







一、GLM-4-32B-0414模型
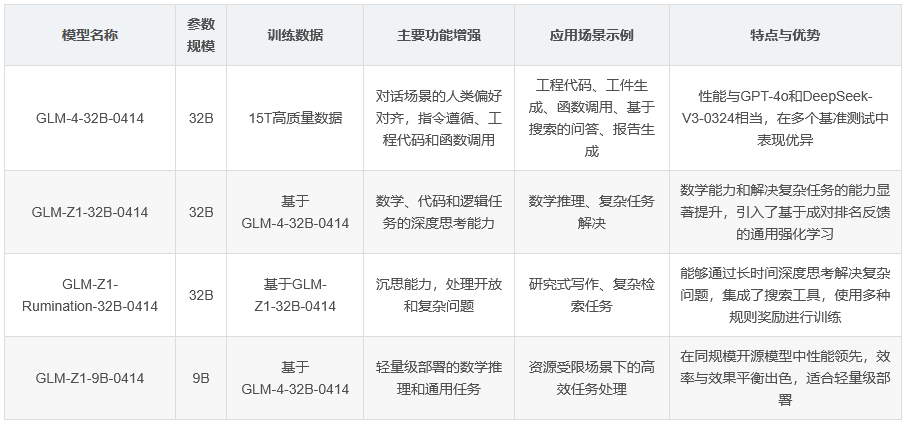
GLM-4-32B-0414系列模型是清华大学自然语言处理研究团队(THUDM)开发的最新一代开源大模型,拥有320亿参数,性能与OpenAI的GPT系列和DeepSeek的V3/R1系列相当。该模型基于15T高质量数据预训练,其中包含大量推理类合成数据,为后续强化学习扩展奠定了基础。在后训练阶段,除了对话场景中的人类偏好对齐外,还通过拒绝采样和强化学习等技术增强了模型在指令遵循、工程代码和函数调用方面的能力,从而加强了代理任务所需的基本能力。
GLM-4-32B-0414在工程代码、工件生成、函数调用、基于搜索的问答和报告生成等领域取得了良好成果。在某些基准测试中,其性能甚至与GPT-4o和DeepSeek-V3-0324(671B)等更大规模的模型相当。
二、GLM-Z1-32B-0414推理模型
GLM-Z1-32B-0414是基于GLM-4-32B-0414开发的推理模型,具有深度思考能力。通过冷启动、扩展强化学习以及在数学、代码和逻辑任务上的进一步训练,该模型在数学能力和解决复杂任务方面相较于基础模型有了显著提升。在训练过程中,引入了基于成对排名反馈的通用强化学习,进一步增强了模型的通用能力。
GLM-Z1-32B-0414在数学推理和复杂任务处理方面表现出色,特别是在资源受限的场景下,能够实现效率与效果的平衡,为轻量级部署的用户提供了强大的选择。
三、GLM-Z1-Rumination-32B-0414深度推理模型
GLM-Z1-Rumination-32B-0414是具有沉思能力的深度推理模型,能够通过更长时间的深度思考解决更开放和复杂的问题,例如撰写两个城市AI发展及其未来规划的比较分析。该模型在深度思考过程中集成了搜索工具,并通过多种规则奖励指导和扩展端到端强化学习进行训练。
Z1-Rumination在研究式写作和复杂检索任务中表现出显著改进,能够处理复杂的任务并生成高质量的输出。
四、GLM-Z1-9B-0414小型模型
GLM-Z1-9B-0414是一个90亿参数的小型模型,尽管规模较小,但在数学推理和通用任务方面仍展现出卓越能力。其整体性能在同规模的开源模型中处于领先地位。特别是在资源受限的场景下,该模型在效率和效果之间取得了出色的平衡,为寻求轻量级部署的用户提供了强大的选项。
五、模型使用指南
在使用GLM模型时,建议遵循以下参数设置:
-
temperature:0.6,平衡创造力和稳定性
-
top_p:0.95,累积概率阈值用于采样
-
top_k:40,过滤罕见词同时保持多样性
-
max_new_tokens:30000,为思考留出足够的token空间
此外,模型在输入长度超过8,192 tokens时,可以启用YaRN(Rope Scaling)来处理长上下文。在支持的框架中,可以在config.json中添加以下片段:
JSON
复制
"rope_scaling": {
"type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
六、模型应用示例
GLM模型支持多种应用场景,包括但不限于:
-
代码生成:设计一个支持自定义函数绘制的绘图板,允许添加和删除自定义函数,并为函数分配颜色。
-
网页设计:使用HTML模拟一个小球从旋转六边形中心释放的场景,考虑小球与六边形边缘的碰撞、重力作用,并假设所有碰撞都是完全弹性的。
-
SVG生成:使用SVG创建一个雾气江南场景,或展示大型语言模型训练过程的插图。
-
基于搜索的写作:根据搜索结果回答用户问题,生成符合用户要求且有深度的专业答案。
七、模型性能评估
GLM-4-32B-0414系列模型在多个基准测试中表现出色,包括SimpleQA、HotpotQA等。在与GPT-4o、DeepSeek-V3等模型的对比中,GLM-4-32B-0414在多个指标上取得了领先或相当的性能。例如,在SimpleQA测试中,GLM-4-32B-0414的准确率达到87.6%,在HotpotQA测试中达到69.6%。
八、模型调用与工具集成
GLM模型支持调用外部工具,例如天气查询工具。通过HuggingFace Transformers、vLLM或sgLang等库,可以实现工具调用和结果处理。模型能够根据工具返回的结果生成最终响应,为用户提供更全面和准确的答案。
九、总结
GLM模型家族通过其强大的推理能力和广泛的适用性,为自然语言处理领域提供了强大的工具。无论是大规模的32B模型还是轻量级的9B模型,GLM系列都能满足不同场景下的需求,推动了开源大模型的发展和应用。

















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









