







Open Molecules 2025 (OMol25) 数据集、评估与模型
一、引言
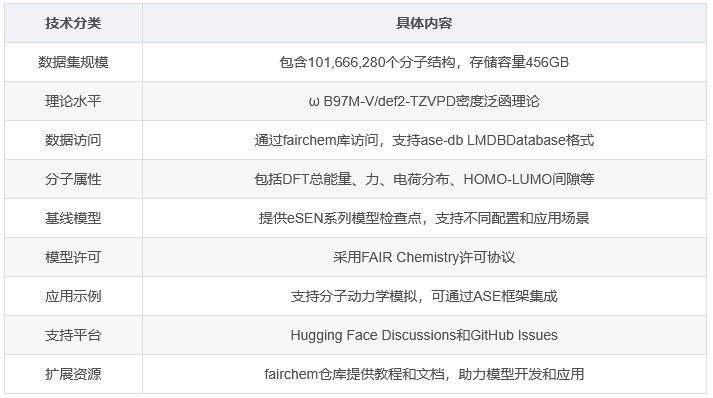
Open Molecules 2025(OMol25)代表着目前最大规模的高质量分子密度泛函理论(DFT)数据集。该数据集涵盖了生物分子、金属复合物、电解质以及社区数据集等多个领域。OMol25数据集是在ω B97M-V/def2-TZVPD理论水平下生成的,为分子科学研究提供了宝贵的资源。详细信息可在相关arxiv论文中查阅。
二、数据集详情
OMol25数据集提供了训练和验证的分割版本,数据文件以ase-db LMDBDatabase对象形式编写。数据集规模庞大,包含超过1亿个分子结构,存储容量高达456GB。数据集分为中性分子和带电分子部分,验证集规模相对较小,便于模型验证。
数据集采用CC-BY-4.0许可协议,允许在遵守协议的前提下自由使用。
三、数据读取方法
研究者可通过fairchem库访问OMol25数据集。安装fairchem库的命令如下:
pip install git+https://github.com/facebookresearch/fairchem.git@fairchem_core-2.0.0#subdirectory=fairchem
读取数据集的示例代码:
from fairchem.core.datasets import AseDBDataset
dataset_path = "/path/to/omol/dir/train_4M"
dataset = AseDBDataset({"src": dataset_path})
atoms = dataset.get_atoms(0) # 通过索引获取原子对象
四、数据属性
每个分子结构包含DFT总能量(eV)和力(eV/Å)标签。此外,atoms.info还包含其他重要属性和元数据,包括:
数据源和内部标识符
分子电荷、自旋状态
原子数量、电子数量
HOMO能量、HOMO-LUMO间隙
Mulliken、Lowdin、NBO电荷分布
分子组成等信息
五、基线模型
研究者提供了在完整OMol25数据集上训练的基线模型检查点,包括不同配置的eSEN模型:
eSEN-sm-direct
eSEN-sm-conserving
eSEN-md-direct
eSEN-lg-direct(即将推出)
模型检查点采用FAIR Chemistry许可协议,可通过fairchem仓库中的自定义ASEcalculator便捷使用。
六、模型应用示例
以下为使用模型进行分子动力学模拟的示例代码:
from ase import units
from ase.io import Trajectory
from ase.md.langevin import Langevin
from ase.build import molecule
from fairchem.core import FAIRChemCalculator
calc = FAIRChemCalculator(checkpoint_path="/path/to/esen_sm_conserving_all.pt", device="cuda")
atoms = molecule("H2O")
atoms.calc = calc
dyn = Langevin(
atoms,
timestep=0.1 * units.fs,
temperature_K=400,
friction=0.001 / units.fs,
)
trajectory = Trajectory("my_md.traj", "w", atoms)
dyn.attach(trajectory.write, interval=1)
dyn.run(steps=1000)
七、支持与资源
研究者可在以下平台寻求支持或反馈问题:
-
Hugging Face Discussions
-
GitHub Issues
fairchem仓库还提供了额外的教程和文档资源,帮助用户更好地利用OMol25数据集和模型。
核心技术汇总

















 2303
2303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









