




文本建模PLSA与LDA模型 – 潘登同学的Machine Learning笔记
文章目录
文本生成过程
一篇文档,可以看成是一组有序的词的序列 d = ( w 1 , w 2 , … , w n ) d=(w_1,w_2,\ldots,w_n) d=(w1,w2,…,wn) . 从统计学角度来看,文档的生成可以看成是上帝抛掷骰子生成的结果,每一次抛掷骰子都生成一个词汇,抛掷N词生成一篇文档。在统计文本建模中,我们希望猜测出上帝是如何玩这个游戏的,这会涉及到两个最核心的问题:
- 上帝都有什么样的骰子;
- 上帝是如何抛掷这些骰子的;
第一个问题就是表示模型中都有哪些参数,骰子的每一个面的概率都对应于模型中的参数;第二个问题就表示游戏规则是什么,上帝可能有各种不同类型的骰子,上帝可以按照一定的规则抛掷这些骰子从而产生词序列。
Unigram Model
在Unigram Model中,我们采用词袋模型,假设了文档之间相互独立,文档中的词汇之间相互独立。假设我们的词典中一共有 V 个词 v 1 , v 2 , … , v V v_1,v_2,\ldots,v_V v1,v2,…,vV ,那么最简单的 Unigram Model 就是认为上帝是按照如下的游戏规则产生文本的。
- 上帝只有一个骰子,这个骰子有V面,每个面对应一个词,各个面的概率不一;
- 每抛掷一次骰子,抛出的面就对应的产生一个词;如果一篇文档中N个词,就独立的抛掷n次骰子产生n个词;
n-gram model
对于n-gram model来说就是Unigram Model加了一个假设,假设当前词会受前n个词的影响,于是就用条件概率来生成词,那么n-gram model就是认为上帝是按照如下的游戏规则产生文本的。
- 上帝只有 C V n C_V^n CVn个骰子,这个骰子有V面,每个面对应一个词,各个面的概率不一;
- 每抛掷一次骰子,抛出的面就对应的产生一个词;这个骰子会根据前n次抛掷的情况选择,这样N次,生成一篇文章
PLSA模型(Probabilistic latent semantic analysis)
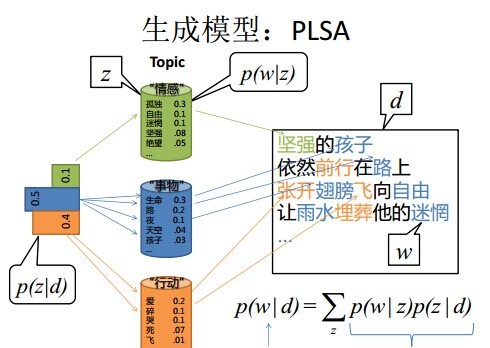
Unigram Model模型中,没有考虑主题词这个概念。我们人写文章时,写的文章都是关于某一个主题的,不是满天胡乱的写,比如一个财经记者写一篇报道,那么这篇文章大部分都是关于财经主题的,当然,也有很少一部分词汇会涉及到其他主题。所以,PLSA认为生成一篇文档的生成过程如下:
- 现有两种类型的骰子,一种是doc-topic骰子,每个doc-topic骰子有K个面,每个面一个topic的编号;一种是topic-word骰子,每个topic-word骰子有V个面,每个面对应一个词;
- 现有K个topic-word骰子,每个骰子有一个编号,编号从1到K;
- 生成每篇文档之前,先为这篇文章制造一个特定的doc-topic骰子,重复如下过程生成文档中的词:
3.1 投掷这个doc-topic骰子,得到一个topic编号z;
3.2 选择K个topic-word骰子中编号为z的那个,投掷这个骰子,得到一个词;

LDA 模型
生成文档步骤
- 按照先验概率 p ( d i ) p(d_i) p(di)选择一篇文档 d i d_i di
- 从Dirichlet分布 α \alpha α中取样生成文档 d i d_i di的主题分布 θ i \theta_i θi,主题分布 θ i \theta_i θi由参数为 α \alpha α的Dirichlet分布生成
- 从主题的多项式分布 θ i \theta_i θi中取样生成文档 d i d_i di第 j 个词的主题 z i , j z_{i,j} zi,j
- 从Dirichlet分布 β \beta β中取样生成主题 z i , j z_{i,j} zi,j对应的词语分布 ϕ z i , j \phi_{z_{i,j}} ϕzi,j,词语分布 ϕ z i , j \phi_{z_{i,j}} ϕzi,j由参数为 β \beta β的Dirichlet分布生成
- 从词语的多项式分布 ϕ z i , j \phi_{z_{i,j}} ϕzi,j中采样最终生成词语 w i , z w_{i,z} wi,z

下图可以加深对上面的理解

为什么要选择这些分布
为什么选择狄利克雷(Dirichlet)分布作为先验分布,因为待估计的总体分布是多项分布,将先验分布选择为狄利克雷(Dirichlet)分布,那么后验分布也就是狄利克雷(Dirichlet)分布,在做极大似然时候就方便计算;这里的重要概念是共轭先验分布; 共轭先验分布在数量统计里面讲过,对于一个共轭先验分布用简单的数学表达就是
P
(
θ
∣
x
)
=
P
(
θ
,
x
)
P
(
x
)
,
其
中
P
(
θ
∣
x
)
、
P
(
θ
,
x
)
都
服
从
同
一
分
布
(
可
能
参
数
不
同
)
P(\theta|x) = \frac{P(\theta,x)}{P(x)},其中P(\theta|x)、P(\theta,x)都服从同一分布(可能参数不同)
P(θ∣x)=P(x)P(θ,x),其中P(θ∣x)、P(θ,x)都服从同一分布(可能参数不同)
下图通过概率图的形式描述了这一过程
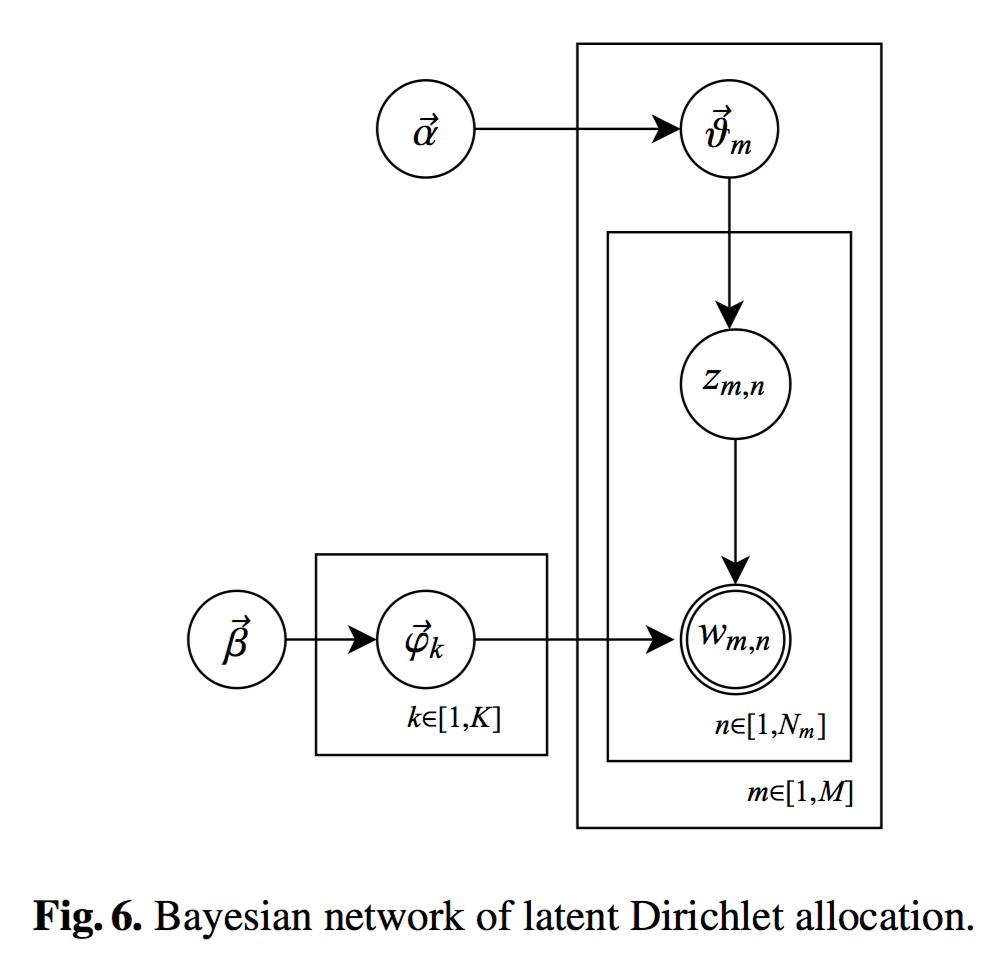
其中 θ ⃗ m 与 ϕ ⃗ k \vec{\theta}_m与\vec{\phi}_k θm与ϕk是模型去估计总体的参数,而 α ⃗ 与 β ⃗ \vec{\alpha}与\vec{\beta} α与β是这些待估参数的先验分布,通过最大后验概率来估计总体参数…
Python实现
文本预处理-分词

LDA分析

结果展现


主题数目选择–困惑度
主题数目肯定是越多越好,但是越多就说明泛化能力不强,所以根据elbow原则选择主题数目

源码请移步至我的github中获取,因为代码实现难免会有bug,github中记录了常见的bug及解决方案…




















 1321
1321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











