









卷积结构及其计算
卷积及其参数设计
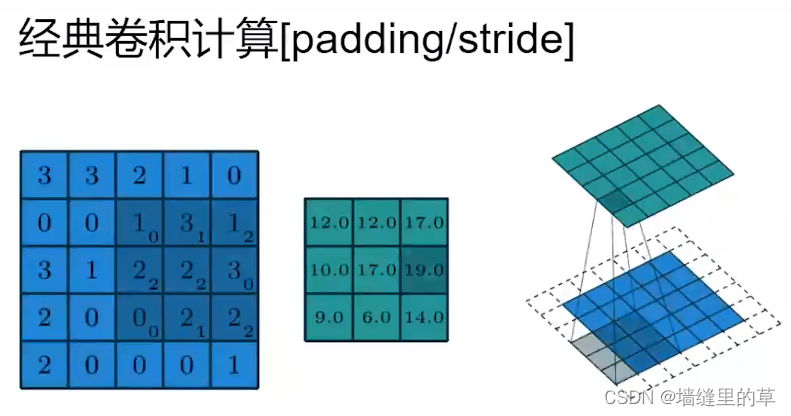
局部连接:视觉具有局部性,充分考虑领域信息,局部稠密链接
权重共享:魅族权重抽取图像中国的一种特征
答复度减少参数量、避免过拟合
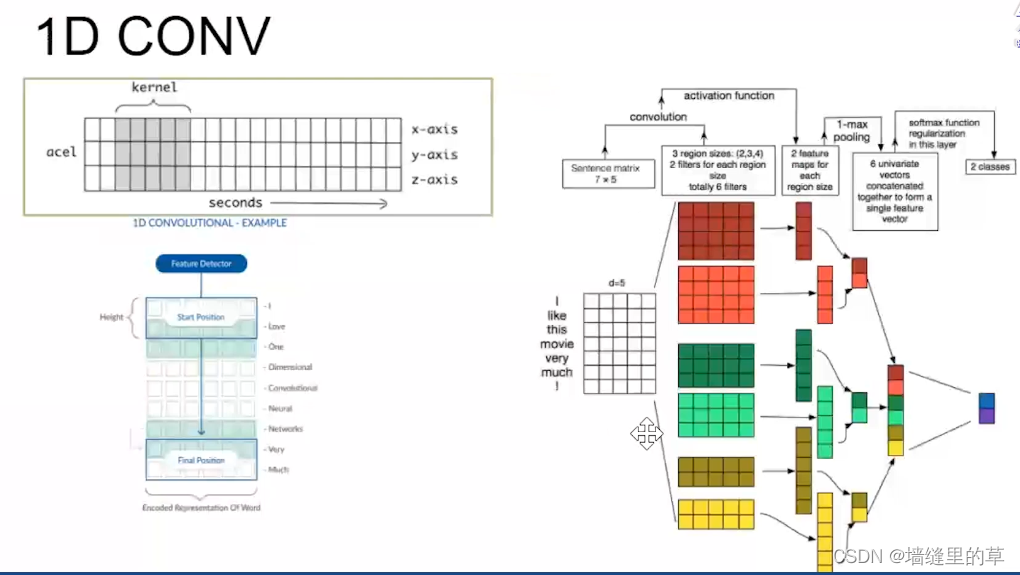
1D 上图中是运用在自然语言处理方面
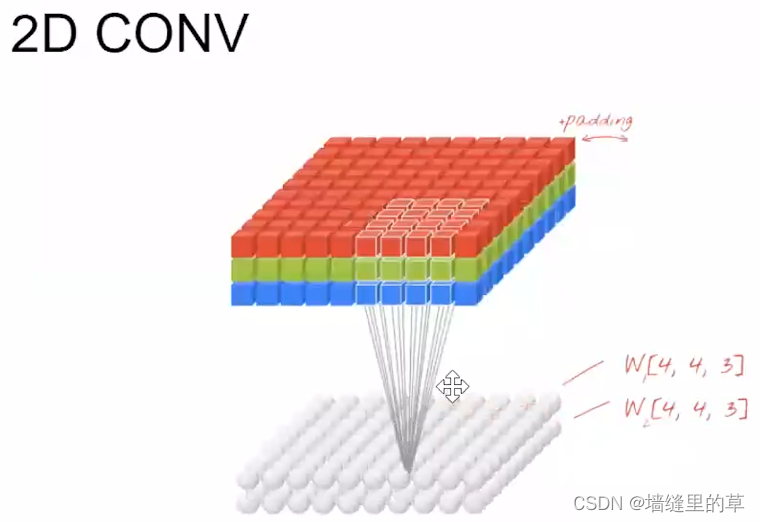
2D典型的运用在图像方面
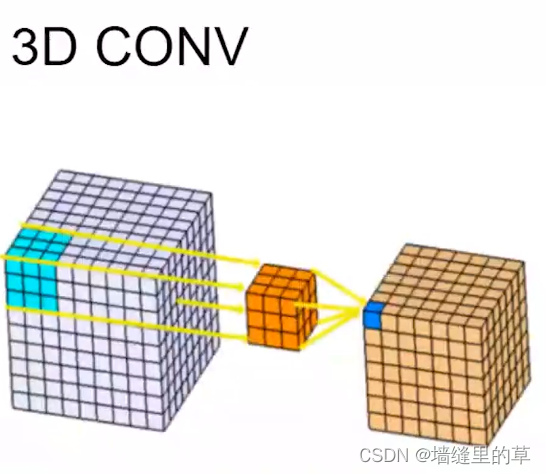
3D卷积将3维过滤器应用于数据集,并且过滤器将3方向(x, y, z)移动以计算低级特征表示。它们的输出形状是3维的体积空间,例如立方体或长方体。它们有助于视频,3D医学图像等中的事件检测。它们不仅限于3d空间,还可以应用于2d空间输入(例如图像)。
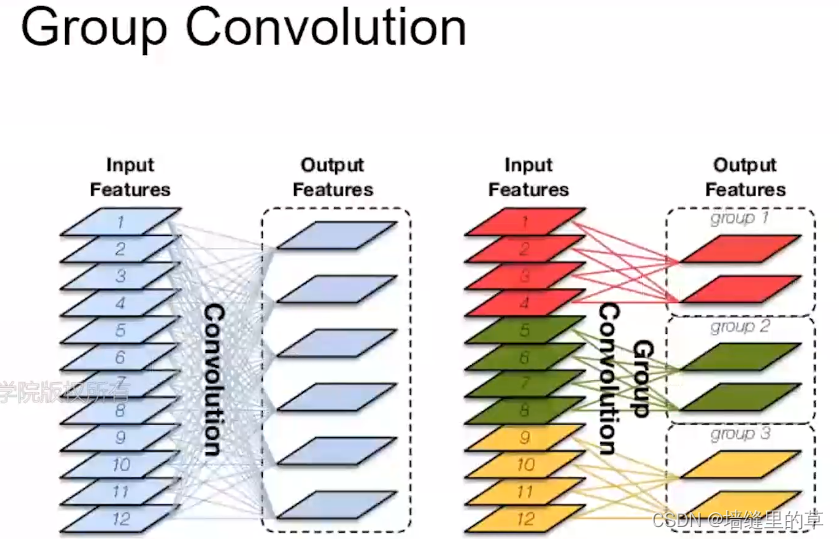
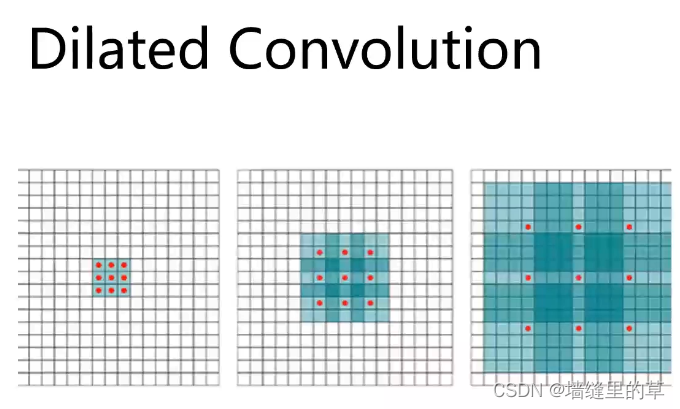
Conv2D类的dilation_ rate参数是2-元组,用于控制膨胀卷积的膨胀率。
卷积计算优化
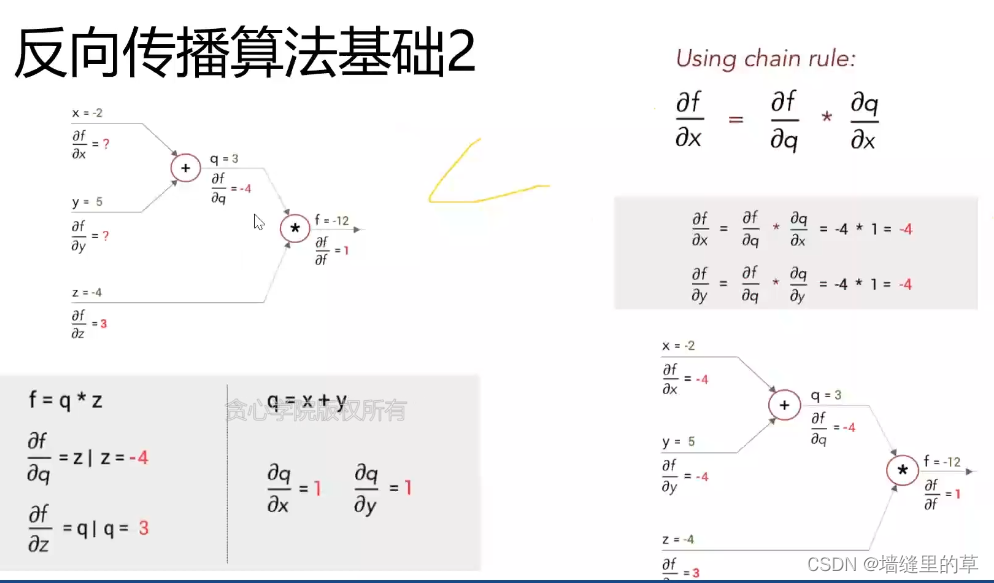

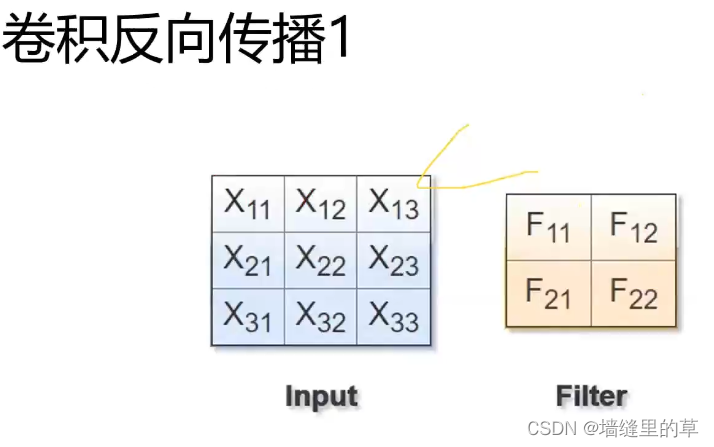

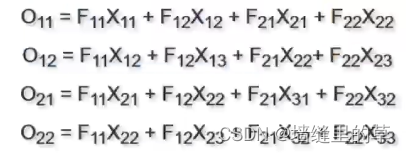
卷积反向传播3
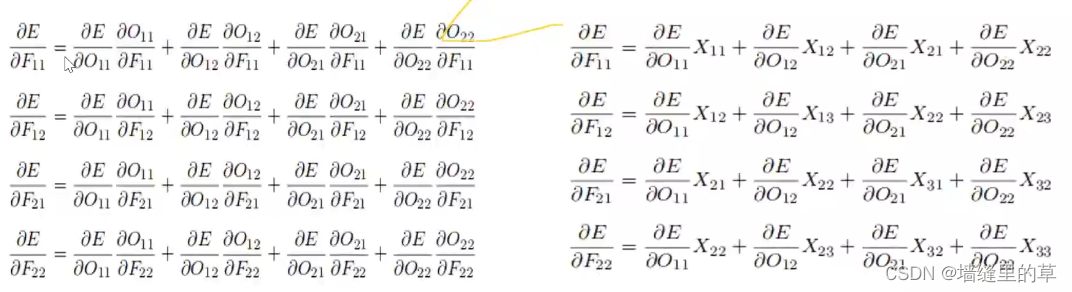
卷积反向传播4
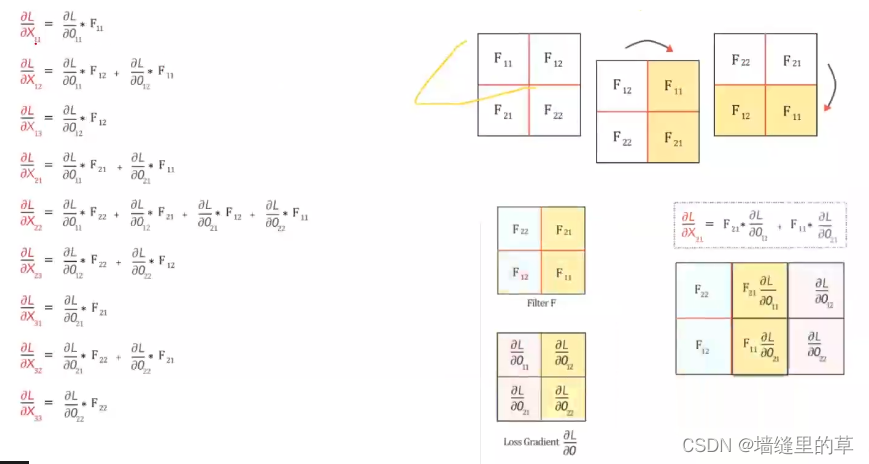
卷积反向传播5
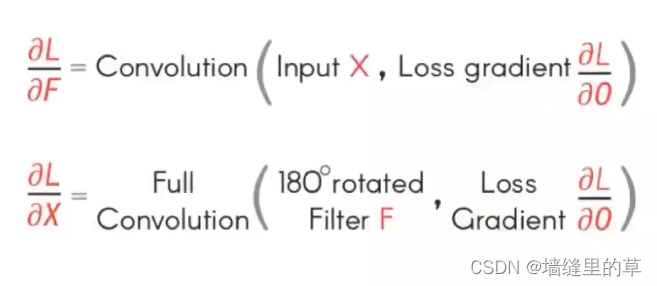
Winograd
计算复杂度
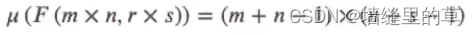
计算方法
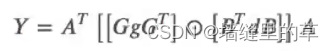
缺点:
●Depthwise conv中其优势不明显了。
●在tile较大的时候,Winograd 方法不适用,inverse transform计算开销抵消了Winograd 带来的计算节省。
●Winograd 会产生误差。
池化
●池化是使用某一位置相邻输出的总体统计特征代替网络在该位置的输出。
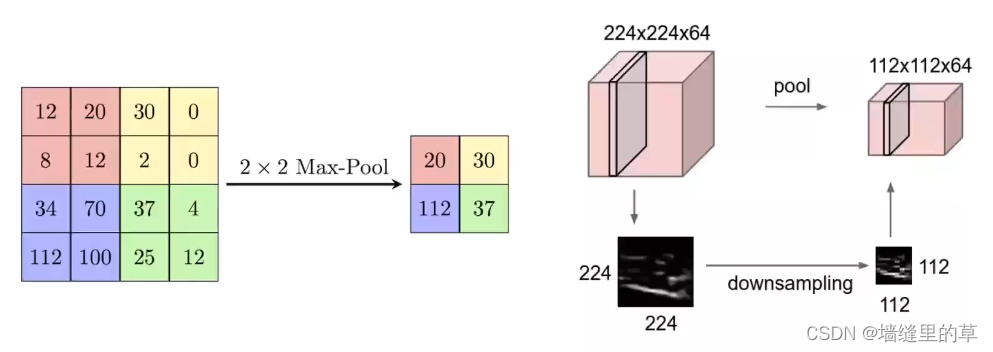
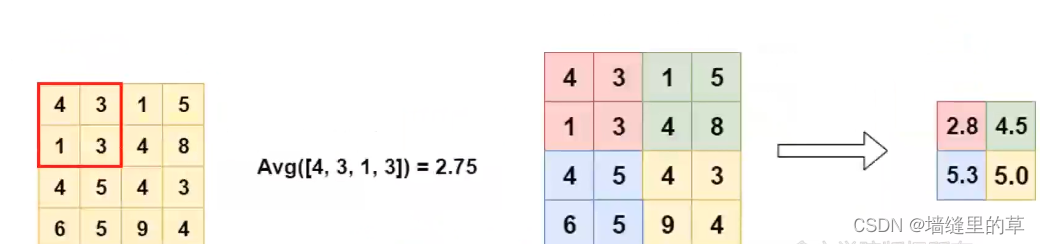
●池化(POOL)是 一个向下采样操作,通常应用于卷积层之后, 卷积层执行一些空间不变性。其中,最大池和平均池是特殊类型的池,分别取最大值和平均值。贫心学院版权所有
Max Pooling
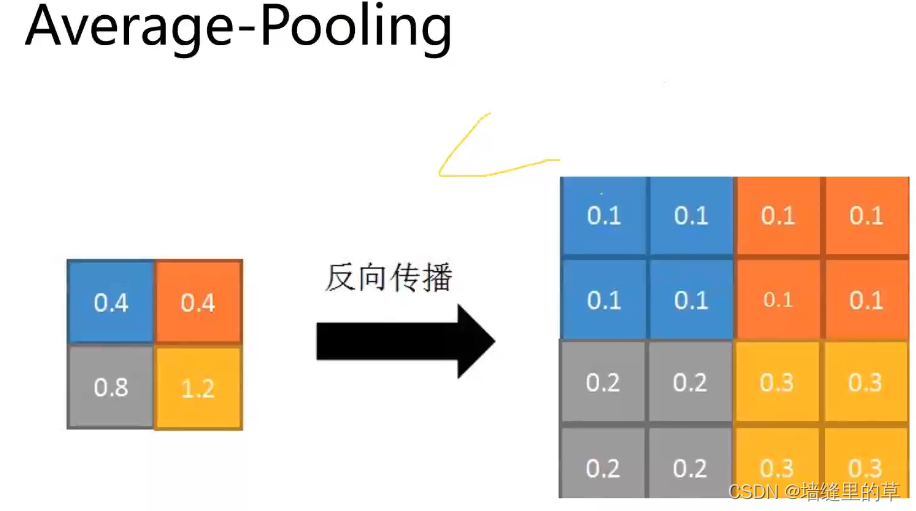
Average Pooling
卷积计算常用方法
●滑动窗口:计算比较慢,一般不采用。
●im2col:主流计算框架包括Caffe, MXNet等都实现了该方法。该方法把整个卷积过程转化成了GEMM过程,GEMM 在各种BLAS库中都是被极致优化的,一般来说,速度较快。
●FFT: 傅里叶变换和快速傅里叶变化是在经典图像处理里面经常使用的计算方法,但是,在ConvNet中通常不采用,主要是因为在ConvNet中的卷积模板通常都比较小,例如3x3等,这种情况下,FFT的时间开销反而更大。
●Winograd: Winograd 方法都显示和较大的优势,目前CUDNN中计算卷积就使用了该方法。
经典卷积神经网络模型结构
LeNet-5
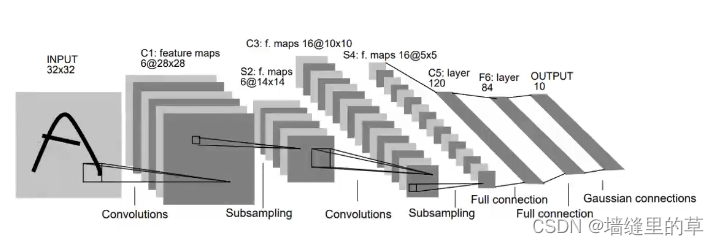
LeNet-5包含七层,不包括输入,每一层都包含可训练参数(权重),当时使用的输入数据是32*32像素的图像。下面逐层介绍LeNet- 5的结构,并且,卷积层将用Cx表示,子采样层则被标记为Sx,完全连接层被标记为Fx,其中x是层索引。
AlexNet
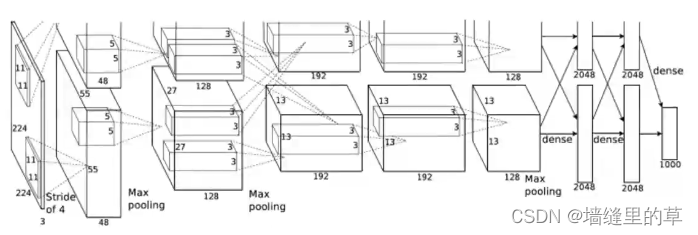
AlexNet有6亿个参数和650000个神经元,包含5个卷积层,3个全连接层
VGG
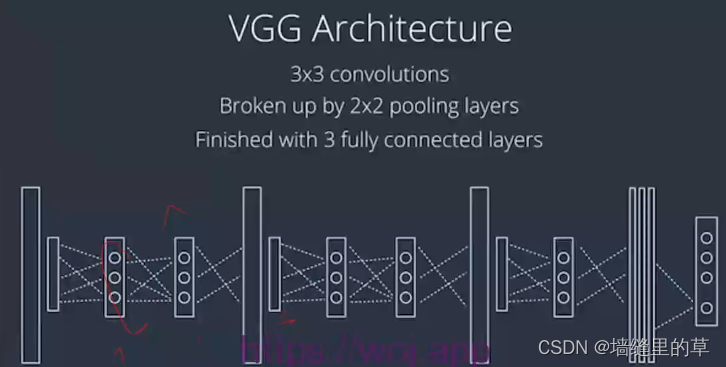
由一个很长的3 \times33x3卷积序列,穿插着2 \times 22x2的池化层,最后是3个全连接层。
GoogleNet
Inception就是把多个卷积或池化操作,放在一起组装成一个网络模块,设计神经网络时以模块为单位去组装整个网络结构。模块如下图所示
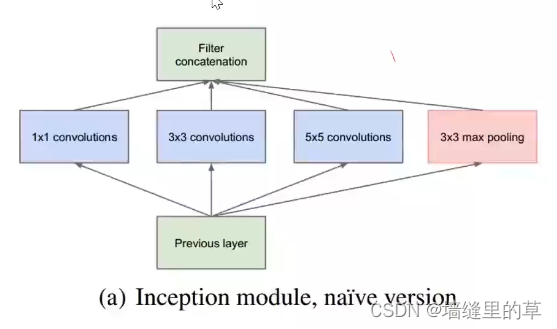
在未使用这种方式的网络里,我们一层往往只使用一种操作,比如卷积或者池化,而且卷积操作的卷积核尺寸也是固定大小的。但是,在实际情况下,在不同尺度的图片里,需要不同大小的卷积核,这样才能使性能最好,或者或,对于同一张图片,不同尺寸的卷积核的表现效果是不一样的,因为他们的感受野不同。所以,我们希望让网络自己去选择,Inception便能够满足这样的需求,一个Inception模块中并列提供多种卷积核的操作,网络在训练的过程中通过调节参数自己去选择使用,同时,由于网络中都需要池化操作,所以此处也把池化层并列加入网络中。
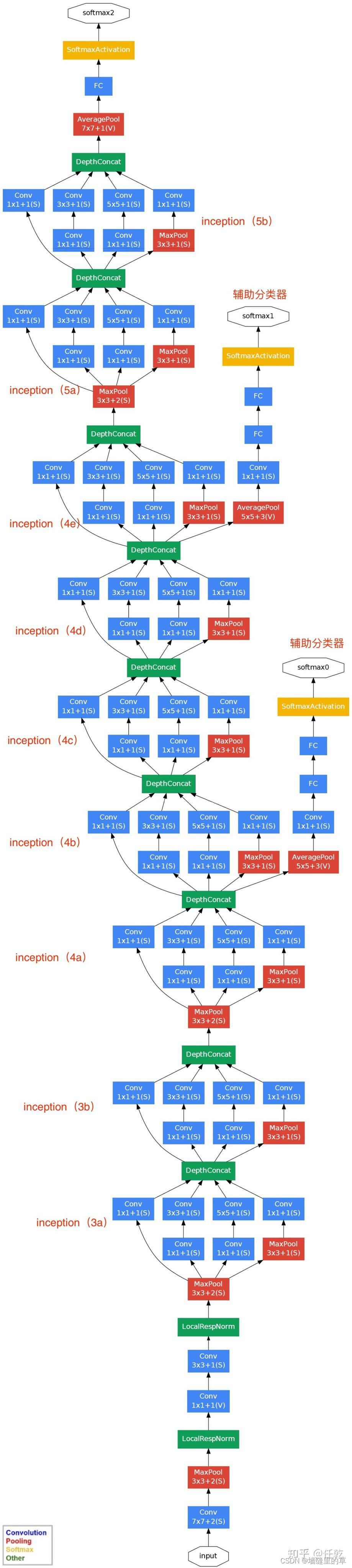
GoogLeNet的整体网络结构如下图所示
ResNet
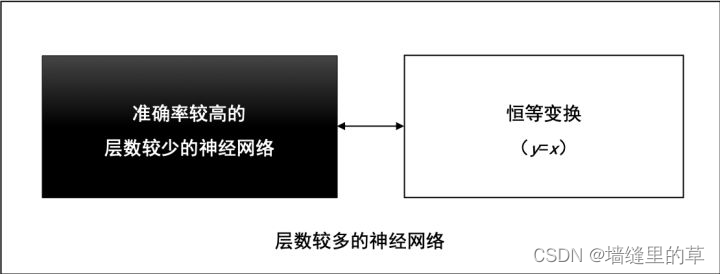
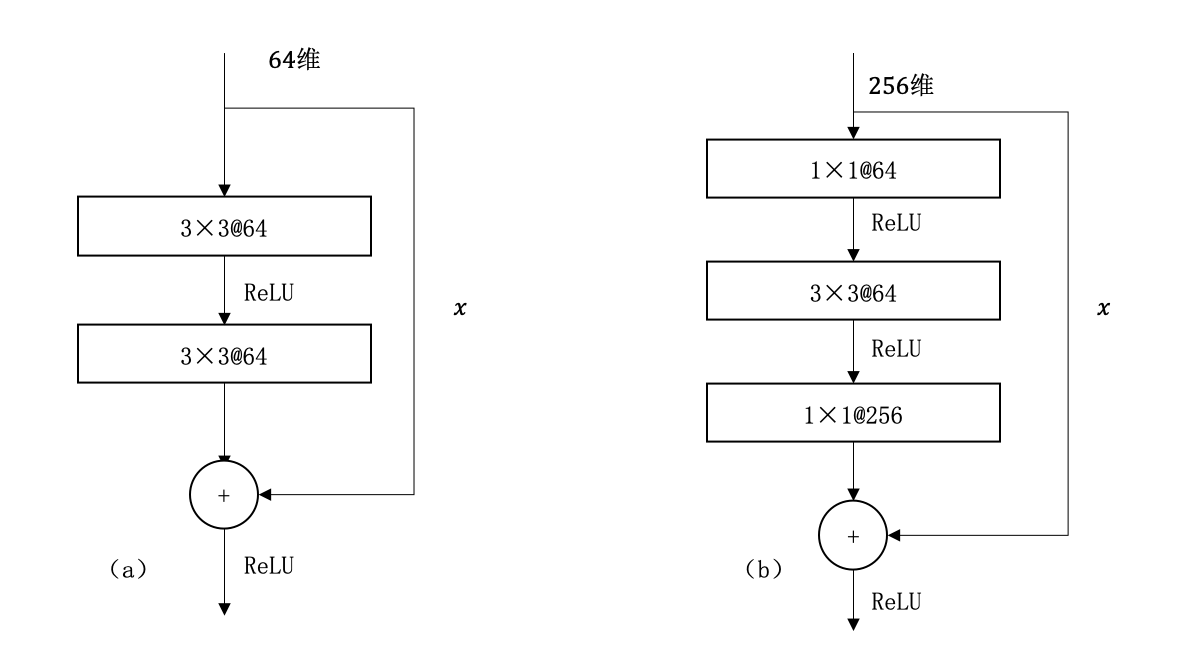
因为残差一般会比较小,学习难度小点。不过我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:
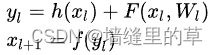
其中Xl 和 Xl+1 分别表示的是第l 个残差单元的输入和输出,注意每个残差单元一般包含多层结构。F是残差函数,表示学习到的残差,而 h(xl)=xl表示恒等映射,f是ReLU激活函数。基于上式,我们求得从浅层 l到深层L的学习特征为:
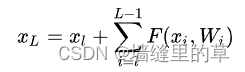
利用链式规则,可以求得反向过程的梯度:
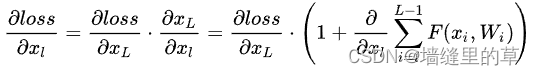
式子的第一个因子 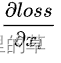 表示的损失函数到达L的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。
表示的损失函数到达L的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。
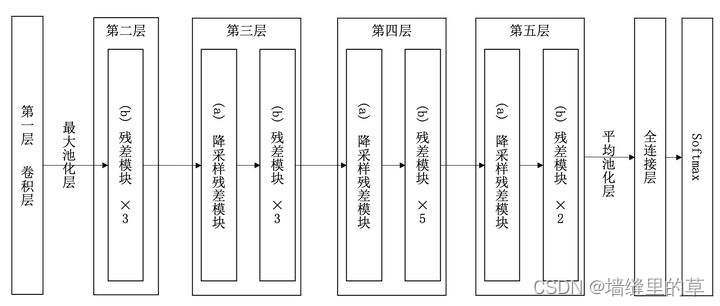
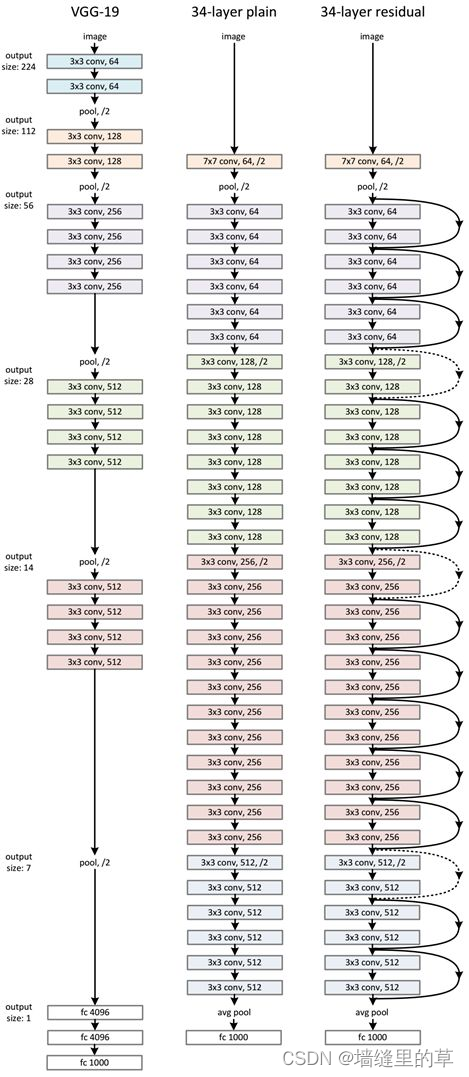
网络结构如下















 9992
9992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









