







一、引言
BAGEL模型概述
BAGEL是一种开源的多模态基础模型,拥有7B活动参数(总参数量为14B)。该模型在大规模交错的多模态数据上进行训练,这些数据涵盖了语言、图像、视频和网络数据等多种形式。BAGEL在标准多模态理解排行榜上超越了当前顶级的开源视觉语言模型(VLM),如Qwen2.5-VL和InternVL-2.5。同时,它在文本到图像的生成质量上与强大的专业生成器(如SD3)相媲美,并且在经典图像编辑场景中展现出比领先开源模型更优越的定性结果。更为重要的是,BAGEL扩展了自由形式的视觉操作、多视图合成和世界导航等能力,这些能力构成了超越以往图像编辑模型范围的“世界建模”任务。
BAGEL的应用场景
BAGEL的应用场景十分广泛,它不仅能够进行文本到图像的生成,还能进行图像编辑、多视图合成和世界导航等任务。例如,它可以生成由许多小汽车组成的大型汽车图像,或者在保持雕像主体不变的情况下,将其周围环境替换为特定国家的国花场景。此外,BAGEL还能够根据儿童的绘画设计生成相应的玻璃雕塑图像,并添加樱花元素以符合特定国家的文化背景。
二、方法
Mixture-of-Transformer-Experts (MoT)架构
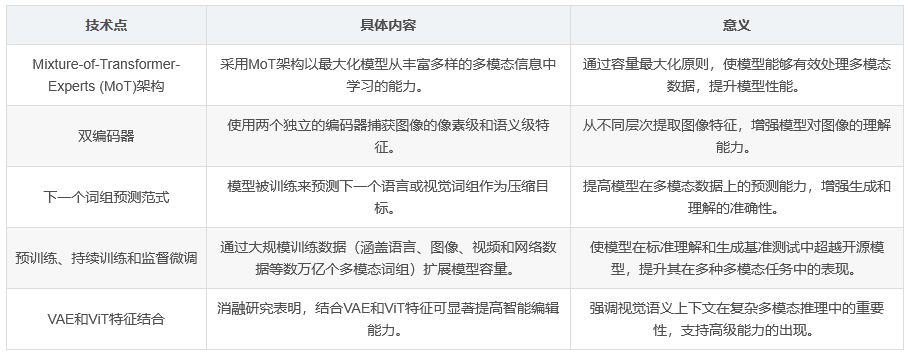
BAGEL采用了Mixture-of-Transformer-Experts (MoT)架构,以最大化模型从丰富多样的多模态信息中学习的能力。这种架构遵循容量最大化的原则,通过使用两个独立的编码器来捕获图像的像素级和语义级特征。总体框架遵循“下一个词组预测”范式,模型被训练来预测下一个语言或视觉词组作为压缩目标。
训练过程
BAGEL通过预训练、持续训练和监督微调来扩展MoT的容量,训练数据涵盖了语言、图像、视频和网络数据等数万亿个多模态词组。这种大规模的训练使BAGEL在标准理解和生成基准测试中超越了开源模型,并展示了先进的上下文多模态能力,如自由形式图像编辑、未来帧预测、3D操作、世界导航和序列推理等。
训练阶段的能力发展
随着BAGEL预训练规模的扩大,其在理解、生成和编辑任务上的性能持续提升。不同的能力在不同的训练阶段出现:多模态理解和生成能力较早出现,随后是基础编辑能力,而复杂的智能编辑能力则在后期才出现。这种分阶段的进展表明,先进的多模态推理能力是建立在良好形成的基础技能之上的。消融研究表明,结合VAE和ViT特征可以显著提高智能编辑能力,这强调了视觉语义上下文在实现复杂多模态推理中的重要性,并进一步支持了其在高级能力出现中的作用。
三、性能表现与结果
视觉理解任务
在视觉理解任务方面,BAGEL在多个测试中表现出色。例如,在MMBench测试中,BAGEL的得分为2388,高于其他模型;在MathVista测试中,BAGEL的得分为73.1,同样领先于其他模型。
文本到图像生成任务
在文本到图像生成任务的GenEval评估中,BAGEL取得了0.88的总体评分,超越了FLUX-1-dev(0.82)、SD3-Medium(0.74)和Janus-Pro-7B(0.80)等模型。
图像编辑任务
在图像编辑任务中,BAGEL在多个步骤的编辑中均表现出良好的性能。例如,在Step1X-Edit测试中,BAGEL的得分为7.36;在Gemini-2-测试中,BAGEL的得分为6.73。此外,BAGEL在图像编辑任务中的表现随着训练的深入而不断提升,BAGEL+CoT的得分为55.3,进一步证明了其在图像编辑方面的强大能力。
四、总结
BAGEL作为一种多模态基础模型,凭借其Mixture-of-Transformer-Experts (MoT)架构和大规模的多模态训练数据,在多模态理解和生成任务中展现出了卓越的性能。其在文本到图像生成、图像编辑等任务中的表现均优于当前的开源模型,并且具备了自由形式视觉操作、多视图合成和世界导航等高级能力。随着训练的深入,BAGEL的能力不断发展,从基础的多模态理解与生成到复杂的智能编辑,这表明其具有强大的多模态推理和高级能力的涌现潜力。
BAGEL核心技术汇总

















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









