的词表
- 方法:构造对应的词表。通过训练好的dVAED将image patch转化为词表中的某一个token,然后再以BERT的训练方式进行训练
SiT: DAE+CL
- 在DAE的基础上加上了constrastive learning,即进行多任务训练。可以同时兼顾全局和token信息。从实验结果发现,Linear Probing和Fine-tuning都有很好的表现
MAE
- 一开始不用
<
m
a
s
k
>
<mask>
<mask>,输入直接去掉
<
m
a
s
k
>
<mask>
<mask>,只保留没有mask的patch,经过若干encoder之后再将mask加入,之后再进行解码预测mask掉的token(mask比例为75%,BERT为15%)
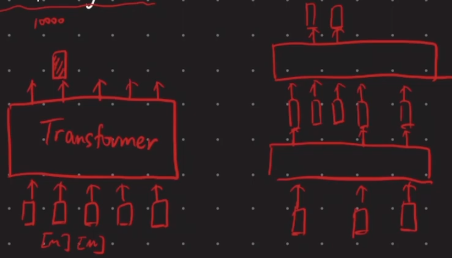
- 这种小的改动使得训练效果有很大提升,训练速度也有大幅提高。这种改进类似于nlp领域中的BART(多任务训练)
- work的原因:直观上理解是因为输入的image patch序列是在一个连续的向量空间,如果直接用 < m a s k > <mask> <mask>替换原始token,模型难以区分是patch还是mask。而经过encoder之后token都有了一定的语义(我觉得可以理解为模型对token有了一定的理解),这时再将 < m a s k > <mask> <mask>加入,模型在一定程度上能够区分mask和token。
- 有潜力!
iBOT:BERT+自蒸馏
- 传统的对比学习方法只能学习到分类头的特征(下图中绿色向量),而没有利用到其他输出的信息(下图中黄色向量)。提出使用自蒸馏的方法可以利用到所有输出的信息
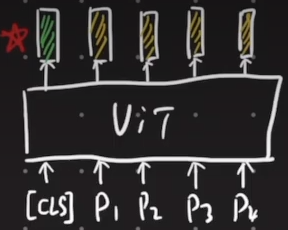
- up主认为这个方向并不是一个有潜力的方向,因为对比学习和自蒸馏都很依赖数据增强的方式
Future Direction
- predict task design
- multi-modality
- decoder application
笔记from自监督VIT进展梳理

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









