






1.导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optim
%matplotlib inline
import datetime
import torch.nn as nn
2.导入数据
features = pd.read_csv("./data/temps.csv")
features.shape
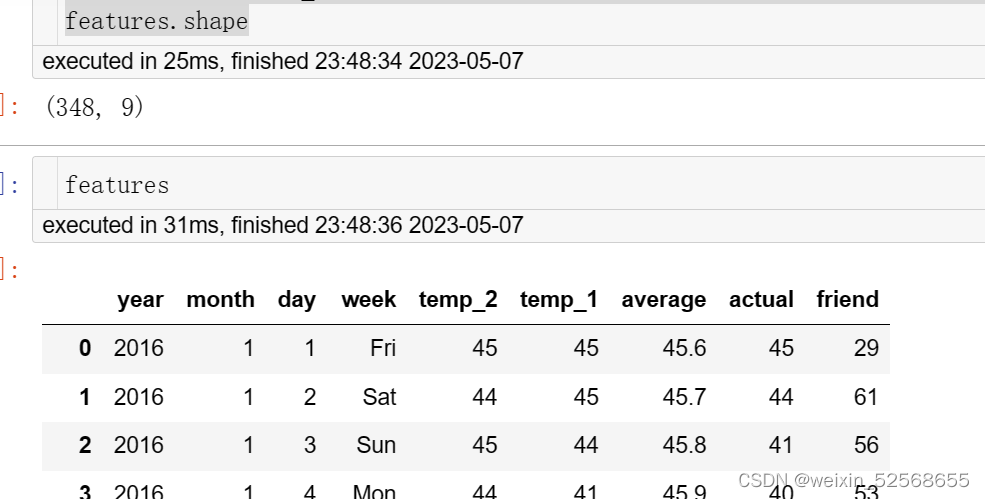
此处可以看到,样本数量348,一共9列,其中年月日占三列
3.处理数据
- 将年月日整理为一个字段
years = features['year']
months=features['month']
days = features['day']
dates = []
# 此处两种写法, 1、for循环 append的方式写入数组
for y,m,d in zip(years,months,days):
dates.append(str(y)+'-'+str(m)+'-'+str(d))
# 2.[A for B in C] 这个写法,遍历C中的B,把满足条件A的放到数组里
##举例[a for b in c] 一个例子 Y = [ [ int(x1+x2 < 1) ] for (x1, x2) in X ] 对X中的每一组元素(x1, x2)遍历一遍,当满足(x1+x2 < 1)时,就把这个布尔值[True]/[False]转换成int型(1或0),存放在[ ]里,作为Y的一个元素。
dates = [datetime.datetime.strptime(date,"%Y-%m-%d") for date in dates]
dates[:5]
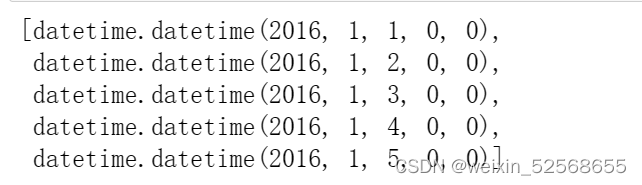
tip:循环遍历的写法
- 把日期放到原数据后
# 使用date命名,将数组dates作为列内容,创建为dataframe
dates_df = pd.DataFrame(data = {'date': dates})
# 使用concat链接,需要将两个dataframe连接起来,axis表示是横向追加还是纵向追加,横向是加样本,纵向是加列
features=pd.concat([features, dates_df], axis=1)
features
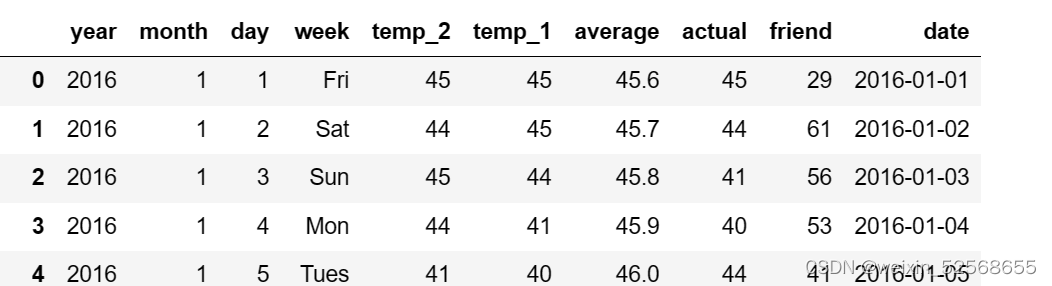
3. week字段属于离散值类型,对这种类型的数据进行独热编码处理(onehot)
# 独热编码,两个方式,getdummies
features = pd.get_dummies(features,columns=['week'])
features.head(5)
处理完成后,结果会在原来的dataframe上追加列
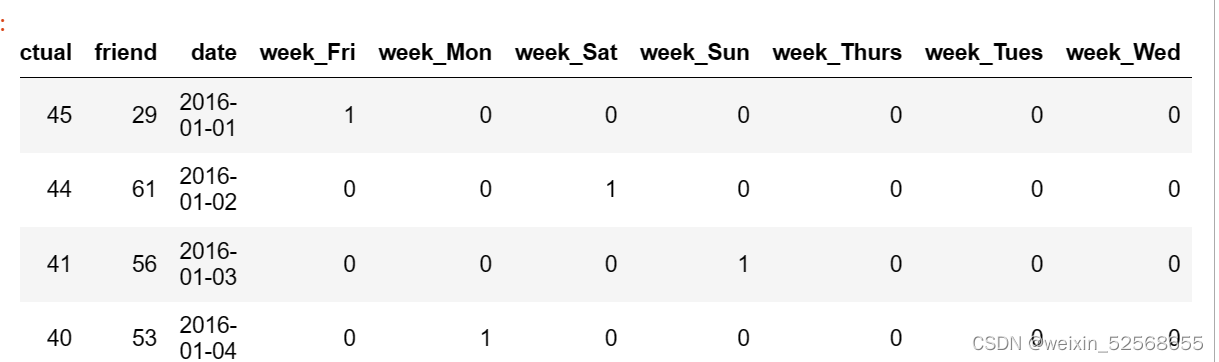
独热编码原理:
1、获取当前列的所有值,有几个算几个
2、将值进行排序,数字或字母大小写
3、按顺序编码,比如 男、女,男10,女01
通过oneHotEncoder处理的方式,这个是sklearn中的包,缺点,没有那么智能,可以自动加列,onehotEncoder处理完的列名用0,1,2,3这种顺序编码
独热编码的问题:如果训练集中没有,但是测试集中有,那么会缺失编码值。
# 独热编码,两个方式,OneHotEncoder
# 取当前列所有的值进行扩展,按照原始数据的大小排序,排序后进行编码,和getDummies产出数据一样
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
weekcol = pd.DataFrame(enc.fit_transform(features[['week']]).toarray())
features=pd.concat([features, weekcol], axis=1)
features.drop(['week'],axis=1)
4、删除无用数据,并将真实值单独存储
# 真实值标签
labels = np.array(features['actual'])
#真实值和date对应关系,便于后续绘图
true_data=pd.DataFrame(data={'date':dates,'actual':labels})
# 在特征中去掉标签
features= features.drop(labels={'actual','year','month','day'}, axis = 1)
5、处理数据标准化
# 转化为标准的正态分布
#fit 需要先执行fit,适配
#transform 执行具体操作
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
input_features.shape
4. 定义模型
class TempModel(nn.Module):
def __init__(self,inputSize,outputSize):
#需要调super,否则有报错
super(TempModel,self).__init__()
self.inputSize=inputSize
self.outputSize=outputSize
#定义隐藏128
#该网络一个全连接,激活函数sigmoid,一个隐藏层128个神经元,输出一个结果
self.net=nn.Sequential(
nn.Linear(inputSize,128),
nn.Sigmoid(),
nn.Linear(128,outputSize)
)
def forward(self,inputData):
return self.net(inputData)
def trainMode(batchSize,opti,inputData,model,labels,loss,device):
batch_loss = []
#模型训练
model.train()
#按批次取
for start in range(0,len(inputData),batchSize):
end = min(len(inputData),start+batchSize)
#需要将数据&model都放到一个device中,尤其是gpu跑数据
x=torch.tensor(inputData[start:end],dtype=torch.float,requires_grad=True).to(device)
y=torch.tensor(labels[start:end],dtype=torch.float,requires_grad=True).to(device)
pred = model(x)
#计算损失
loss_v=loss(pred,y)
#优化梯度清零
opti.zero_grad()
#反向传播
loss_v.backward(retain_graph=True)
#执行优化器
opti.step()
#将损失返回,计算时需要传递到cpu计算,否则有报错
batch_loss.append(loss_v.to('cpu').data.numpy())
return batch_loss
def testMode(batchSize,opti,inputData,model,labels,loss,device):
batch_loss = []
batch_pred = []
model.eval()
for start in range(0,len(inputData),batchSize):
end = min(len(inputData),start+batchSize)
x=torch.tensor(inputData[start:end],dtype=torch.float,requires_grad=True).to(device)
y=torch.tensor(labels[start:end],dtype=torch.float,requires_grad=True).to(device)
pred = model(x)
loss_v=loss(pred,y)
opti.zero_grad()
loss_v.backward(retain_graph=True)
opti.step()
batch_loss.append(loss_v.to('cpu').data.numpy())
batch_pred.extend(pred.squeeze().cpu().detach().numpy())
return batch_loss,batch_pred
5.训练
cost = nn.MSELoss(reduction='mean')
inputsize=input_features.shape[1]
model_temp=TempModel(inputsize,1)
device='cuda:0'
model_temp = model_temp.to(device)
optimizer=optim.Adam(model_temp.parameters(),lr=0.003)
epoch=1000
batchsize=16
losses_t = []
for i in range(epoch):
batchloss=trainMode(batchsize,optimizer,input_features,model_temp,labels,cost,device)
if i%100==0:
losses_t.append(np.mean(batchloss))
print(i,np.mean(batchloss))
_,pred_t=testMode(batchsize,optimizer,input_features,model_temp,labels,cost,device)
6、绘图
r=np.array(pred_t)
r.reshape(-1)
r.shape
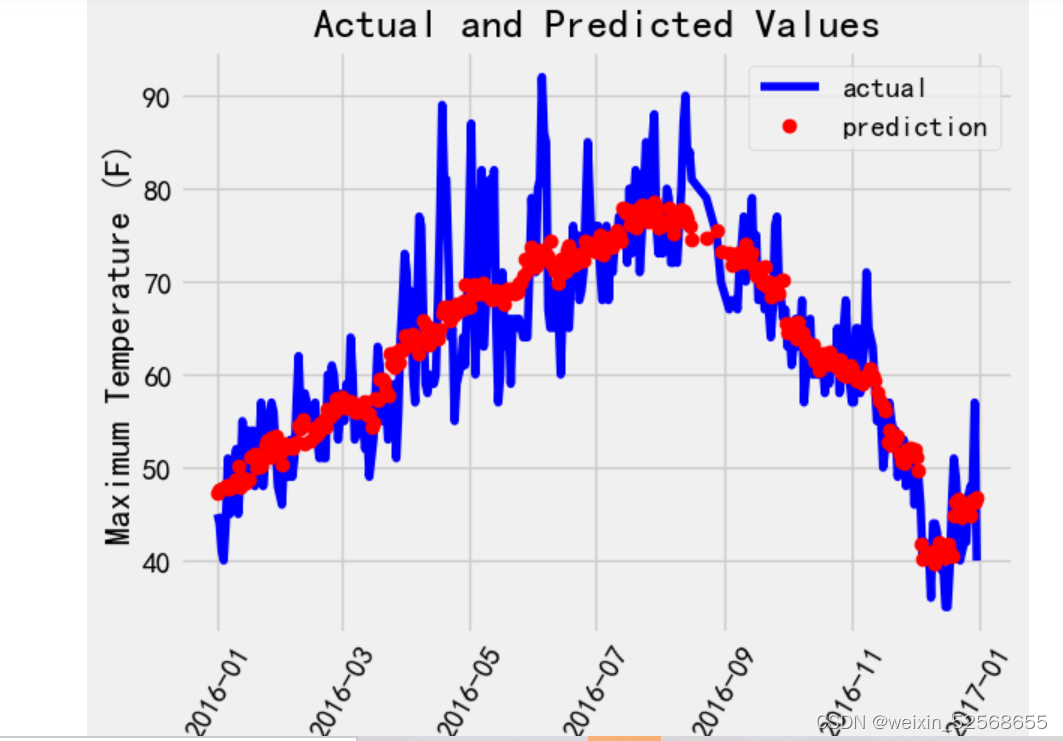
pre_data =pd.DataFrame(data = {'date': dates, 'prediction': r})
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# 预测值
plt.plot(pre_data['date'], pre_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60');
plt.legend()
# 图名
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');
总结
1、dataframe和array的转换
2、数组多维的时候,append 会在数组里放数组或者元素,维度会加1;extend是追加,维度不变
3、onehot编码
4、gpu运行和cpu运行需要注意,指定到对应的device,数据和模型都要到一个环境里
6、整个代码没有考虑测试集验证集训练集















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









