









目录
一、算法研究背景
随着互联网的发展,越来越多的中文文本数据被创建和共享,例如社交媒体、电子邮件、新闻报道等。为了从这些数据中获取有用的信息,需要将它们进行分类和归纳。分类算法是机器学习领域中的一类算法,可以将数据自动分类为不同的类别。在中文文本分类任务中,这些类别可能是不同的主题、情感或语言风格等。中文文本分类可以应用于许多应用领域,如情感分析、垃圾邮件过滤、新闻推荐、搜索引擎优化等。因此,研究中文文本分类算法已成为机器学习和自然语言处理领域的热门研究方向之一。
二、Scikit-Learn机器学习库的介绍
Scikit-Learn是一个流行的Python机器学习库,包含了许多用于分类、回归、聚类、降维和模型选择等任务的算法和工具。Scikit-Learn具有易于使用、高效和可扩展的特点,是许多机器学习项目中的重要组件。
以下是Scikit-Learn库的一些主要特点:
- 一致的API:Scikit-Learn的API设计一致性很高,可以方便地使用和组合不同的算法和工具。
- 内置算法:Scikit-Learn包含了许多内置的分类、回归和聚类算法,可以轻松地应用于不同的数据集。
- 数据预处理:Scikit-Learn提供了多种数据预处理方法,包括缺失值填充、特征标准化、特征选择等。
- 可视化工具:Scikit-Learn还提供了多种可视化工具,可以帮助用户更好地理解和分析数据。
- 并行化支持:Scikit-Learn可以通过并行化加速计算过程,提高处理大规模数据集的效率。
- 社区支持:Scikit-Learn拥有一个庞大的社区,提供了许多教程、例子和帮助文档,方便用户学习和使用。
总之,Scikit-Learn是一个强大而易于使用的机器学习工具,可以帮助用户更快速、更准确地处理各种机器学习问题
注:本文章中的数据集来自网上开源的一些语料库,欢迎学习使用,请勿用于商业行为;本文的数据集包括整个分类算法的完整实现代码的仓库链接都会在本文末尾给出。
三、不同算法实现的效果对比以及选择最优的算法
1、不同算法的实现效果对比
(1) 数据预处理
在文本分类任务中,数据预处理是非常重要的步骤。数据预处理是指在将文本输入模型之前,对文本数据进行一系列的操作和转换,以提高分类算法的准确性和性能。下面是一些数据预处理的主要目的:
- 文本清洗:文本数据中可能包含标点符号、特殊字符、数字、停用词等不必要的信息,需要将它们去除,保留有意义的文本内容。
- 分词:将文本按照一定的规则分割成单词或短语,以便后续的特征提取。
- 去除停用词:停用词是指在文本中频繁出现但通常不包含有意义信息的单词或短语,例如“的”、“和”、“在”等。去除停用词可以减少特征空间的大小,提高分类算法的效率和准确性。
- 词干提取和词形还原:由于同一个单词可能存在不同的变体形式,例如时态、单复数等,需要将它们还原为它们的词干或原型形式,以减少特征空间的大小,提高模型的性能。
- 特征提取:从文本中提取有用的特征表示文本内容,例如词袋模型、TF-IDF权重、n-gram等。
- 数据转换:将文本数据转换为模型可以接受的数据格式,例如将文本转换为稀疏矩阵。
通过数据预处理,可以有效地减少特征空间的大小,提高模型的性能和准确性。
在本文中所使用的数据集(语料库)已经是初步处理过的了,不需要我们从收集数据开始做,已经形成了比较好的格式。
这里先给出训练模型在初始化的时候所定义的变量:
def __init__(self, filepath):
"""
:param filepath: 数据集路路径
"""
self.filepath = filepath
self.sentenceID_categoryName = {} # 文本ID和分类名的映射
self.categoryID_categoryName = {} # 分类ID和分类名的映射
self.categoryID = [] # 分类ID和文本的映射
self.sentence = [] # 分类ID和文本的映射
self.training_text = None # 训练集文本
self.training_labels = None # 训练集标签
self.test_text = None # 测试集文本
self.test_labels = None # 测试机标签
self.predit = None # 测试预测结果接下来我们开始数据的初始化处理,主要是统计记录一下后面要用到的数据以及对所有目标文本进行分词去停用词,还有就是删除一些冗余的符号:
def preparement(self):
"""
:return: 无,数据的预处理
"""
with open(self.filepath, 'r', encoding='UTF-8') as f:
article = f.readlines()
stopwords = self.load_stopwords()
for line in article:
line_list = line.replace(' ', '').replace('\n', '').split('_!_')
self.sentenceID_categoryName[line_list[0]] = line_list[2] # 记录每条文本ID和分类名的对应关系
if line_list[1] not in self.categoryID_categoryName: # 记录分类ID和分类名之间的对应关系
self.categoryID_categoryName[line_list[1]] = line_list[2]
self.categoryID.append(line_list[1]) # 记录每行文本的对应ID
sentence = ''
rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]") # 利用正则过滤掉每行文本中除了汉字、字母、数字之外的符号
for i in range(3, len(line_list)):
sentence += rule.sub('', line_list[i])
words = self.remove_stopwords(jieba.cut(sentence), stopwords) # 去停用词
self.sentence.append(words) # 记录经过处理之后的每行文本通用词加载的调用的方法:
@staticmethod
def load_stopwords():
"""
:return: 加载好的停用词列表
"""
with open('../hit_stopwords.txt', 'r', encoding='UTF-8') as f:
lines = f.readlines()
stopwords = []
for line in lines:
stopwords.append(line.replace('\n', ''))
return stopwords去停用词调用的方法:
在这之后就是对处理之后的文本进行特征词向量化处理,返回的是向量化之后的特征集以及每一条文本对应的标签集:
def tdf_idf(self):
"""
:return: 返回整个数据集特征向量化后的结果,对每行预处理之后的文本选出特征并做向量化
"""
# 为保证特征的丰富性和训练的效果,除了分词之后的每个单独的字词用作特征外,还将相邻的两个词组用作特征
tfidf = TfidfVectorizer(norm='l2', ngram_range=(1, 2))
return tfidf.fit_transform(self.sentence), self.categoryID(2) 划分数据集
在数据预处理之后,就开始划分训练集和测试集,这里我们是采用八比二的比例来划分的,如果你的数据集足够大的时候也可以采用九比一或者更大的比例来划分:
def divide_dataset(self, features, labels):
"""
:param features: 向量化后的特征集
:param labels: 特征集对应的分类标签集
:return:
"""
self.training_text, self.test_text, self.training_labels, self.test_labels = train_test_split(
features, labels, test_size=0.2) # 按八比二划分训练集和测试集(3) 算法模型训练
这里我们先使用多个算法模型来训练这个训练集,本文使用的是Scikit-Learn库中现成的算法模型,一般除了学习一个新的算法的时候建议自己去敲一敲算法,或者要发SCI或者一些比较权威的文章的时候自己需要去写出一些新的东西,其他时候直接用现成的就好,因为一般来说,你自己实现的算法,一般都比现有的跑得慢很多。
这里我们主要验证了随机森林、线性分类支持向量机、多项式朴素贝叶斯、以及逻辑回归这四种算法,还有就是因为特征的维度过高(读者可以自行使用降维的算法,应该可以把这里的训练速度提升不少)这个模型对比还是需要跑蛮久的,大概几十分钟(主要是随机森林和逻辑回归跑得比较久,而且随机森林最后的效果也很差):
def model_option(self): # 多种模型测试验证
models = [
RandomForestClassifier(n_estimators=100, max_depth=3, random_state=0), # 随机森林
LinearSVC(), # 支持向量机——线性分类
MultinomialNB(), # 多项式朴素贝叶斯
LogisticRegression(solver='liblinear', random_state=0) # 逻辑回归
]
entries = []
for model in models:
model_name = model.__class__.__name__ # 获取当前模型的名字
print(model_name)
# 计算每种模型的精确度
accuracies = cross_val_score(model, self.training_text, self.training_labels, scoring='accuracy', cv=10)
for fold_idx, accuracy in enumerate(accuracies):
entries.append((model_name, fold_idx, accuracy))
cv_df = pd.DataFrame(entries, columns=['model_name', 'fold_idx', 'accuracy'])
# 构建一幅箱线图来对比各个模型的效果
sns.boxplot(x='model_name', y='accuracy', data=cv_df)
sns.stripplot(x='model_name', y='accuracy', data=cv_df,
size=8, jitter=True, edgecolor="gray", linewidth=2)
plt.show()
print(cv_df.groupby('model_name').accuracy.mean())注:这里我们在训练数据的时候使用了交叉验证来辅助,关于交叉验证的原理,读者可自行在网上查阅相关资料,这个点其实还是挺重要的在机器学习里面。
(4) 运行结果以及对比图
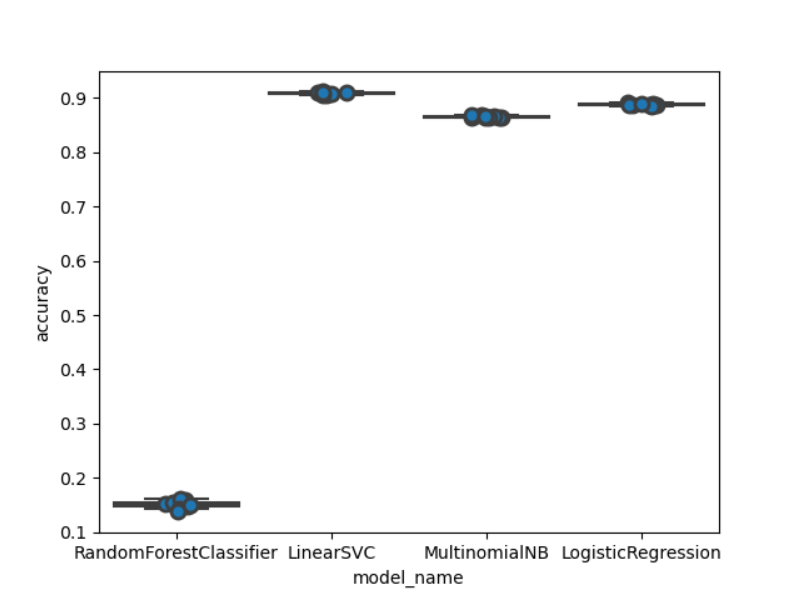
从上图我们可以看出随机森林的效果最差,而其他三种的效果相对较好并且几乎不分上下,线性分类支持向量机的效果是最好的看起来。
具体的精准度数据如下:
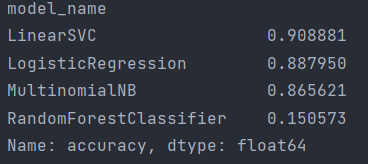
2、使用线性分类支持向量机来具体训练测试这个数据集
从上面的多个模型算法的运行结果我们可以看出线性分类支持向量机的效果是最好的,所以我们在这里对它进行一次单独的测试,由于上面已经进行了数据预处理、特征向量化、划分数据集等操作了,这里我们直接开始使用线性分类支持向量机来训练我们的数据,LinearSVC跑起来就快多了,训练测试一共跑了两分多钟。
(1) 训练数据集
def model_training(self):
"""
:return: 无,使用支持向量机模型LinearSVC()进行模型训练
"""
model = LinearSVC()
model.fit(self.training_text, self.training_labels) # 线性拟合
return model(2) 测试数据集
训练完之后我们用我们分出来的测试数据集来对我们训练处的模型做一个测试,看看效果怎么样:
def model_predit(self, model):
self.predit = model.predict(self.test_text)
conf_mat = confusion_matrix(self.test_labels, self.predit)
_, _ = plt.subplots(figsize=(15, 12))
self.categoryID_categoryName = dict(sorted(self.categoryID_categoryName.items(), key=operator.itemgetter(0)))
sns.heatmap(conf_mat, annot=True, fmt='d', xticklabels=self.categoryID_categoryName.values(),
yticklabels=self.categoryID_categoryName.values()) # 模型的混淆矩阵构建
plt.ylabel('实际结果', fontsize=18)
plt.xlabel('预测结果', fontsize=18)
plt.show()
print(self.predit.shape[0]) # 测试用例的数量
print('accuracy %s' % accuracy_score(self.predit, self.test_labels)) # 精确度
# 输出模型评估报告
print(classification_report(self.test_labels, self.predit, target_names=self.categoryID_categoryName.keys()))(3) 运行结果分析
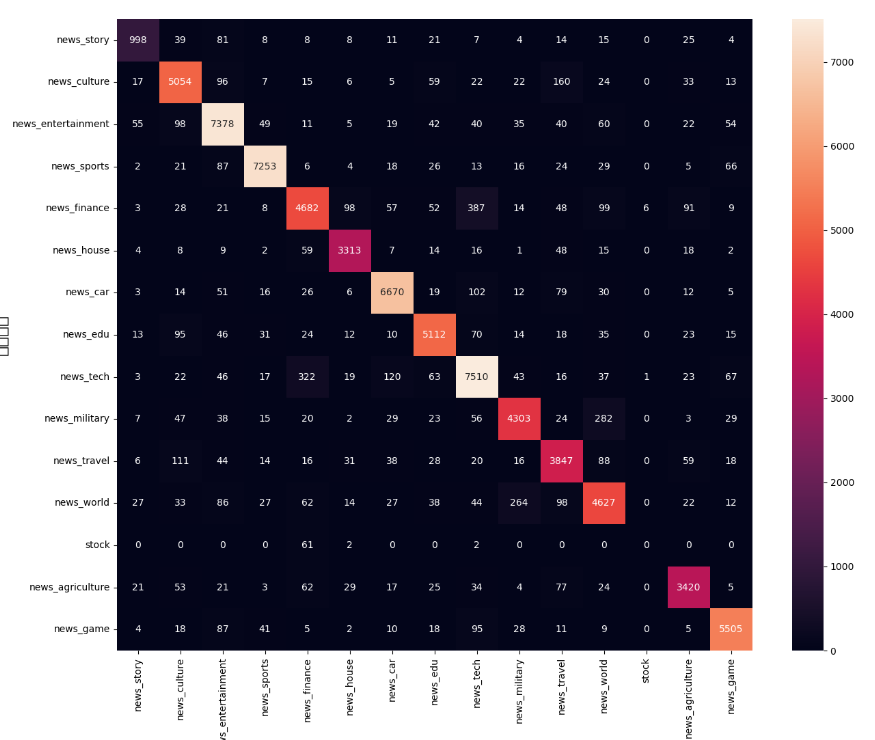
从混淆矩阵来看效果还不错,stock分类出现这么大的偏差的,应该是训练数据过少导致的,但模型的总体效果还不错。
下面是模型评估报告的具体的信息(第一列是我的分类标签和上面的混淆矩阵的行列标签一一对应):
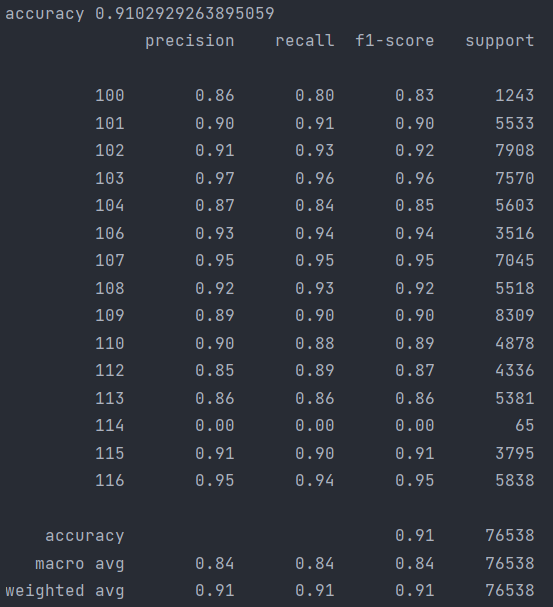
从上面评估报告来看,效果还挺好的,不过应该可以通过调整模型的超参数来达到更好的效果,本文在这里就不多做叙述了,感兴趣的读者可以去自行去调整模型超参数,多次训练来观测效果。
本文的算法实现的仓库如下:
MachineLearning/SVC at master · XSJWF/MachineLearning · GitHub
访问不了GitHub的读者也可以访问下面这个链接(都是我的仓库,我有空的时候都会做一些算法实现的样例分享,虽然现在才开始做还在复习考研哈哈哈哈哈!):
https://gitee.com/DaiYongle/MachineLearning/tree/master/SVC
本篇文章到此结束,感谢各位读者的阅读!
















 1704
1704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











