






论文标题:Residual Local Feature Network for Efficient Super-Resolution
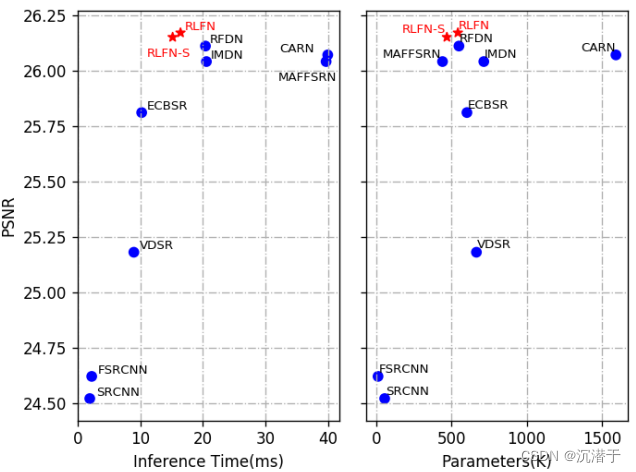
摘要:基于深度学习的方法在单幅图像超分辨率(SISR)中取得了很好的效果。然而,高效超分辨率的最新进展主要集中在减少参数数量和FLOPs(每秒所执行的浮点运算次数,用来衡量计算机的计算能力以及模型的复杂度),并通过复杂的层连接策略提高特征利用率来聚合更强大的特征。这些结构可能不是实现更高运行速度所必需的,这使得它们难以部署到资源受限的设备上。本文提出了一种新的残差局部特征网络(RLFN)。主要思想是使用三层卷积进行残差局部特征学习,简化特征聚合,在模型性能和推理时间之间实现了很好的权衡。此外,我们回顾了流行的对比损失,并观察到其特征提取器的中间特征的选择对性能有很大影响。此外,我们还提出了一种新的多阶段暖启动训练策略。在每个阶段,利用前几个阶段的预训练权值来提高模型的性能。结合改进的对比损失和训练策略,所提出的RLFN在运行时间方面优于所有最先进的高效图像SR模型,同时保持SR的PSNR和SSIM。此外,我们还获得了NTIRE 2022高效超分辨率挑战赛运行赛道第一名。代码将在github上提供。
图像修复领域最具影响力的国际顶级赛事——New Trends in Image Restoration and Enhancement(NTIRE)
1. 引言
很多技术被提出用于开发高效的图像超分辨模型:一类是采用权值共享策略的递归网络,这样的模型并没有从本质上减少操作的数量和推理的时间;一类采用深度卷积、特征分割、洗牌等操作,单这些操作无法保证提高计算效率。
最近的一些研究[45,48]表明,更少的参数和FLOPs并不总是带来更好的模型效率,运行时间通常是实际应用中最重要的因素。
为此,我们重新审视了当前最先进的高效SR模型RFDN(Residual Feature Distillation Network for Lightweight Image Super-Resolution)[31],并试图在重建图像质量和推理时间之间实现更好的权衡。首先,我们重新思考了RFDN提出的残差特征蒸馏块的若干组成部分的效率。我们观察到,虽然特征蒸馏显著减少了参数的数量并有助于整体性能,但它对硬件不够友好,并且限制了RFDN的推理速度。为了提高其效率,我们提出了一种新的残余局部特征网络(RLFN),可以减少网络碎片并保持模型容量。
为了进一步提高其性能,我们建议采用对比损耗[44,46]。我们注意到其特征提取器的中间特征的选择对性能有很大的影响。我们对中间特征的性质进行了全面的研究,并得出结论,浅层特征保留了更准确的细节和纹理,这对面向psnr的模型至关重要。在此基础上,我们构建了一个改进的特征提取器,可以有效地提取边缘和细节。
为了加快模型收敛速度,提高最终SR恢复精度,提出了一种新的多阶段热启动训练策略。具体来说,在每个阶段,SR模型都可以享受到之前所有阶段模型的预训练权值的好处。
结合改进的对比损失和提出的预热启动训练策略,RLFN达到了最先进的性能,并保持了良好的推理速度。
我们的贡献总结如下:
1.本文对RFDN(残差特征蒸馏网络)的效率进行了反思,并对其速度瓶颈进行了研究。我们提出了一种新的网络,称为残差局部特征网络,它在不牺牲SR恢复精度的情况下,成功地提高了模型的紧凑性和加速了推理。
2.对对比损失特征提取器提取的中间特征进行分析。我们观察到浅层特征对于面向psnr的模型至关重要,这激发了我们提出一种新的特征提取器来提取更多的边缘和纹理信息。
3.我们提出了多阶段暖启动训练策略。它可以利用之前阶段的训练权重来提高SR性能。
2. 相关工作
2.1 高效图像超分辨率
2.2 面向PSNR的SISR训练策略
良好的预测结果来自于架构、训练数据和优化策略的组合优化。以往关于SISR的研究主要集中在网络架构优化方面[2,18,23,29,48],而协同训练策略对性能的重要性却很少被探讨。这些SR网络通常由ADAM优化器训练,数百个epoch的标准L1损失。为了提高训练的鲁棒性,它们通常采用较小的学习率和patch大小。先进的训练策略可以使旧的网络架构达到或超过新架构的性能。采用l2损耗对网络进行微调和用预训练的2x模型初始化4x SR模型都能有效地提高PSNR。RRCAN[30]重新审视了流行的RCAN模型,并证明增加训练迭代可以明显提高模型性能。
3. 方法
3.1 网络结构
我们的RLFN主要由三部分组成:第一部分特征提取卷积、多个堆叠残差局部特征块(rlfb)和重构模块。
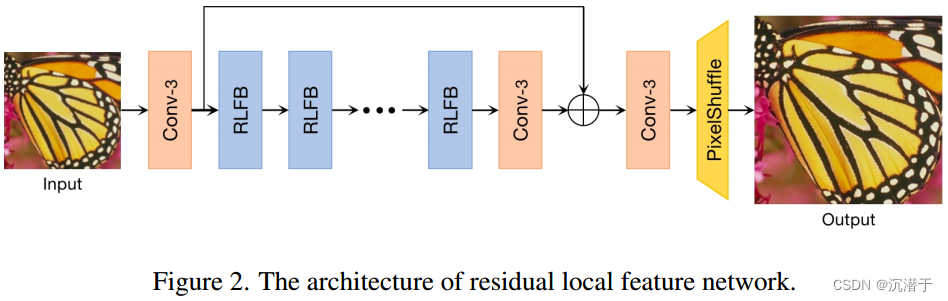
重新思考RFDB(残差特征蒸馏模块):我们重新思考RFDN提出的剩余特征蒸馏块(RFDB)的效率。RFDB在开始时采用渐进式特征细化和蒸馏策略,然后使用1 × 1卷积进行信道缩减。最后,采用增强空间注意(enhanced spatial attention, ESA)层和残差连接。
具体来说,特征细化和蒸馏管道包含几个步骤。在每个阶段,RFDB采用一个由一个浅层残差块[32](SRB)组成的细化模块对提取的特征进行细化,并使用一个蒸馏模块(单个1 × 1卷积层)对特征进行提取。这里我们分别用RM和DM表示精馏和蒸馏模块。
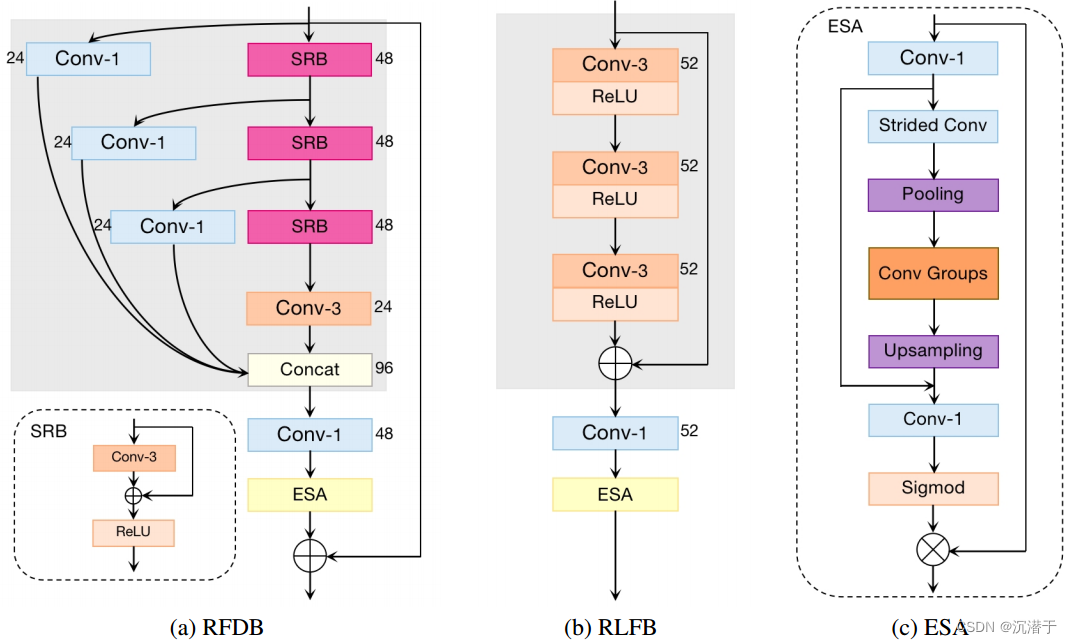
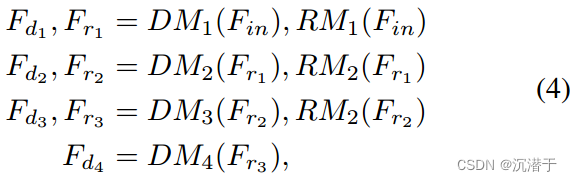
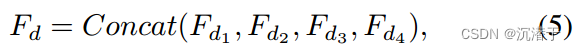
RFDB模块包含渐进式特征细化、多个特征蒸馏。通过多个1 × 1卷积操作实现的特征蒸馏连接以及串联操作可以显着减少参数数量并提高恢复性能。
RLFB在RFDB上进行了进一步地改进,删除了分层蒸馏连接,并创建了RFDB的两个变体。
RLFB(Residual Local Feature Block):提出的RLFB丢弃了多个特征蒸馏连接,仅使用少量堆叠的CONV+RELU层进行局部特征提取。特别是,RLFB中的每个特征细化模块包含一个3 × 3卷积层,然后是一个ReLU激活函数层。
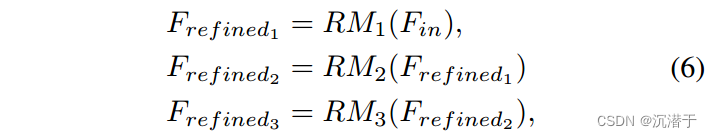
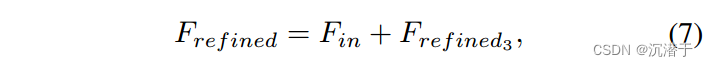
3.2 重新审视对比损失
对比学习在自监督学习中表现出色。其基本思想是将积极因素推向锚点,并将消极因素推向潜在空间的锚点。
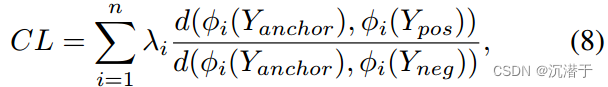
来自深层的特征可以在真实感知质量方面提高性能,因为它提供了更多的语义指导。来自浅层的特征保留了更准确的细节和纹理,这对于面向psnr的模型至关重要。这表明我们应该利用浅层特征来提高训练模型的PSNR。
3.3 暖启动训练策略
对于SR任务中的3或4等大规模因子,以前的一些作品[31]使用2x模型作为预训练网络,而不是从头开始训练。2x模型提供了良好的初始化权重,加快了收敛速度,提高了最终性能。然而,由于预训练模型和目标模型的尺度因子不同,我们只能享受一次收益。
我们采用一种新的暖启动训练策略,在第一阶段,我们从头开始训练RLFN,在下一阶段我们不再从头训练,而是加载上一阶段RLFN的权重。在训练配置如批量大小和学习率,采用和第一阶段相同的训练配置。
4.实验
5.结论
在本文中,我们提出了一种残差局部特征网络用于高效的SISR。通过减少层数和简化层与层之间的连接,我们的网络变得更轻更快。然后,我们重新审视对比损失的使用,改变特征提取器的结构,重新选择对比损失使用的中间特征。我们还提出了一种有利于轻量化SR模型训练的热启动策略。大量的实验表明,我们的整体方案,包括模型结构和训练方法,达到了质量和推理速度的良好平衡。
6.自我总结
1. 深层特征可以提高真实感知质量的性能,提供更多的语义信息;而浅层的特征保留了更多的细节和纹理,这对于提高模型的PSNR是至关重要的。或许可以通过获取更多的浅层特征来提高面向PSNR的模型。
2.先进的训练策略可以使旧的网络结构达到或超过新架构的性能。















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









