







SparkCore
行动算子:
所谓的行动算子,其实就是出发作业执行的方法
reduce:
具有聚合功能的算子:
reduce将rdd中的数据进行了两两聚合
collect:
方法会将不同分区的数据按照分区顺序采集到driver端的内存中,形成数组
count:
返回元素的个数。“val l=rdd.count’’
first:
返回数据源的第一个数据
take:
获取n个数据
takeordered:
先将数据排序,然后返回n个数据

aggregate:
该算子先将数据进行分区内计算,再进行分区间计算,给定的初始值,不仅参与了分区内的计算,同时也参与了分区间的计算
结果为:40,可知

fold:
当不同分区的计算方法相同时,即可用fold进行简化操作

countbyvalue:
可以根据元素的值,进行计算该元素的个数
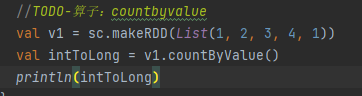

countbykey:
根据key值进行计算,可以计算出key值出现的次数,与v值无关
RDD序列化
1.闭包:
计算的角度:算子以外的代码都是在driver端执行,算子里面的代码,都是在Executor端执行,Scala函数函数式编程中,算子内的数据经常会用到算子外的数据,这样就形成的闭包效果。
2.闭包检测
若算子外的数据无法进行序列化,就意味着无法传递给Executor端执行,所以在执行任务之前,检测闭包内的对象是否可以序列化。
RDD持久化操作
RDD中不存储数据,如果一个RDD需要重复使用,那么需要从头再来获取数据,RDD对象可以重用,但是数据无法重用。此时可以利用rdd的持久化操作,来加快处理的效率。
持久化操作(cache&persist)
(cache和persist)会在血缘关系中添加新的依赖,一旦出现问题,可以从头读取数据
当rdd的数据需要重复调用时,可以将数据存入磁盘文件或内存中,在进行重复利用。即persist和cache关键字。

cache和persist的区别
cache:是将数据临时存储在内存中进行数据的重用
persist:是将数据存储在磁盘中进行数据的重用,设计磁盘IO,性能较低,但数据安全
如果任务执行完毕,临时存储的数据就会被删除
持久化操作必须是在行动算子中执行的。
(tips:RDD对象的持久化操作不一定是为了重用,在数据执行较长,或数据比较重要的操作时,也可以使用持久化操作)
RDD持久化操作(checkpoint)
执行过程中会中断血缘关系,重新建立新的血缘关系
(即将数据存储在了新的文件中,所以数据源发生了改变)
checkpoint的保存路径一般都是在分布式存储系统(HDFS)

(cache,persist和checkpoint的区别)
checkpoint临时存储的数据不会被删除,将数据长久的保存在磁盘io中;相反cache和persist存储的临时数据会被删除
checkpoint:将数据存储在磁盘io中,数据安全,一般情况下,会独立执行作业。更加导致了性能较低,所以一般情况下,checkpoint与cache同时使用,确保性能高效。

RDD分区器
分区器的意义:
可以根据数据的key值自定义分区规则,实现数据指定分区存储
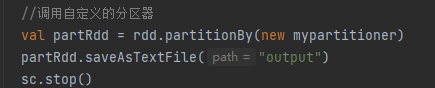
自定义分区器

自定义分区器的调用
RDD数据的保存与读取
数据的保存:
.saveAsTextFile(“output1”)
.saveAsObjectFile(“output1”)
.saveAsSequenceFile(“output1”)//该方法只能用于K-V类型的数据
数据的读取:

RDD累加器
在Driver端定义的变量,在Executor端的每个task任务上都会得到这个变量新的副本,每个任务对该副本进行计算后,返回driver端进行合并操作。
在获取累加器的值时:
会出现多加或少加的情况:
(1)少加:转换算子中调用累加器,如果没有行动算子的话,则不会执行
一般情况下,累加器放在行动算子中进行操做

工程化代码(架构模式)
一般来说:分为三层架构:
持久层–>服务层–>控制层
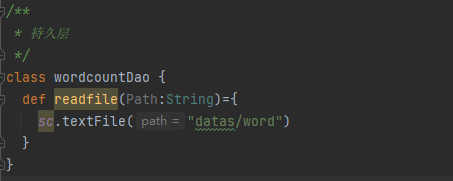
持久层(dao)
用于获取文件数据
服务层(service)
用于书写逻辑代码

控制层
用于执行逻辑代码

SparkSQL
SparkSQL是spark用于处理结构化数据处理的spark模块
SparkSQL的特点:
(1)易整合
无缝的整合了Sql查询和Spark编程
(2)统一的数据访问方式
使用相同的方式连接不同的数据源
(3)兼容hive
在已有的数据仓库上运行Sql或hive
(4)标准数据连接
采用jdbc或者odbc连接
DataFrame
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
DataFrame所展示的二维表格每一列带有名称和类型,使得SparkSQL得以洞察更多的结构信息,最终达到了大幅提升运行效率的目标。
反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单,通用的流水线优化。
SQL语法:
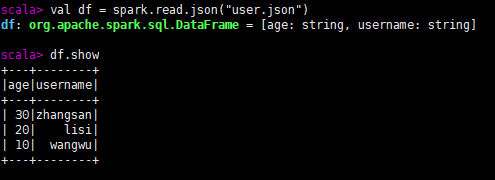
1.读取json文件并展示:
2.创建表(普通临时表)
同时将数据拆入临时表
对象名.createTempView("表名")

3.查询表中数据
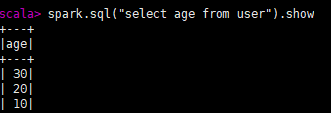
1.spark.sql("sql语句").show
2.spark.sql("select * from 文件格式.‘文件路径’").show
4.创建全局表
对象名.createGlobalTempView("表名")

普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表。
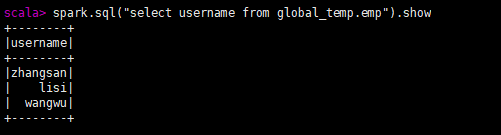
5.查询全局表中的数据
spark.sql(“select * from global_temp.全局表名”).show
DSL语法
(在idea中使用DSL语法,如果涉及到转换操作,需要引入转换规则
import spark.implictis._)
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了
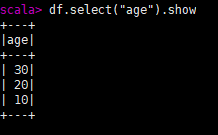
select(直接查询某列数据)
对象名.select("要查询的列名").show
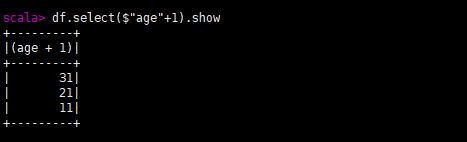
$:表示引用数据
对象名.select($"列名"+相关操作).show
'列名=$"列名"

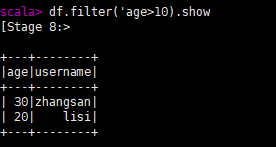
filter过滤
对象名.filter(相关操作).show
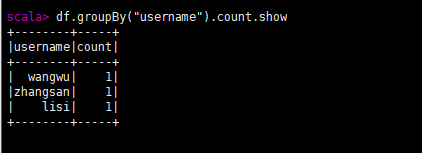
groupBy分组
对象名.groupBy("列名").count.show
RDD-DataFrame相互转换
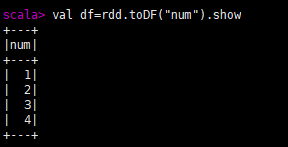
RDD转化为DataFrame
1.创建RDD:val 对象名1=sc.makeRDD(List(1,2,3,4))

2.将RDD进行转化:val 对象名2=对象名1.toDF(“新增列名”)
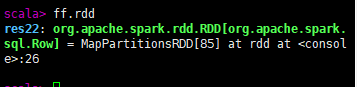
DataFrame转化为RDD
对象名.rdd
DataSet
DataSet 是分布式数据集合,是 DataFrame的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。
创建样例类
case class 类名(列名:数据类型,···)

添加数据

将样例类转化为DataSet类型
对象名.toDS

将DataFrame转换为DataSet
创建一个样例类用于承接
将数据与样例类结合,就能创建DataSet
val ds=df.as[类名]

将DataSet转换为DataFrame
```ds,toDF``

将RDD转换为DataSet
直接将数据封装成样例类
将rdd转化为Dataset
对象名.toDS

将DataSet转换为RDD
对象名.rdd
RDD,DataFrame,DataSet之间的关系
共性:
1.RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数据提供便利;
2.三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到Action 如 foreach 时,三者才会开始遍历运算;
3.三者有许多共同的函数,如 filter,排序等;
4.在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:import spark.implicits.(在创建好 SparkSession 对象后尽量直接导入)
5. 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
6. 三者都有 partition 的概念
7.DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
区别:
- RDD
➢ RDD 一般和 spark mllib 同时使用
➢ RDD 不支持 sparksql 操作- DataFrame
➢ 与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为 Row,每一列的值没法直
接访问,只有通过解析才能获取各个字段的值
➢ DataFrame 与 DataSet 一般不与 spark mllib 同时使用
➢ DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能
注册临时表/视窗,进行 sql 语句操作
➢ DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表
头,这样每一列的字段名一目了然(后面专门讲解)- DataSet
➢ Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
➢ DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,不解析,每一行究竟有哪
些字段,各个字段又是什么类型都无从得知,只能用上面提到的 getAS 方法或者共
性中的第七条提到的模式匹配拿出特定字段。而 Dataset 中,每一行是什么类型是
不一定的,在自定义了 case class 之后可以很自由的获得每一行的信息
UDF-自定义函数
该函数可在SQL文中使用
spark.udf.register("函数名",(数据名:数据类型)=>{"操作"+数据名})

数据的加载和保存
spark-shell访问数据的方式:
1.将文件上传至hdfs(文件路径前加file;//)
2.spark-shell集群节点的相同位置都有该文件
load(加载)
load默认加载的文件格式是parquet。
spark.load.read("文件路径')
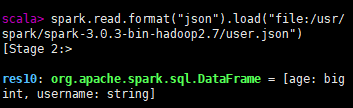
load加载非parquet文件
spark.read.format("需要加载的文件格式").load("文件路径")
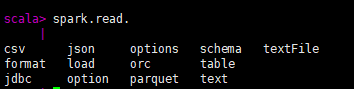
Spark.read
spark.read可以对特定文件进行读取csv,json等
spark.read.文件格式.("文件路径")
save(保存)
该方法默认保存为parquet文件且保存到了hdfs
对象名.write.save("路径")

保存为其他格式
对象名.write.format("需要的格式").save(“需要保存的路径”)

读取csv格式的文件
spark.read.format("csv").option("seq",";").option("inferSchema","true").option("header","true").load("文件路径")

SaveMode
df.write.mode("方式").json("路径")
Scala/Java Any Language
“error”(default) 如果文件已经存在则抛出异常
“append” 如果文件已经存在则追加
“overwrite” 如果文件已经存在则覆盖
“ignore” 如果文件已经存在则忽略
idea连接MYSQL:
连接时需关闭防火墙
读取MySQL数据

向MYSQL中写入数据

spark连接外置hive
1.将hive中的hive-site.xml文件导入spark的conf目录下
2.将mysql的驱动添加至spark的lib包下















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









