






1.皮尔逊相关系数
实现原理
皮尔逊相关系数是用来衡量两个变量之间线性相关程度的统计量,记作 ,其取值范围为 [-1, 1]。公式如下:
其中:
是两个变量的观测值
是两个变量的均值
取值范围
=1:完全正相关,两个变量完全线性相关,且方向相同。
=-1:完全负相关,两个变量完全线性相关,但方向相反。
=0:不相关,两个变量没有线性关系。
计算过程
1.计算变量和
的均值
。
2.对每对观测值()计算各自与均值的差
。
3.计算这些差值的乘积之和,。
4.分别计算这些差值的平方和,。
5.最后:(步骤 3 的结果)除以(步骤 4 的结果的平方根)。
数据集
假设我们有以下数据集:
特征 a: [1, 2, 3, 4, 6, 10]
特征 b: [89, 100, 119, 150, 188, 200]
代码实现
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 数据集(有线性关系)
data = {
'a':[1, 2, 3, 4, 6, 10],
'b':[89, 100, 119, 150, 188, 200]
}
# 创建DataFrame
df = pd.DataFrame(data)
# 计算皮尔逊相关系数矩阵
corr_matrix = df.corr(method='pearson')
# 打印相关系数矩阵
print("皮尔逊相关系数矩阵:")
print(corr_matrix)
# 绘制热力图
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Correlation Matrix Heatmap')
plt.show()
运行结果
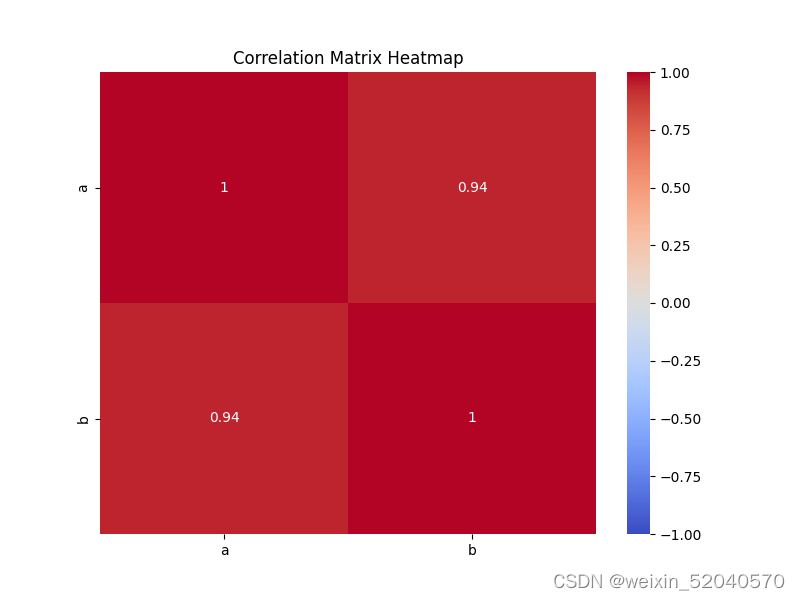
特征 a 和 b: 相关系数为 0.94,表示两者之间存在较强的正相关关系。
适用范围
1.线性关系:皮尔逊相关系数仅适用于测量两个变量之间的线性关系。如果两个变量之间存在非线性关系,皮尔逊相关系数可能无法准确反映其相关性。
2.连续变量:皮尔逊相关系数适用于连续型数据(如测量值、比率等),不适用于分类数据或秩次数据。
3.正态分布:理想情况下,变量应当服从正态分布,或者至少满足对称分布。
4.无异常值:皮尔逊相关系数对异常值非常敏感,异常值可能会显著影响相关系数的大小和方向。
2.斯皮尔曼相关系数
秩次
假设我们有一组数据,秩次就是将这些数据按大小顺序排列,并赋予每个数据点一个唯一的排序位置(即排名)。例如,如果我们有一组数据 [3,1,4,1,5],对其进行排序后得到 [1,1,3,4,5],其秩次就为 [2.5,2.5,1,3,4]。
为什么存在2.5呢?如果有相同的值(称为“平秩”),则这些值的秩次是它们排序位置的平均值。
实现原理
斯皮尔曼相关系数是衡量两个变量排序后之间相关程度的非参数统计量,记作 ,其取值范围为 [-1, 1]。公式如下:
其中:
分别是
的秩次。
是每对数据点的秩次差,即
。
是观测值的数量。
取值范围
=1:完全正相关,两个变量的排序完全一致。
=-1:完全负相关,两个变量的排序完全相反。
=0:不相关,两个变量的排序无关。
计算过程
假设我们有以下数据集:
| 86 | 92 |
| 97 | 98 |
| 85 | 96 |
| 92 | 91 |
| 99 | 100 |
1.排序并赋秩次:
| 86 | 92 | 2 | 2 |
| 97 | 98 | 4 | 4 |
| 85 | 96 | 1 | 3 |
| 92 | 91 | 3 | 1 |
| 99 | 100 | 5 | 5 |
2.计算秩次差:
| 86 | 92 | 2 | 2 | 0 | 0 |
| 97 | 98 | 4 | 4 | 0 | 0 |
| 85 | 96 | 1 | 3 | -2 | 4 |
| 92 | 91 | 3 | 1 | 2 | 4 |
| 99 | 100 | 5 | 5 | 0 | 0 |
3.计算差的平方和:
=0+0+4+4+0=8
4.代入公式:
计算得
0.6即为皮尔曼系数。
代码实现
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import spearmanr
# 生成示例数据
np.random.seed(0)
data = {
'Variable1': np.random.randint(1, 100, 50),
'Variable2': np.random.randint(1, 100, 50),
'Variable3': np.random.randint(1, 100, 50),
'Variable4': np.random.randint(1, 100, 50),
'Variable5': np.random.randint(1, 100, 50)
}
# 将数据转换为 DataFrame
df = pd.DataFrame(data)
# 计算斯皮尔曼相关系数矩阵
corr_matrix = df.corr(method='spearman')
# 创建热力图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', center=0, vmin=-1, vmax=1)
plt.title("Spearman Rank Correlation Heatmap")
plt.show()
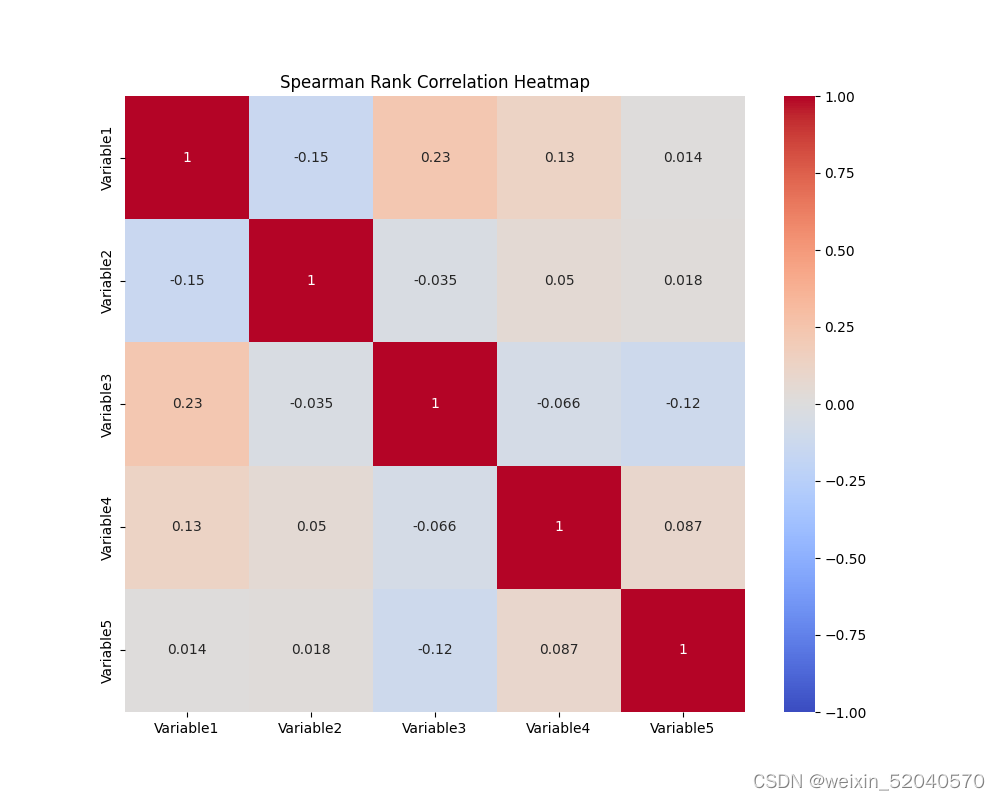
适用范围
1.单调关系:斯皮尔曼秩相关系数适用于测量两个变量之间的单调关系,无论这种关系是线性还是非线性。只要一个变量增加(或减少),另一个变量也相应增加(或减少),斯皮尔曼秩相关系数就可以有效地衡量这种关系。
2.连续或离散变量:斯皮尔曼秩相关系数适用于连续型数据和秩次数据(如等级、排名)。
3.非正态分布:斯皮尔曼秩相关系数不要求数据服从正态分布,因此适用于数据分布不明或非正态分布的情况。
4.对异常值不敏感:由于斯皮尔曼秩相关系数基于秩次而非具体数值,它对异常值不太敏感。
3.机器学习应用
皮尔逊相关系数的应用
特征选择:线性回归:在构建线性回归模型时,皮尔逊相关系数可以帮助识别与目标变量高度线性相关的特征。这有助于去除冗余特征并提高模型性能。降维:在高维数据中,皮尔逊相关系数可 以用来识别和移除高度相关的特征对,从而减少特征空间的维度。
多元线性回归:预测建模:在多元线性回归中,皮尔逊相关系数可以用于评估每个独立变量与目标变量之间的线性关系,从而选择最相关的特征用于建模。
协同过滤推荐系统:用户相似度计算:在基于用户的协同过滤推荐系统中,皮尔逊相关系数可以用来计算用户之间的相似度。例如,Netflix和亚马逊等平台可以使用皮尔逊相关系数来推荐用户可能喜欢的电影或商品。
时间序列分析:交叉相关性:在时间序列分析中,皮尔逊相关系数可以用于计算两个时间序列之间的相关性,以识别潜在的时序关系。
斯皮尔曼秩相关系数的应用
特征选择:非线性关系的识别:在构建机器学习模型时,斯皮尔曼秩相关系数可以帮助识别与目标变量存在单调关系的特征,即使这种关系不是线性的。例如,在决策树和随机森林等非线性模型中,斯皮尔曼秩相关系数可以用于判断特征的重要性。
异常检测:鲁棒性分析:由于斯皮尔曼秩相关系数对异常值不敏感,它可以用于检测数据集中存在的异常模式。例如,在金融数据分析中,斯皮尔曼秩相关系数可以用来识别异常交易行为。
分类问题:秩次特征的使用:在分类任务中,斯皮尔曼秩相关系数可以用于处理秩次特征,例如排名数据。它可以帮助识别特征与类别标签之间的单调关系。
生物信息学:基因表达分析:在生物信息学中,斯皮尔曼秩相关系数可以用于分析基因表达数据,识别基因之间的关联关系。对于理解基因调控网络和发现潜在的生物标记具有重要意义。
金融分析:股票回报分析:在金融市场中,斯皮尔曼秩相关系数可以用来分析不同股票的回报率之间的相关性,尤其是在市场波动较大或存在异常值的情况下。

















 2661
2661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









