







目录
爬虫框架Scrapy简介
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 是一个功能非常强大的爬虫框架, 它不仅可以用于便捷地构建HTTP请求, 还有强
大的选择器用于快速、方便地解析和回应HTTP 响应。Scrapy 的优点可以简单概括为以下5点:
(1)Scrapy 使用TwisSted 异步网络框S架处理S网络通信, 加快了爬取数据的速度。
(2)Scrapy S具有强大的统计及日志系统, 方便查看返回内容以及统计信息。
(3)Scrapy 可同时采集多个不同网页的数据。
(4)Scrapy 支持Shell,方便独立调试。
(5)Scrapy 运用管道的方式将数据存入数据库, 操作灵活, 可以保存多种形式的数据。
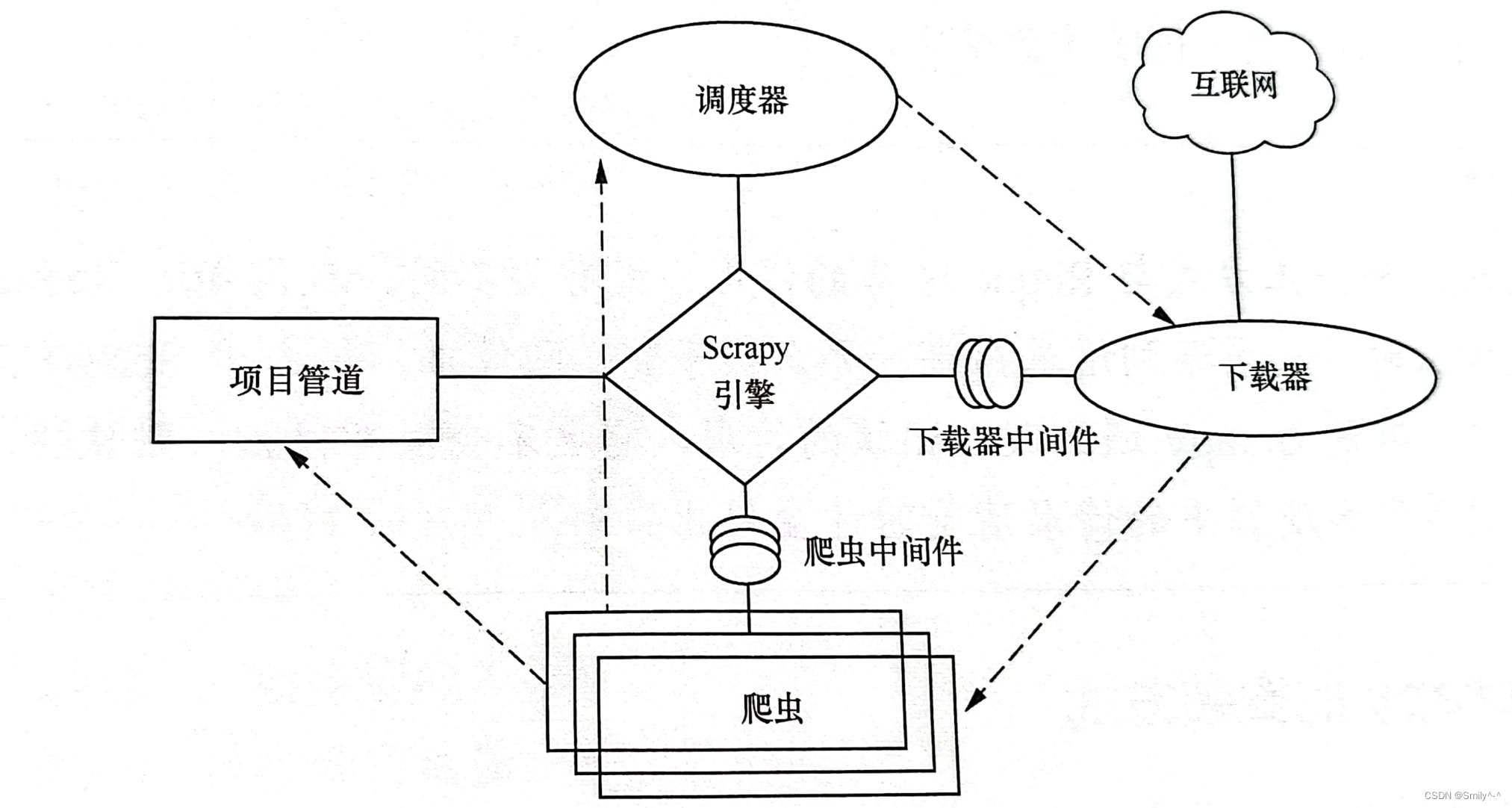
Scrapy爬取步骤
使用Scrapy进行爬取的步骤如下:
Step1:安装Scrapy
首先,安装Scrapy(此处使用conda安装,也可以使用pip);
conda install scrapyStep2:新建项目
scrapy startproject projectname
cd projectname创建的目录结构如下:
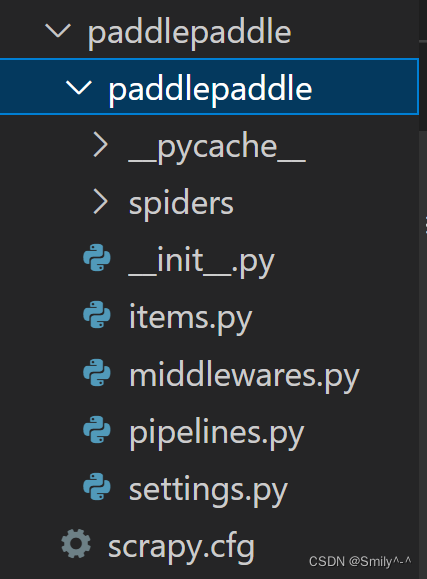
Step3:创建爬虫文件
scrapy genspider scrapytest api.github.comStep4:编写爬虫代码
以爬取PaddlePaddle/PaddleOCR项目的commmits记录为例,代码如下:
import json
import scrapy
class CommitsSpider(scrapy.Spider):
name = 'commits'
allowed_domains = ['api.github.com']
start_urls = ['https://api.github.com/repos/PaddlePaddle/PaddleOCR/commits?&page=1&per_page=100']
current_page = 1
def parse(self, response):
# 转换为python中的字典
result = json.loads(response.text)
# content_list = []
for data in result:
Author = data.get('commit').get('author')
Committer = data.get('commit').get('committer')
Message = data.get('commit').get('message')
dict = {
'Author': Author,
'Committer': Committer,
'Message': Message,
}
# scrapy.Request()
# content_list.append(dict)
yield dict
# print(content_list)
# return content_list
if result:
self.current_page += 1
next_url = "https://api.github.com/repos/PaddlePaddle/PaddleOCR/commits?&page=%d&per_page=100" % (
self.current_page)
yield scrapy.Request(url=next_url, callback=self.parse)
pass
Step5:运行爬虫项目
scrapy crawl issues -o issues.json获取到的json数据如下(可以根据需要自行筛选字段):
[{"User": "andyjpaddle", "State": "closed", "Number": 8548, "CreatedAt": "2022-12-05T11:51:45Z", "UpdatedAt": "2022-12-05T11:52:11Z", "ClosedAt": "2022-12-05T11:52:11Z", "MergedAt": "2022-12-05T11:52:11Z", "Title": "[doc] fix dead link", "Body": "cp https://github.com/PaddlePaddle/PaddleOCR/pull/8547"},
{"User": "andyjpaddle", "State": "closed", "Number": 8547, "CreatedAt": "2022-12-05T11:42:47Z", "UpdatedAt": "2022-12-05T11:53:44Z", "ClosedAt": "2022-12-05T11:53:44Z", "MergedAt": "2022-12-05T11:53:44Z", "Title": "[doc] Fix dead link", "Body": null},
{"User": "WenmuZhou", "State": "closed", "Number": 8506, "CreatedAt": "2022-12-01T06:41:18Z", "UpdatedAt": "2022-12-01T08:02:48Z", "ClosedAt": "2022-12-01T08:02:47Z", "MergedAt": "2022-12-01T08:02:47Z", "Title": "mv Polygon import into func", "Body": null},
{"User": "andyjpaddle", "State": "closed", "Number": 8500, "CreatedAt": "2022-11-30T11:40:17Z", "UpdatedAt": "2022-12-05T11:29:58Z", "ClosedAt": "2022-11-30T11:41:48Z", "MergedAt": "2022-11-30T11:41:47Z", "Title": "[doc] add en doc", "Body": "cp"},
{"User": "andyjpaddle", "State": "closed", "Number": 8497, "CreatedAt": "2022-11-30T11:20:26Z", "UpdatedAt": "2022-12-05T11:29:56Z", "ClosedAt": "2022-11-30T11:35:50Z", "MergedAt": "2022-11-30T11:35:50Z", "Title": "[doc] add finetune en doc", "Body": "add finetune en doc"},
{"User": "LDOUBLEV", "State": "closed", "Number": 8491, "CreatedAt": "2022-11-30T04:43:22Z", "UpdatedAt": "2022-11-30T04:43:34Z", "ClosedAt": "2022-11-30T04:43:34Z", "MergedAt": "2022-11-30T04:43:34Z", "Title": "[bug] fix config", "Body": null}]















 1139
1139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









