






一、介绍及原理
K近邻(K-Nearest Neighbor, KNN)是一种最经典和最简单的有监督学习方法之一。K-近邻算法是最简单的分类器,没有显式的学习过程或训练过程。
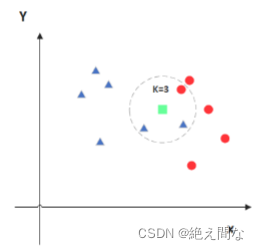
如果要判断某个数据的类型,我们可以将已知数据与要判断数据之间进行计算,列出二者之间的距离,选取K个距离最近的值,判断哪一类别的数量多,就将要判断数据定为哪种数据。(K的取值不同,判断结果不同,)
当K过小时,容易受个别值影响,当K较大时,判断结果模糊。
二、计算过程
1.计算距离
通过两点间距离公式之间进行计算
# 计算对应的距离 def distance(x, y): res = 0 for k in ("radius","texture","perimeter","area","smoothness","compactness","symmetry","fractal_dimension"): res += (float(x[k]) - float(y[k]))**2 return res ** 0.5 # 1. 计算距离 res = [ {"result":train["diagnosis_result"],"distance":distance(data,train)} for train in train_data ]
2.排序
将所有结果进行升序排列
# 2. 排序 sorted(res,key=lambda x:x["distance"]) # print(res)
3.取值
取前K个
# 3. 取前K个 res2 = res[0:K]
4.判断
进行加权计算,看哪一类别多,进行类别划分
# 4. 加权平均 result = {"B":0,"M":0} # 4.1 总距离 sum = 0 for r in res2: sum += r["distance"] # 4.2 计算权重 for r in res2 : result[r['result']] += 1-r["distance"]/sum # 4.3 得出结果 if result['B'] > result['M']: return "B" else: return "M"















 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









