







Word2Vec进阶 - GPT2 – 潘登同学的NLP笔记
文章目录
GPT2网络结构
Bert是用了Transformer的Encoder层,而GPT2则是采用了Transformer的Decoder层,最大的模型采用了48层decoder

预训练任务
机器翻译
进行翻译时,模型不需要Encoder。同样的任务可以通过一个只有Decoder的 transformer 来解决:

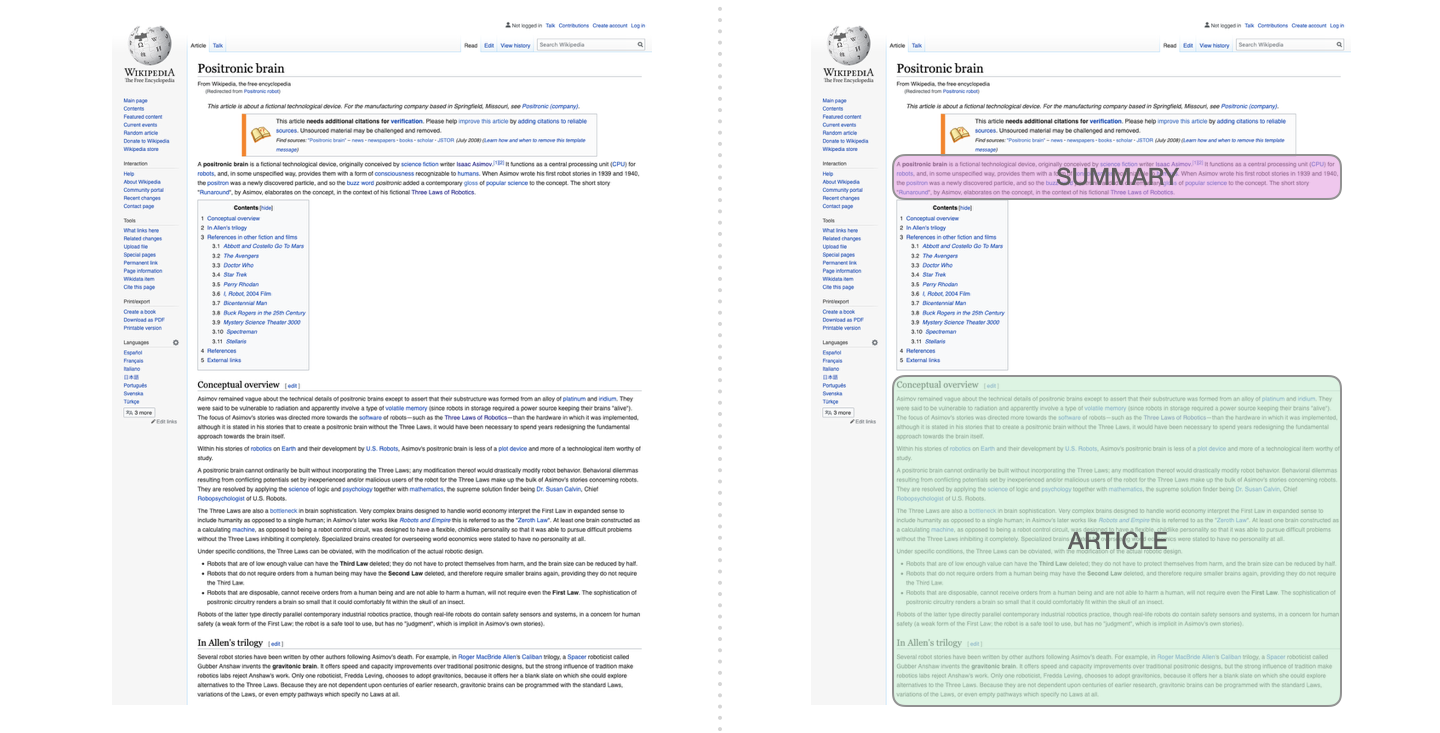
自动摘要生成
这是第一个训练只包含解码器的 transformer 的任务。也就是说,该模型被训练来阅读维基百科的文章(没有目录前的开头部分),然后生成摘要。文章实际的开头部分被用作训练数据集的标签,论文使用维基百科的文章对模型进行了训练,训练好的模型能够生成文章的摘要:
阅读理解
给出一段内容,给出question,最后写一个Answer的起始符,将回答作为label

Zero-shot,One-shot,Few-shot
首先解释下什么是Zero-shot、One-shot、Few-shot,其实就是小样本学习
- Zero-shot就是现在你要做一个具体任务,如英语转成法语,但是你没有labeled数据来训练模型;
- One-shot就是你只有一条英语到法语的labeled数据;
- Few-shot就是有10-1K条的labeled数据
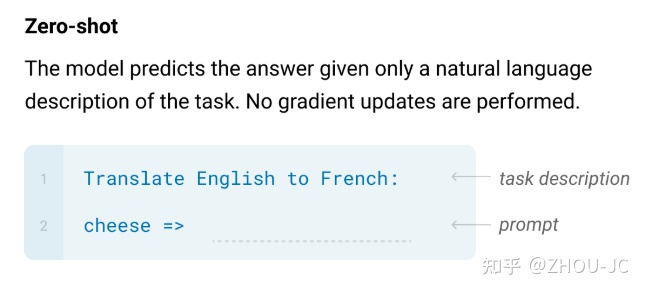
Zero-shot
应用到英语翻译法语任务,首先给一句话描述任务是英翻法,然后给待翻译的英语,最后通过语言模型的方法生成对应的法文,如下图
One-shot
One-shot场景相对于Zero-shot场景多了一条labeled数据,按理来说,多了一条labeled数据,模型的效果应该会更好

这里再把语言模型类比成一个博览群书的人,虽然这个人很厉害,但你给他一些具体任务让他解决时,他还是会蒙蔽,例如我现在叫这个人做一个情感分析的任务,输入"请给下面影评做情感分析,判断正面还是负面:这个电影有点冗长,但是画面还是不错的,属于__"。这个人是蒙的,即使他博览群书,但他不知道评价标准,这句话即有正面的因素,也有负面的因素,究竟是分到正面还是负面好?但这时候,你给任务的时候,顺便给多一个参考案例,输入变成“请给下面影评做情感分析,判断正面正面还是负面:这个电影剧情很差,幸好选的演员把电影撑起来了,属于正面。这个电影有点冗长,但是画面还是不错的,属于__” ,这时候,这个博览群书的人就知道该把这个样本分到正面了。
Few-shot
Few-shot,就是给多几个案例,如下图

问题来了
为什么GPT2能通过只学习语言模型(就是自监督学习),学到这些根本就没有样本的任务呢?GPT2、GPT3论文观点是只要训练语料足够大、足够丰富,模型参数足够多,模型能学习到如最常见的词法、语义、指代消解、角色标注,甚至一些具体的任务,如情感分析、阅读理解、对话、翻译等具体任务,是的,没看错,意思是,即使不做下游任务的fine funing,语言模型在预训练的时候就能学到这些能力。虽然有一些是通过隐式学习到的。
只要语料足够丰富,模型就能可能学习到英语-中文、西班牙语-德文、韩语-日文等等等等的互译技能。
但是你说他的效果怎么样,肯定不能直接应用下游任务,肯定要进行fine-tune…
Bert与GPT2的区别
你说他的效果怎么样,肯定不能直接应用下游任务,肯定要进行fine-tune…
Bert与GPT2的区别

















 6557
6557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











