






在做SOTA模型对比实验不同的模型、数据集在不同的超参数得到的结果差异较大,主要有两种设置方法:
一、直接下载别人论文的代码,然后更换为自己需要的数据集,将结果记录,作为对比算法。
二、我只取其他人论文的模型部分,然后把所有对比算法模型都放在一个框架下跑,全部设置一样的超参数等。也就是除了模型(比如ResNet、DenseNet、PresNet、YOLO等等)不一样,其它所有参数等保持一致。
以下是网上的一些看法:

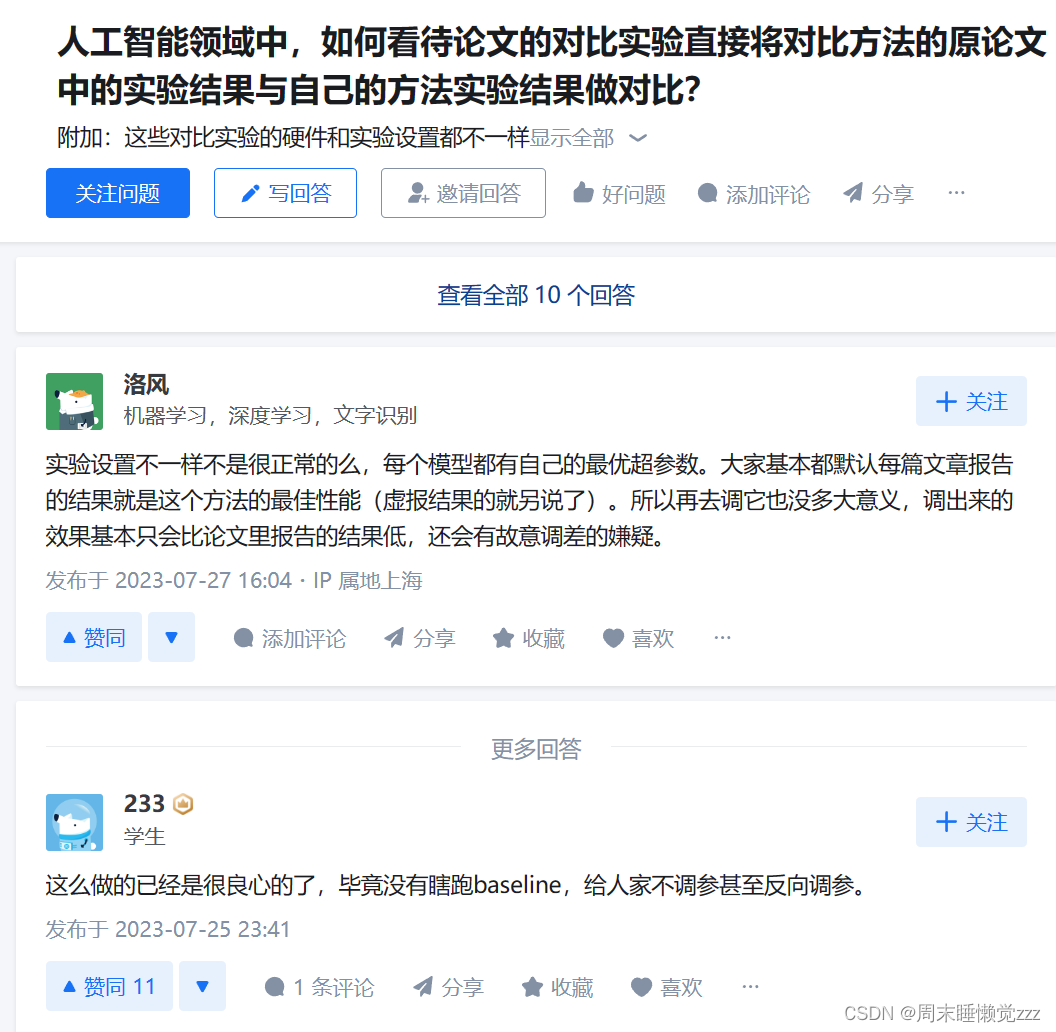

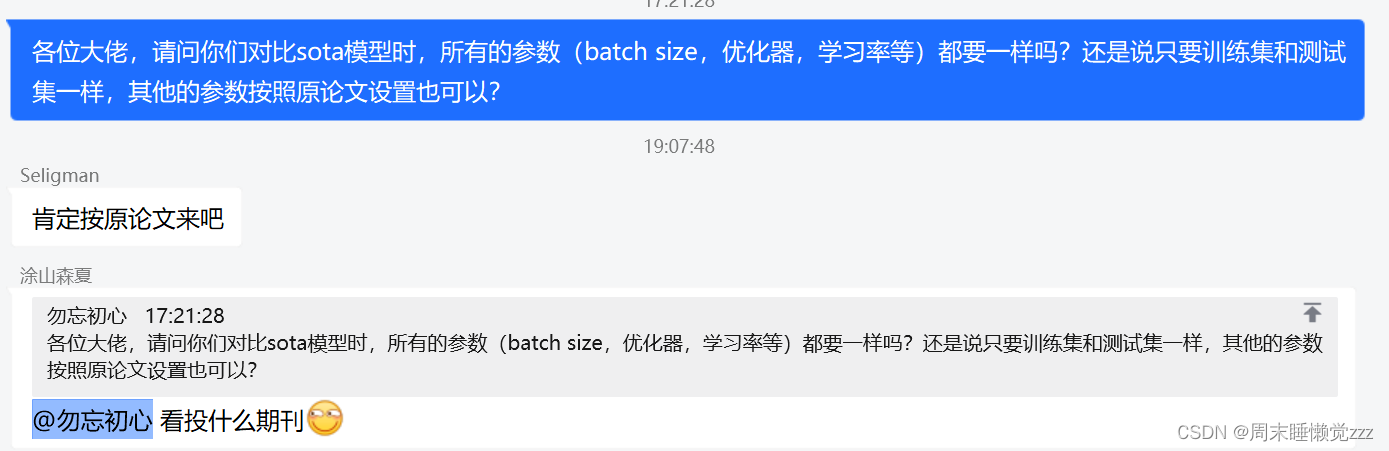
欢迎大家留言讨论论文中SOTA模型对比时超参是怎么设置的,如能附上论文举例更好😊


















 1469
1469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











