







文章目录
笔记基于以下视频P1-P9:
机器学习与深度学习:
机器学习流程:
- 数据获取
- 特征工程(关键)
- 建立模型
- 评估与应用
主要区别:
机器学习:传统的人工进行特征工程
深度学习:通过神经网络自动的进行特征提取
深度学习应用领域:
计算机视觉CV和自然语言处理NLP
机器学习常规套路:
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
KNN(最邻近结点算法)流程:
- 计算已知类别数据集中的点与当前点的距离
- 按照距离依次排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的出现概率
- 返回前K个点出现频率最高的类别作为当前点预测分类
KNN不能用来图像分类:距离为像素点对应位置相减求和,导致背景成为主导,不能识别前景(主体)
神经网络基础:
前向传播(得出损失)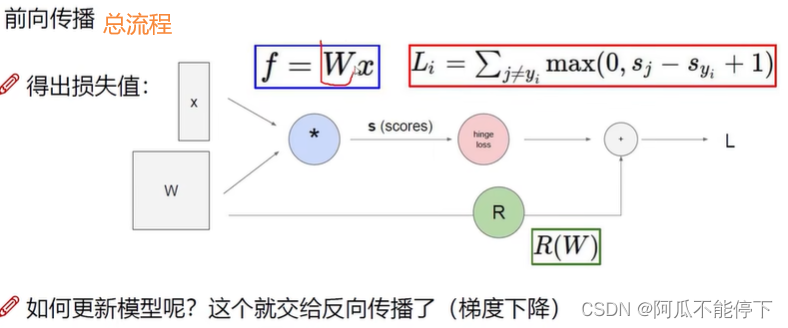
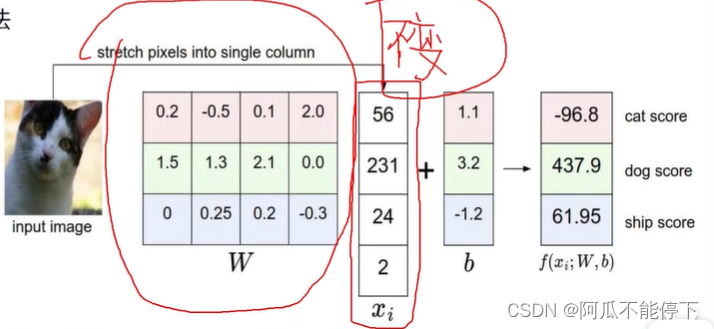
线性函数:f(x,W)=Wx+b
W:权重参数(关键)
b:偏置项
损失函数:计算预测值和真实值的差距的一类型函数

正则化惩罚项:指由权重参数带来的损失,防止过拟合

Softmax归一化指数函数:
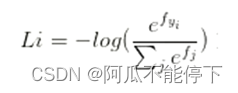
步骤:
- 指数处理:使得分区别更大,使分类效果更明显
- 归一化:将得分值映射到(0,1)之间得到概率
- 负对数函数:求损失,数值越小越好
sigmoid函数:将得分值映射到(0,1)之间
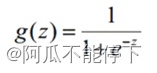
反向传播(降低损失)
反向传播计算:
过程:从后往前一步步按照链式法则求偏导。
目的:计算出W参数对于最终的损失值的重要程度。
梯度:梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值。

门单元:影响梯度分配
- 加法门单元:均匀分配,各个参数的反向传播梯度是一样的。
- Max门单元:前向传播中Max门单元将最大值传播了过去,那么反向传播,梯度只会分配给最大值
- 乘法门单元:反向传播的梯度分配是按照前向传播的参数互换后的比值来分配的















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









