







Flex.2-preview 文本生成图像扩散模型介绍
一、模型简介
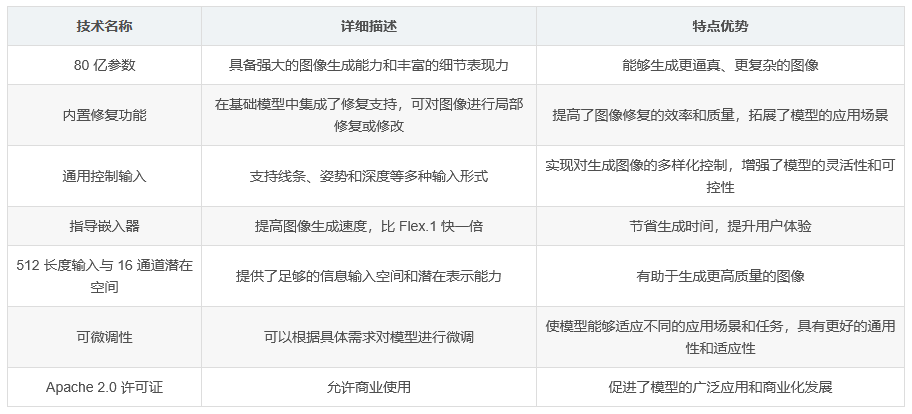
Flex.2-preview 是一种 开源的 80 亿参数文本生成图像扩散模型,具备通用控制和修复支持功能,是 Flex.1alpha 的下一代版本。该模型由社区开发并为社区服务,采用 Apache 2.0 许可证,允许商业使用。它具有 512 长度的输入、16 通道潜在空间,且可微调。
二、功能特性
-
内置修复功能 :在基础模型中集成了修复支持,能够对图像进行局部修复或修改。
-
通用控制输入 :支持多种输入形式,如线条、姿势和深度信息,实现对生成图像的多样化控制。
-
高效性 :具有指导嵌入器,使得图像生成速度比 Flex.1 提高了一倍。
三、使用方法
ComfyUI 环境
-
安装 Flex2 Conditioner 节点和 comfyui_controlnet_aux 工具,用于生成控制图像(姿势和深度)等。
-
下载 Flex.2-preview.safetensors 模型文件,并放置在 ComfyUI/models/diffusion_models 文件夹下,重启 ComfyUI。
-
使用预设的工作流程示例来开始控制和修复操作。
Diffusers 环境
-
安装所需的库,包括 torch、accelerate、transformers 和 diffusers。
-
导入必要的模块,如 AutoPipelineForText2Image 和 load_image 等。
-
通过加载 Flex.2-preview 模型,并指定相关参数(如输入图像、掩码、控制图像等)来生成图像。
四、技术细节
-
Flex.2 的开发过程经历了 Flux.1 Schnell、OpenFlux.1、Flex.1-alpha 等阶段,每一次迭代都有所进步,而 Flex.2 是目前最大的进步。
-
在控制和修复的训练方面比较激进,模型在一些方面(如解剖结构和文本)上存在困难,修复功能也在持续改进中。
-
Flex.2 设计为可微调,尽管实践尚处于实验阶段。可以直接在能够进行控制和修复的模型上训练传统的 LoRAs,Flex.1-alpha 的 LoRAs 也通常能很好地与之配合。
五、局限性与改进
-
局限性
-
模型在处理解剖结构和文本方面存在一定的困难。
-
修复功能仍在完善中,尚未达到理想效果。
-
-
改进措施
-
开发者正通过每次新的训练运行来改进这些限制。
-
支持通过训练简单的 LoRA 来让模型使用自定义控制。
-
六、未来展望
开发者鼓励用户反馈模型的使用体验,提出改进建议和新功能需求。同时,他们也在探索最佳实践,以推动 Flex.2-preview 模型的进一步发展和优化。
Flex.2-preview 核心技术汇总表

















 5984
5984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









