






一.多层感知机介绍
1. 仿射变换
仿射变换的特点是通过加权和对特征进行线性变换(linear transformation), 并通过偏置项来进行平移(translation)。
给定一个数据集,我们的目标是寻找模型的权重和偏置, 使得根据模型做出的预测大体符合数据里的真实价格。 输出的预测值由输入特征通过线性模型的仿射变换决定,仿射变换由所选权重和偏置确定。
线性意味着单调假设,对于一些场景,x的变化对y的营销不好评估。
例子:
2.解决问题
如何对猫和狗的图像进行分类呢? 增加位置处像素的强度是否总是增加(或降低)图像描绘狗的似然? 对线性模型的依赖对应于一个隐含的假设, 即区分猫和狗的唯一要求是评估单个像素的强度。 在一个倒置图像后依然保留类别的世界里,这种方法注定会失败
如何解决上述问题?
在网络中增加隐藏层,克服线性模型的限制,使其能处理更普遍的函数关系类型
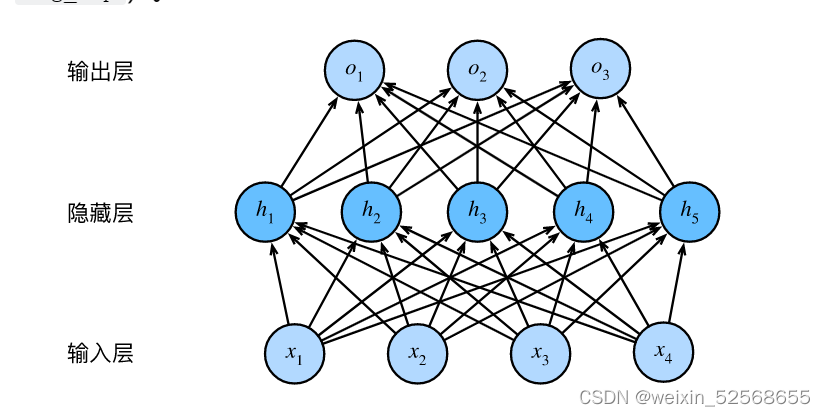
总结:
- 这个多层感知机中的层数为2
- 这两个层是全连接的,每个输入都会影响隐藏层中的每个神经元,每个隐藏层中的每个神经元会影响输出层中的每个神经元
- 全连接层参数开销较大
每一层都有权重w和偏置b,如果仅仅是多层,那么最终可以等价为 y=XW+b
为了发挥多层架构的潜力,还需要一个关键要素–激活函数,将线性变换为非线性结构。
业务含义:将有效信息向下传递,无效信息丢弃。所以隐藏层的表达为:
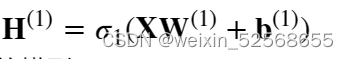
3.激活函数
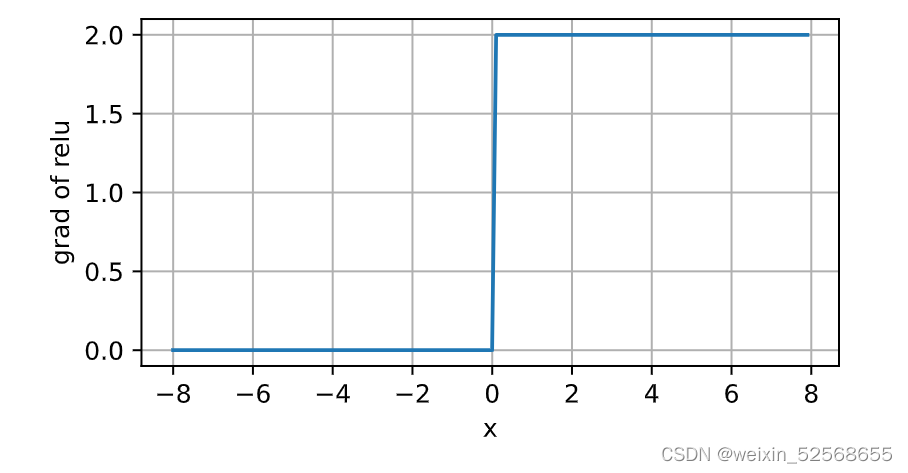
1.ReLU函数
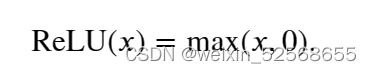
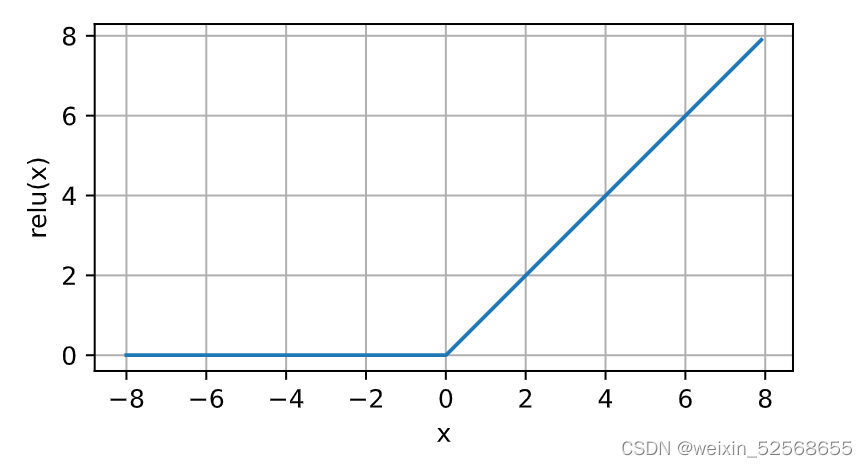
使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题
导数图像
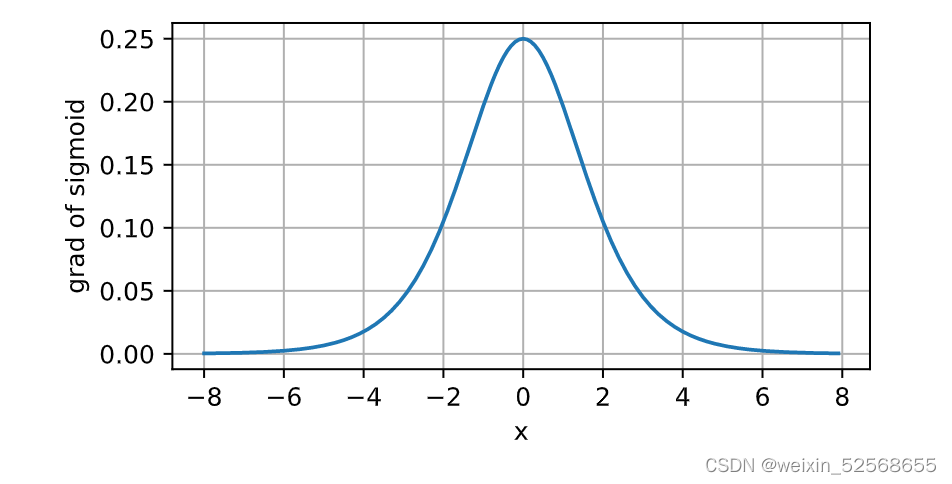
2. sigmoid函数
它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
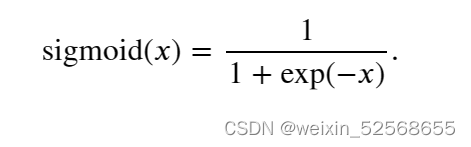
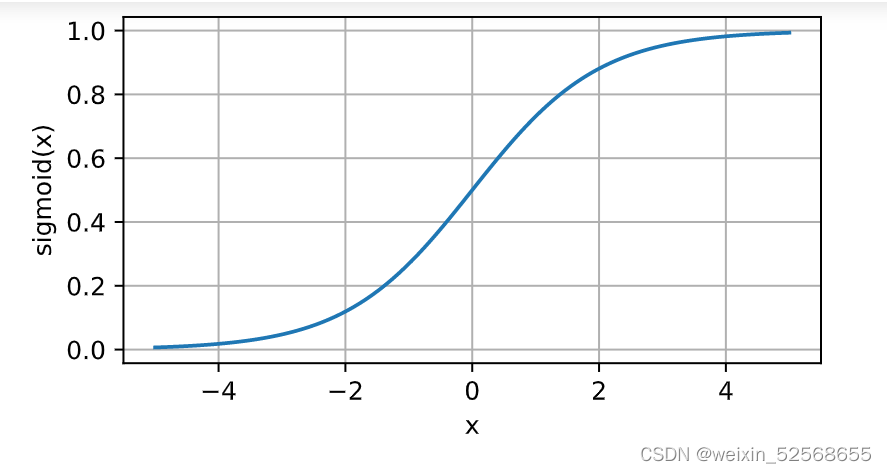
导数图像:
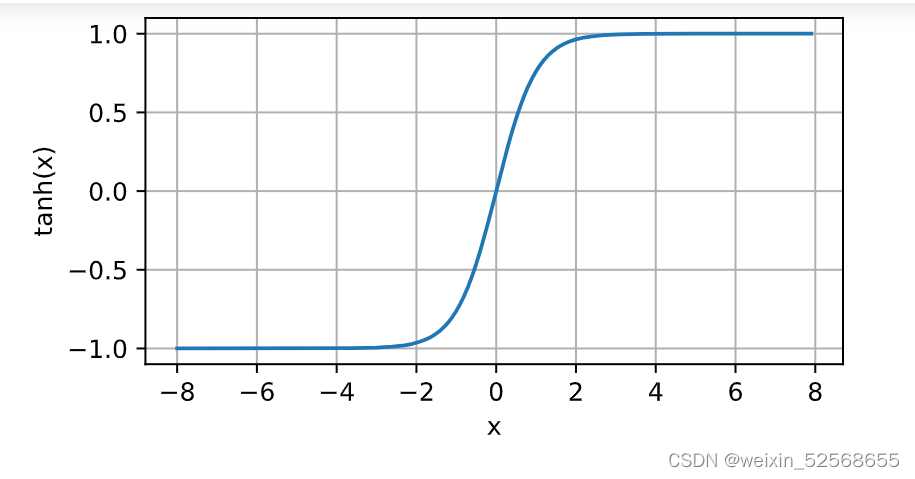
3.tanh函数
tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上:
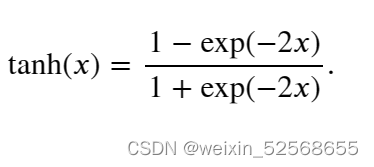
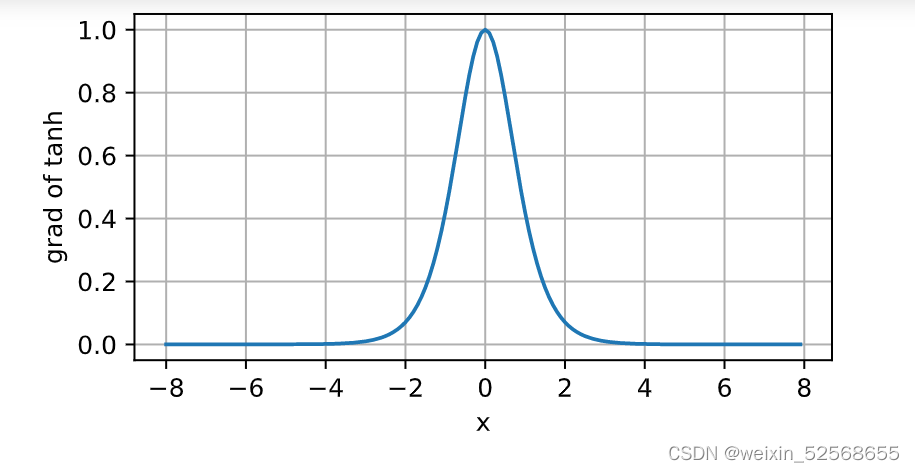
导数图像
二. 从零开始实现
1.读取数据集
#小批量读取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
2.设置输入输出、权重和偏置项
#第一层和第二层权重和偏置以及输入输出和隐藏层的大小
#此处使用三层
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10,1024, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens1, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens1, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens1, num_hiddens2, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_hiddens2, requires_grad=True))
W3 = nn.Parameter(torch.randn(
num_hiddens2, num_outputs, requires_grad=True) * 0.01)
b3 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2, W3, b3]
3.定义激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
4.定义训练网络
# 将样本拉平,计算第一、二、三层,得到输出
def net(X):
X = X.reshape((-1, num_inputs))
H1 = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
H2 = relu(H1@W2 + b2)
return (H2@W3 + b3)
5. 定义损失函数
#定义损失函数,使用交叉熵损失
loss = nn.CrossEntropyLoss(reduction='none')
6. 训练方法和优化
#定义迭代次数和学习率
num_epochs, lr = 10, 0.1
#使用sgd梯度优化
updater = torch.optim.SGD(params, lr=lr)
#调用训练函数
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
7. 预测
#在测试集上进行预测
d2l.predict_ch3(net, test_iter)
三. 简洁实现
1.定义模型
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
2.损失函数和优化器
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
3. 加载数据并训练
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
总结:
- 简洁实现更简单
- 对于多分类问题,MLP和softmax的区别,在于MLP增加了激活函数的隐藏层
3、超参数:隐藏层数量,学习率,训练迭代次数、每层隐藏单元数
问题:
- 在所有其他参数保持不变的情况下,更改超参数num_hiddens的值,并查看此超参数的变化对结果有何影响。确定此超参数的最佳值。
- 尝试添加更多的隐藏层,并查看它对结果有何影响。
- 改变学习速率会如何影响结果?保持模型架构和其他超参数(包括轮数)不变,学习率设置为多少会带来最好的结果?
- 通过对所有超参数(学习率、轮数、隐藏层数、每层的隐藏单元数)进行联合优化,可以得到的最佳结果是什么?
- 描述为什么涉及多个超参数更具挑战性。
- 如果想要构建多个超参数的搜索方法,请想出一个聪明的策略
尝试结果记录:
对比分析结论:
参考视频:
https://www.bilibili.com/video/BV1hh411U7gn/?spm_id_from=333.880.my_history.page.click&vd_source=cb68816dd6afc442cd74bf8a70238742















 2458
2458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









