







机器学习中的回归模型:线性回归与多项式回归的解析与应用
回归分析是监督学习中的核心问题之一,尤其在预测连续值的场景中尤为重要。本文深入探讨线性回归与多项式回归的应用,辅以详尽的Python代码示例,带领读者理解并实现这两类回归模型,并介绍如何优化模型的表现。
📚 目录
- 🌟 线性回归的基本原理与应用
- 🔢 多项式回归的扩展与实现
- 🛠 线性回归与多项式回归的Python代码示例
- 📊 回归模型评估与误差分析
- 🚀 高级应用:回归模型的扩展与优化
🌟 1. 线性回归的基本原理与应用
线性回归是最简单的回归模型之一,适用于自变量和因变量之间存在线性关系的数据。其目标是找到一个最佳拟合直线,使预测值与真实值之间的误差最小。
线性回归模型的数学表达
线性回归模型可以表示为:

该模型通过最小化预测值与实际值之间的误差来估计系数 ( \beta )。最常用的方法是 最小二乘法,即最小化以下代价函数:

应用场景
线性回归在许多应用场景中都有使用,特别是在预测或分析线性关系数据的场景下。例如:
- 房价预测:根据房屋面积、位置等特征来预测房价。
- 股票市场:分析股价与经济指标之间的线性关系。
- 医学研究:分析治疗方案与病人康复时间之间的关系。
Python 实现线性回归
在Python中,我们可以使用scikit-learn库快速构建线性回归模型。下面给出了一个简单的代码示例,展示如何构建并训练线性回归模型。
# 导入必要的库
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 创建简单的线性数据集
X = np.array([[1], [2], [3], [4], [5]]) # 特征变量
y = np.array([2, 4, 5, 4, 5]) # 目标变量
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 输出均方误差和R^2得分
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R-squared: {r2}")
# 打印回归系数和截距
print(f"Coefficients: {model.coef_}")
print(f"Intercept: {model.intercept_}")
代码解析
LinearRegression():创建线性回归模型。fit():训练模型,输入特征变量和目标变量。predict():根据测试集特征变量进行预测。mean_squared_error和r2_score:分别计算模型的均方误差和决定系数 ( R^2 )。
通过这种方式,可以快速构建线性回归模型并评估其性能。
🔢 2. 多项式回归的扩展与实现
当自变量与因变量之间的关系不是线性时,线性回归无法很好地拟合数据。这时,多项式回归可以作为一种扩展。它通过引入自变量的高次项,使模型可以拟合复杂的非线性数据。
多项式回归的数学表达
多项式回归可以表示为:
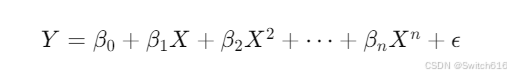
与线性回归类似,但特征是原始自变量的幂次项,这样可以使模型拟合曲线而非直线。
应用场景
多项式回归通常用于以下场景:
- 经济模型:如某些经济指标的非线性增长或衰退。
- 生物学:如药物剂量与药效反应的非线性关系。
- 工程领域:如材料性能与应力之间的非线性关系。
Python 实现多项式回归
在Python中,sklearn提供了PolynomialFeatures类,用于将特征进行多项式扩展,下面是具体的代码实现。
# 导入必要的库
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
# 生成简单的非线性数据集
X = np.array([[1], [2], [3], [4], [5]]) # 特征变量
y = np.array([1.5, 4.2, 7.5, 13.5, 19.2]) # 目标变量,具有非线性关系
# 创建二次多项式特征
poly = PolynomialFeatures(degree=2)
# 使用线性回归拟合多项式特征
model = make_pipeline(poly, LinearRegression())
# 训练模型
model.fit(X, y)
# 进行预测
y_pred = model.predict(X)
# 打印预测结果
print(f"Predictions: {y_pred}")
# 评估模型
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R-squared: {r2}")
代码解析
PolynomialFeatures(degree=2):创建二次多项式特征。make_pipeline():构建管道,先进行特征变换再拟合线性模型。fit()和predict():分别进行模型训练和预测。- 通过多项式回归,模型可以拟合更复杂的非线性数据。
🛠 3. 线性回归与多项式回归的Python代码示例
在这一部分,将展示如何将线性回归和多项式回归应用到实际数据集上,包括波士顿房价数据集。通过这些代码示例,展示两种回归模型在不同场景中的实际应用。
线性回归模型在波士顿房价数据集上的应用
波士顿房价数据集是一个经典的数据集,包含多个房屋相关的特征和目标房价。通过线性回归模型,可以预测房价。
# 导入必要的库
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
boston = load_boston()
X = boston.data # 特征变量
y = boston.target # 目标变量
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 输出均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
多项式回归在波士顿房价数据集上的应用
在某些情况下,线性回归可能无法很好地拟合数据,我们可以使用多项式回归来拟合更复杂的关系。
# 导入必要的库
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
# 创建三次多项式回
归模型
poly = PolynomialFeatures(degree=3)
model = make_pipeline(poly, LinearRegression())
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 输出均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error (Polynomial): {mse}")
通过这段代码,多项式回归可以更好地拟合复杂的数据,提高模型的表现。
📊 4. 回归模型评估与误差分析
回归模型的评估通常通过以下几种指标进行:
- 均方误差 (MSE):预测值与实际值之间的平方差的平均值,反映模型误差大小。
- 均方根误差 (RMSE):均方误差的平方根,更直观地反映了预测误差。
- 决定系数 (R^2):衡量模型解释自变量的能力,越接近1,模型越好。
# 计算均方误差和决定系数
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R-squared: {r2}")
这些指标可以帮助我们量化模型的性能。
🚀 5. 高级应用:回归模型的扩展与优化
为了提升模型的表现,可以采用以下优化手段:
- 正则化:通过引入正则化项(如Lasso或Ridge回归),可以避免模型过拟合。
- 交叉验证:通过交叉验证,可以更可靠地评估模型性能。
- 支持向量回归 (SVR) 和 决策树回归 等非线性回归方法。
Ridge 回归的实现
from sklearn.linear_model import Ridge
# 创建Ridge回归模型
ridge_model = Ridge(alpha=1.0)
# 训练模型
ridge_model.fit(X_train, y_train)
# 预测
y_pred = ridge_model.predict(X_test)
# 评估模型
mse_ridge = mean_squared_error(y_test, y_pred)
r2_ridge = r2_score(y_test, y_pred)
print(f"Mean Squared Error (Ridge): {mse_ridge}")
print(f"R-squared (Ridge): {r2_ridge}")
通过正则化,Ridge回归可以有效减少模型的过拟合问题,提升泛化能力。


















 4703
4703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











