









Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy【时序异常检测】
原文地址
Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy
背景
时序异常检测的关键是学习时间序列的表征并找到一种对异常点和正常点具有辨别性的评估指标。
现有的方法通过学习 pointwise representation 或者 pairwise association 来推导出可以区分正常与异常点的准则。缺点是两类方法都不适用于推导具有复杂的动态变化的时间序列的区分准则。
现有相关的异常检测方法主要有两类:
① 一种通过重建或者自回归任务来自监督学习 pointwise representations。缺点是逐点计算误差导致无法提供对时间序列的全面描述。
② 另一种方法是通过 “explicit association modeling(显示关联建模)” 。比如,将时间序列的不同时间点表示为一张图的顶点,随后通过随机游走检测异常。缺点是图仍然局限于单个时间点,无法捕获每个时间点与整个序列的细粒度时间关联。
根据作者的观察,由于异常点十分稀有,所以在异常点与整个时间序列之间建立强关联十分困难,且异常点的关联主要集中在与其相邻的时间点上(这种邻接集中偏差被称为prior-association)。也就是说,关联的标准在异常点与正常点之间有一定区别。通过量化prior-association(我认为它代表局部的信息)以及series-association(即temporal association,单个时间点与整个序列的关联,可以表示出时间序列的变化趋势,也许带着预测的性质?)之间的距离可以得到Association Discrepancy(关联差异) 。
异常点的Association Discrepancy(关联差异) 要 小于 正常点的。
主要思想
- 设计一种Anomaly Transformer with an Anomaly-Attention mechanism来量化prior-association以及series-association,并得到Association Discrepancy。
- 随后利用minimax strategy来放大Association Discrepancy,以更好区分异常点与正常点。
模型设计
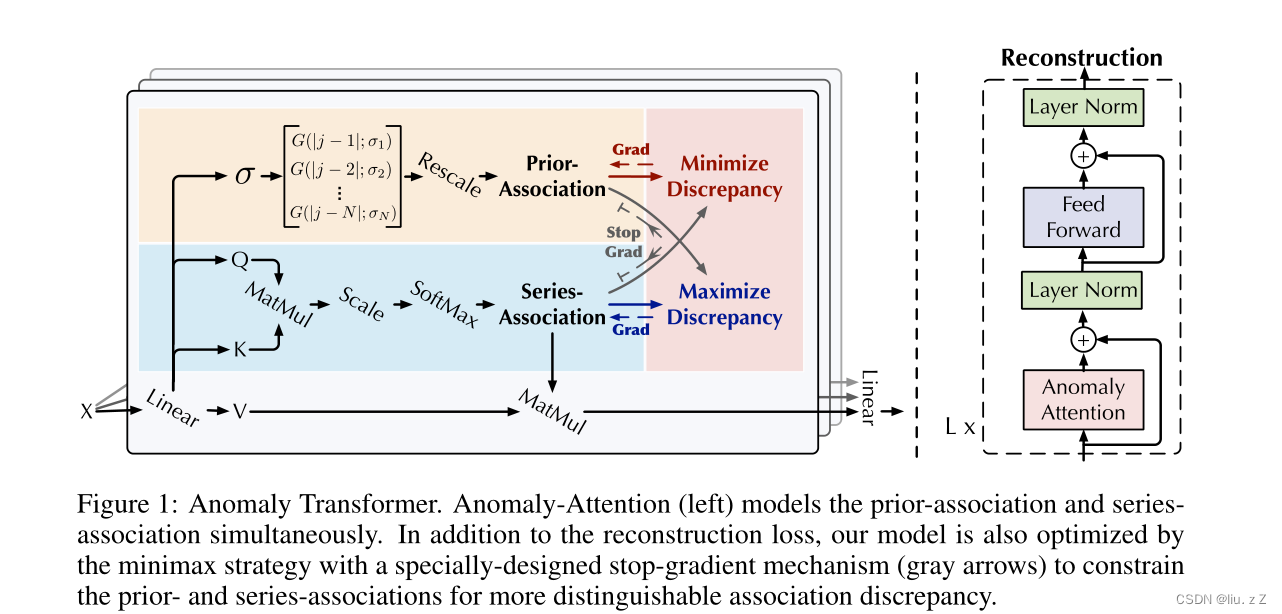
这个模型本质上是对transformer进行了一定的改进,基本结构与transformer类似(figure 1 的右图)。第
l
l
l-th层的输出如下,其中Anomaly-Attention(·)用于计算association discrepancy。

主要改进集中在左图(Anomaly Attention)。
Q
,
K
,
V
∈
R
N
×
d
m
o
d
e
l
Q,K,V \in \mathbb{R}^{N×d_{model}}
Q,K,V∈RN×dmodel都是通过原始数据经过线性变换得来,与transformer类似。
σ
∈
R
N
×
1
\sigma \in \mathbb{R}^{N×1}
σ∈RN×1也是通过原始数据经过线性变换得来。
Anomaly Attention第
l
l
l-th层计算方式如下。
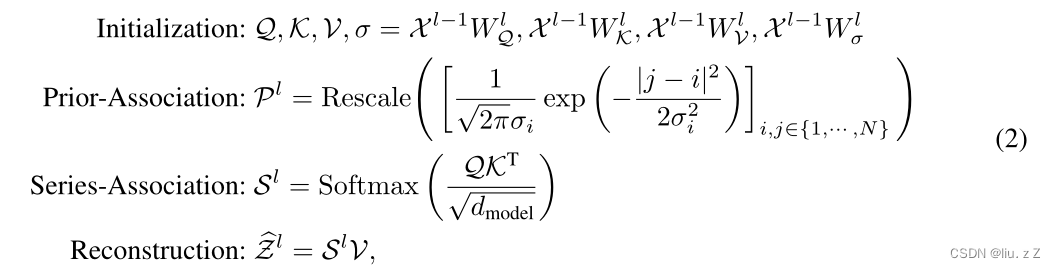
Association Discrepancy
得到prior-association与series-association后,利用了symmetrized KL散度计算分布差异,即association discrepancy。每个时间点对应一个值,异常数据相比正常数据AssDis的值会较小。
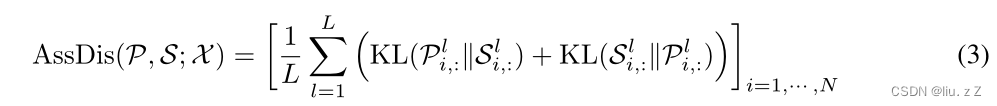
Minimax association learning
本文除了重构损失,还定义了另一个损失(关联损失)去放大异常点与正常点的差异。
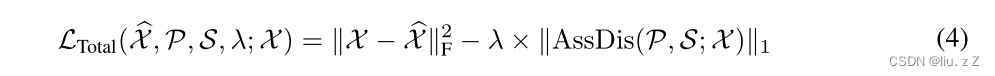
∣
∣
X
−
X
^
∣
∣
F
2
||\mathcal{X}-\mathcal{\hat X}||^2_F
∣∣X−X^∣∣F2指重构损失,后面的
λ
×
∣
∣
\lambda × ||
λ×∣∣AssDis
(
P
,
S
;
X
)
∣
∣
k
(\mathcal{P,S;X})||_k
(P,S;X)∣∣k采用Minimax strategy来进行优化(如下)。
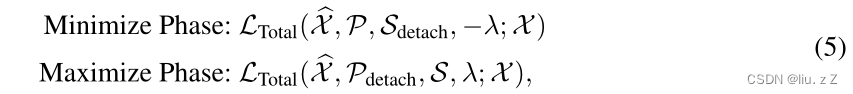
AnomalyScore异常分数的定义
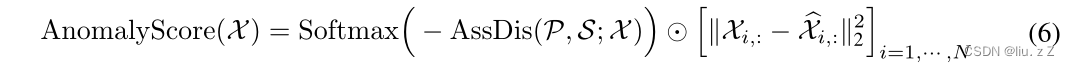
异常点的association discrepancy较小,所以经过Softmax
(
−
(-
(−AssDis
(
P
,
S
;
X
)
)
(\mathcal{P,S;X}))
(P,S;X))后,分数是偏高的。















 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









