






数据挖掘
数据挖掘经典算法
Apriori算法(Apriori Algoritm)
-
应用:关联规则
-
类型:无监督
-
中英文简短介绍:
- 中文:apriori算法是一种用于挖掘关联规则的经典算法,它可以在大规模数据集中快速发现频繁项集,并通过这些频繁项集生成关联规则。Aprior算法基于一个简单的思想,即一个频繁项集的所有子集都是频繁的。该算法从单元素项集开始,然后利用该性质来生成更大的候选项集,并过滤掉不频繁的项集,该算法一直迭代,直到不能再生成更大的频繁项集为止。
- Apriori algorithm is a classic algorithm for mining association rules, which can quickly discover frequent itemsets and generate association rules through these frequent itemsets in large-scale datasets. The algorithm is based on a simple idea that all subsets of a frequent itemset are frequent. The algorithm starts from single-element itemsets and uses this property to generate larger candidate itemsets and filter out infrequent ones. The algorithm iterates until it can no longer generate larger frequent itemsets.
-
算法的执行过程中英文
- 中文:
- 数据预处理:将数据集转换为项集的形式,例如购物篮数据转换为每个篮子中的商品集合。
- 初始化:从单元素项集开始,计算每个项集的支持度(即项集出现的频率),并筛选出满足最小支持度的频繁项集。
- 迭代:利用Apriori原理,从当前频繁项集中生成候选项集,并计算每个候选项集的支持度。筛选出满足最小支持度阈值的频繁项集。
- 生成关联规则:基于频繁项集,通过计算每个项集的置信度来生成关联规则。筛选出满足最小置信度阈值的关联规则。
- 英文:
- Data preprocessing:convert the dataset into the form of itemsets, such as converting shopping basket data into sets of items in each basket
- Initialization:starting from single-element itemsets,calculate the support(frequency of occurrence of the itemset) of each itemset and fliter out frequent itemsets that meet the minimum support threshold
- Iteration:use the apriori principle to generate candidate itemsets from the current frequent itemsets and calculate the support of each candidate itemset.Fliter out frequent itemsets that meet the minimum support threshold.
- generate association rules:based on frequent itemsets,generate association rules by calculating the confidence of each itemset.Fliter out association rules that meet the minimum confidence threshold.
- 中文:
-
其他:
-
什么是先验(what is the apriori)
- 先验通常指的是对于某个未知量(比如模型参数或假设)的先前知识。先验通常是在使用数据来推断未知量之前,基于领域知识、经验等信息所得到的.
- priori usually refers to the prior knowledge or belief about unknown quantity(such as model parameters or hypotheses).The prior is typically obtained based on domain knowledge, experience, or other information before using data to infer the unknown quantity.
-
优缺点:
- 优点:思想比较简单,易于实现。;可扩展性好,Apriori算法可以通过分布式计算的方式进行并行处理,从而加快数据挖掘的速度。;可解释性强,生成易于理解和解释的频繁项集和关联规则。
-
缺点:时间和空间复杂度高,当数据集非常大时,Apriori算法的计算量会非常大;处理稀疏数据效果差:当数据集比较稀疏时,Apriori算法的效果会比较差,因为算法需要对很多不频繁的项集进行计算和判断,导致计算效率低下;不支持动态数据集:Apriori算法只能处理静态数据集,不能处理动态数据集。当数据集发生变化时,需要重新构建模型和计算频繁项集和关联规则,这会导致额外的计算开销和时间成本。
-
英文:
-
Advantages: the idea is relatively simple, easy to implement. ; With good scalability, Apriori algorithm can perform parallel processing through distributed computing, thus speeding up the speed of data mining. ; Strong interpretability, generating frequent item sets and association rules that are easy to understand and interpret.
2. Disadvantages: High time and space complexity. When the data set is very large, the calculation amount of Apriori algorithm is very large. Poor effect in processing sparse data: When the data set is sparse, the Apriori algorithm has poor effect, because the algorithm needs to calculate and judge many infrequent item sets, resulting in low computing efficiency. Dynamic data sets are not supported: Apriori can only process static data sets, but cannot process dynamic data sets. When the data set changes, the need to rebuild the model and compute frequent item sets and association rules results in additional computational overhead and time costs. -
算法核心思想:
- 中文:Apriori算法体现了一种称为"先验知识"的思想,即在使用数据进行关联规则挖掘之前,基于领域知识、经验等信息,可以对待挖掘的关联规则进行先验假设。Apriori算法假设一个频繁项集的所有子集都是频繁的,这样就可以减少挖掘空间,避免枚举所有可能的关联规则,从而提高了算法的效率。
-
计算公式
S u p p o r t ( X ) = c o u n t ( X ) N C o n f i d e n c e ( A ⇒ B ) = S u p p o r t ( A ∪ B ) S u p p o r t ( A ) \begin{aligned} Support(X) &= \frac{count(X)}{N} \\ \\ Confidence(A \Rightarrow B) &= \frac{Support(A \cup B)}{Support(A)} \end{aligned} Support(X)Confidence(A⇒B)=Ncount(X)=Support(A)Support(A∪B)
支持度公式中,X代表一个项集,count(X)代表该项集在数据集中出现的次数,N表示数据集中的总记录数
置信度是指在关联规则A->B中,项集A和项集B同时出现的概率,再除以A出现的概率。其中A和B都表示项集,AUB表示项集A和项集B的并集。Support(AUB)表示项集A和项集B同时出现的次数。
-
In the support formula, X represents an itemset, count(X) represents the number of times the itemset appears in the dataset, and N represents the total number of records in the dataset. The confidence is the probability that itemsets A and B co-occur in a rule A->B, divided by the probability that itemset A appears. Both A and B represent itemsets, AUB represents the union of itemsets A and B, and Support(AUB) represents the number of times itemsets A and B co-occur. -

K均值聚类(K-Means)
- 应用:聚类
- 类型:无监督
- 中英文简短介绍
- 中文:K-means算法是一种基于距离度量的聚类算法,它将n个数据对象分为k个簇,使得每个数据对象都属于其中一个簇,且每个簇的均值(质心)最接近该簇内的所有数据对象。该算法首先随机初始化k个质心,然后对每个数据对象计算其与每个质心的距离,并将其归为距离最近的簇。接着,更新每个簇的质心,并重复执行以上过程,直到簇不再发生变化或达到预定的迭代次数。
- 英文:K-means algorithm is a distance-based clustering algorithm that divides n data objects into k clusters, where each object belongs to one of the clusters, and the mean (centroid) of each cluster is as close as possible to all data objects in that cluster. The algorithm first randomly initializes k centroids, then calculates the distance between each data object and each centroid, and assigns each object to the nearest cluster. Then, the algorithm updates the centroids for each cluster, and repeats the process until the cluster assignments do not change or until the maximum number of iterations is reached.
- 算法执行过程
- 中文:
- 初始化:随机选取k个数据对象作为初始质心
- 计算举例;对于每个数据对象,计算其与每个质心的距离,并将其划归为距离最近的簇
- 更新质心:对于每个簇,计算其所有数据对象的均值(质心), 并将其作为新的质心
- 迭代停止:判断质心是否发生变化,如果没有变化,则停止迭代,否则返回步骤2
- 英文:
- Initialization: randomly select k data objects as initial centroids;
- Distance calculation: for each data object, calculate its distance to each centroid, and assign it to the nearest cluster;
- Centroid updating: for each cluster, calculate the mean (centroid) of all data objects in the cluster, and use it as the new centroid;
- Stopping criterion: check whether the centroids have changed. If they have not changed, stop the iteration, otherwise go back to step 2.
- 中文:
- 其他
-
优缺点
- 优点:算法简单、易于实现;易于解释:K均值聚类算法生成的簇比较紧凑、分离,每个簇的中心点可以表示该簇的特征,易于解释和理解;适用性广泛:K均值聚类算法可以应用于多个领域,例如图像分割、文本聚类、推荐系统等。
- 缺点:需要确定聚类个数K:K均值聚类算法需要预先确定簇的个数K,但实际应用中往往无法确定最优的K值;对初始值敏感:K均值聚类算法对初始聚类中心点的选择非常敏感,不同的初始值可能会导致不同的聚类结果,甚至可能陷入局部最优解;不适合处理非凸形状簇的数据:K均值聚类算法假设每个簇是凸形状的,因此不适合处理非凸形状簇的数据。如果数据集中包含非凸形状簇,K均值聚类算法可能会将一个大簇分成多个小簇;对离群点敏感:K均值聚类算法对离群点非常敏感,离群点可能会影响簇的划分和中心点的计算。
- 英文:
- Advantages: The algorithm is simple and easy to implement; Easy to explain: the clusters generated by K-means clustering algorithm are compact and separated, and the central point of each cluster can represent the characteristics of the cluster, which is easy to explain and understand. Wide applicability: K-means clustering algorithm can be applied in many fields, such as image segmentation, text clustering, recommendation system, etc.
- Disadvantages: need to determine the number of clusters K : K mean clustering algorithm needs to determine the number of clusters K in advance, but often cannot determine the optimal K value in practical application; Sensitive to initial values : K-means clustering algorithm is very sensitive to the selection of initial clustering center points **, different initial values may lead to different clustering results, and may even fall into the local optimal solution; ** Not suitable for processing data of non-convex shape clusters : K-means clustering algorithm assumes that every cluster is convex shape, so it is not suitable for processing data of non-convex shape clusters. If the data set contains non-convex clusters, the K-means clustering algorithm may divide a large cluster into several smaller clusters. Sensitive to outliers : K-means clustering algorithm is very sensitive to outliers, which may affect cluster partitioning and center point calculation.
-
算法核心思想
- 中文:K-Means算法的核心思想是通过计算数据对象之间的距离,将数据对象分配到距离最近的簇中,使得每个簇内部的数据对象尽可能地相似,而不同簇之间地数据对象尽可能地不同,同时K-Means算法还通过不断更新簇地质心来优化聚类的结果。
- 英文:The core idea of K-means algorithm is to assign data objects to the nearest cluster based on their distances, so that objects within the same cluster are as similar as possible and objects across different clusters are as dissimilar as possible. Meanwhile, K-means algorithm optimizes the clustering results by continuously updating the centroids of each cluster.
-
公式:
-
时间复杂度:k均值聚类算法的时间复杂度是O(nkI*d),n是数据集的大小,k是簇的而个数,I是迭代次数,d是数据的维度,K均值聚类的时间复杂度是线性的,对于小型数据集来说,速度很快。

-
DBSCAN
-
应用:聚类
-
类型:无监督
-
中英文简介;
-
中文:
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,带有噪声的基于密度的空间聚类应用) 是一种密度聚类算法,可以自动将具有足够密度的区域划分为簇,并且可以在噪声数据周围识别出非簇点;其基本思想是将数据集中的每个点作为一个对象,在给定半径 ϵ \epsilon ϵ 和最小点数 MinPts 的条件下,通过计算点之间的距离和密度来判断每个点是否属于同一个簇。在该算法中,核心点、边界点和噪声点是三种不同的类型,核心点是指在一个以该点为中心、半径为 ϵ \epsilon ϵ 的圆内至少包含 MinPts 个点,边界点是指至少属于一个核心点的半径为 ϵ \epsilon ϵ 的圆内,但不满足成为核心点的条件,噪声点则是指既不是核心点也不是边界点的点。
-
英文:
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a density-based clustering algorithm that can automatically divide regions with sufficient density into clusters and recognize non-cluster points around noise data. Its basic idea is to treat each point in the data set as an object and judge whether each point belongs to the same cluster by calculating the distance and density between points under the condition of a given radius ϵ \epsilon ϵ and minimum point number MinPts. In this algorithm, there are three different types of points: core points, boundary points, and noise points. Core points refer to points that contain at least MinPts points within a circle centered on the point with a radius of ϵ \epsilon ϵ. Boundary points refer to points that are within a radius of ϵ \epsilon ϵ of at least one core point but do not meet the conditions to be a core point. Noise points refer to points that are neither core points nor boundary points.、
-
算法执行步骤:
- 中文:
- 选择一个未被访问的点。
- 找出该点的 ϵ \epsilon ϵ-邻域内的所有点,如果邻域内的点数不小于 MinPts,则将该点作为一个核心点。
- 将所有在该核心点的邻域内且未被访问的点标记为同一簇。
- 重复上述过程,直到所有点都被访问为止。若存在未被访问的点,返回步骤1。
- 需要注意的是,如果在步骤2中找到的邻域点不足 MinPts 个,则该点被标记为噪声点。在执行过程中,核心点可以通过邻域内点的数量来判断,边界点则是指邻域内点的数量小于 MinPts,但是至少属于一个核心点的半径为 ϵ \epsilon ϵ 的圆内,噪声点则是指既不是核心点也不是边界点的点。
- 英文:
- Choose an unvisited point.
- Find all points within the ϵ \epsilon ϵ-neighborhood of the point. If the number of points in the neighborhood is not less than MinPts, then mark the point as a core point.
- Label all unvisited points in the neighborhood of the core point as belonging to the same cluster.
- Repeat the above process until all points have been visited. If there are unvisited points, return to step 1.
- It should be noted that if less than MinPts points are found in the neighborhood during step 2, the point is marked as a noise point. During the execution process, a core point can be judged by the number of points in its neighborhood, while a border point is defined as having fewer points in its neighborhood than MinPts, but at least belonging to a circle with radius ϵ \epsilon ϵ centered on a core point. A noise point is a point that is neither a core point nor a border point.
- 中文:
-
算法优缺点;
-
中文:
- 优点:
- 能够自动发现任意形状的簇,而不需要事先指定簇的数量或形状。
- 能够处理噪声数据,将噪声点识别为噪声。
- 能够处理具有不同密度的簇。
- 缺点:
- 对于高维数据,由于所谓“维灾难”的影响,DBSCAN算法难以找到有意义的簇。
- 对于密度差异较大的数据集,容易受到参数设置的影响,需要调整半径参数和最小点数参数来获得最佳效果。
- 对于数据集中密度相同但距离较远的簇,DBSCAN算法难以将其正确地划分为不同的簇。
- 优点:
-
英文:
- Advantages:
- Able to automatically discover clusters of arbitrary shapes without the need to pre-specify the number or shape of clusters.
- Capable of handling noisy data and identifying noise points as noise.
- Capable of handling clusters with different densities.
- Disadvantages:
- For high-dimensional data, DBSCAN algorithm is difficult to find meaningful clusters due to the so-called “curse of dimensionality”.
- For datasets with significant density differences, the algorithm is sensitive to parameter settings and requires tuning of the radius and minimum points parameters to achieve optimal results.
- For clusters with similar densities but far distances in the dataset, DBSCAN algorithm may have difficulty correctly dividing them into different clusters.

- Advantages:
-
-
决策树
-
应用:分类和回归
-
类型:有监督
-
中英文简短介绍:
- 中文:决策树算法的主要思想是基于数据特征的属性值,通过逐步划分将数据集分成一些小的子集,直到子集的内部数据具有相同的分类标签或达到预先设定的停止条件。
- 英文:The main idea of decision tree algorithm is to divide the data set into some small subsets based on the attribute values of the data features, until the internal data of the subsets have the same classification label or reach the pre-set stop condition.
-
算法步骤:
-
中文:
- 特征选择:根据数据集的特征值选择最佳的划分属性,常用的划分属性选择方法包括信息增益、信息增益比、基尼系数等
- 决策树的生成:使用选定的划分属性将数据集分成若干个子集,并递归地生成决策树。
- 决策树的剪枝:使用验证集对生成的决策树进行剪枝,以避免过拟合。
- 决策树的分类:根据生成的决策树进行分类,将测试样本点从决策树的跟节点开始递归判断,直到到达叶子节点。
-
英文:
-
Feature selection: Select the best partition attribute according to the characteristic value of the data set. The commonly used partition attribute selection methods include information gain, information gain ratio, Gini index, etc.
-
Generation of decision tree: The data set is divided into several subsets using selected partition attributes and the decision tree is recursively generated.
-
Pruning of decision tree: The generated decision tree is pruned using verification sets to avoid overfitting.
-
Classification of decision tree: Classification is carried out according to the generated decision tree, and the test sample points are judged recursively from the root node of the decision tree until they reach the leaf node.
-
-
算法优缺点
-
优点:
- 适用性广泛:决策树算法可以应用于多种类型的数据集,例如数值型、离散型、连续型、类别型等。
-
缺点:
- 学习过程中存在局部最优解:决策树算法的学习过程中容易陷入局部最优解,导致生成的决策树不够准确。
- 需要预先确定决策树的最大深度、停止条件等超参数,选择不当可能影响决策树的准确性。
-
英文
- Advantages:Wide applicability: Decision tree algorithm can be applied to various types of data sets, such as numerical type, discrete type, continuous type, category type, etc.
- Disadvantages:Local optimal solution exists in the learning process: it is easy to fall into local optimal solution in the learning process of decision tree algorithm, resulting in the inaccurate decision tree generated;It is necessary to determine the maximum depth of the decision tree, stop conditions and other superparameters in advance. Improper selection may affect the accuracy of the decision tree.
-
其他
-
ID3:
-
C4.5 :C4.5 是一种决策树分类算法,由 Ross Quinlan 在 1993 年提出,是 ID3 算法的改进版。C4.5 算法使用信息增益比来选择最优特征,并使用悲观剪枝来避免过拟合。C4.5 算法可以处理连续型特征和缺失值,适用于中小型数据集。
- 特征选择:使用信息增益比来选择最优特征。信息增益比可以解决 ID3 算法在选择候选特征时对取值数目较多的特征有偏好的问题,因为它使用了对候选特征进行正规化的方法;决策树生成:将数据集根据最优特征进行划分,递归地生成决策树,直到所有的数据都被正确分类或者不能再继续划分;决策树剪枝:使用悲观剪枝来避免过拟合。悲观剪枝是一种自底向上的剪枝方法,它通过比较剪枝前和剪枝后决策树对测试数据的分类效果来确定是否进行剪枝;决策树规则后剪枝:将生成的决策树转换为一组规则,并使用规则后剪枝来避免过拟合。
- 优缺点:可以处理连续型特征和缺失值,使用信息增益比来选择最优特征,悲观剪枝可以避免过拟合。缺点包括:决策树过于复杂容易出现过拟合,对于数据分布不平衡的数据集效果不佳。
-
CART:CART 算法使用基尼指数来选择最优特征,并使用剪枝来避免过拟合。CART 算法只能处理离散型特征,适用于大型数据集。
- 特征选择:使用基尼指数来选择最优特征。基尼指数可以度量一个随机样本的分类错误率,用于评估样本的纯度,它的值越小,代表样本纯度越高,分类效果越好;决策树生成:将数据集根据最优特征进行划分,递归地生成决策树,直到所有的数据都被正确分类或者不能再继续划分;决策树剪枝:使用剪枝来避免过拟合。剪枝是一种自底向上的剪枝方法,它通过比较剪枝前和剪枝后决策树对测试数据的分类效果来确定是否进行剪枝。
- 优缺点:使用基尼指数来选择最优特征,剪枝可以避免过拟合,计算效率高,适用于大型数据集。缺点包括:只能处理离散型特征,对于数据分布不平衡的数据集效果不佳。

-
-
-
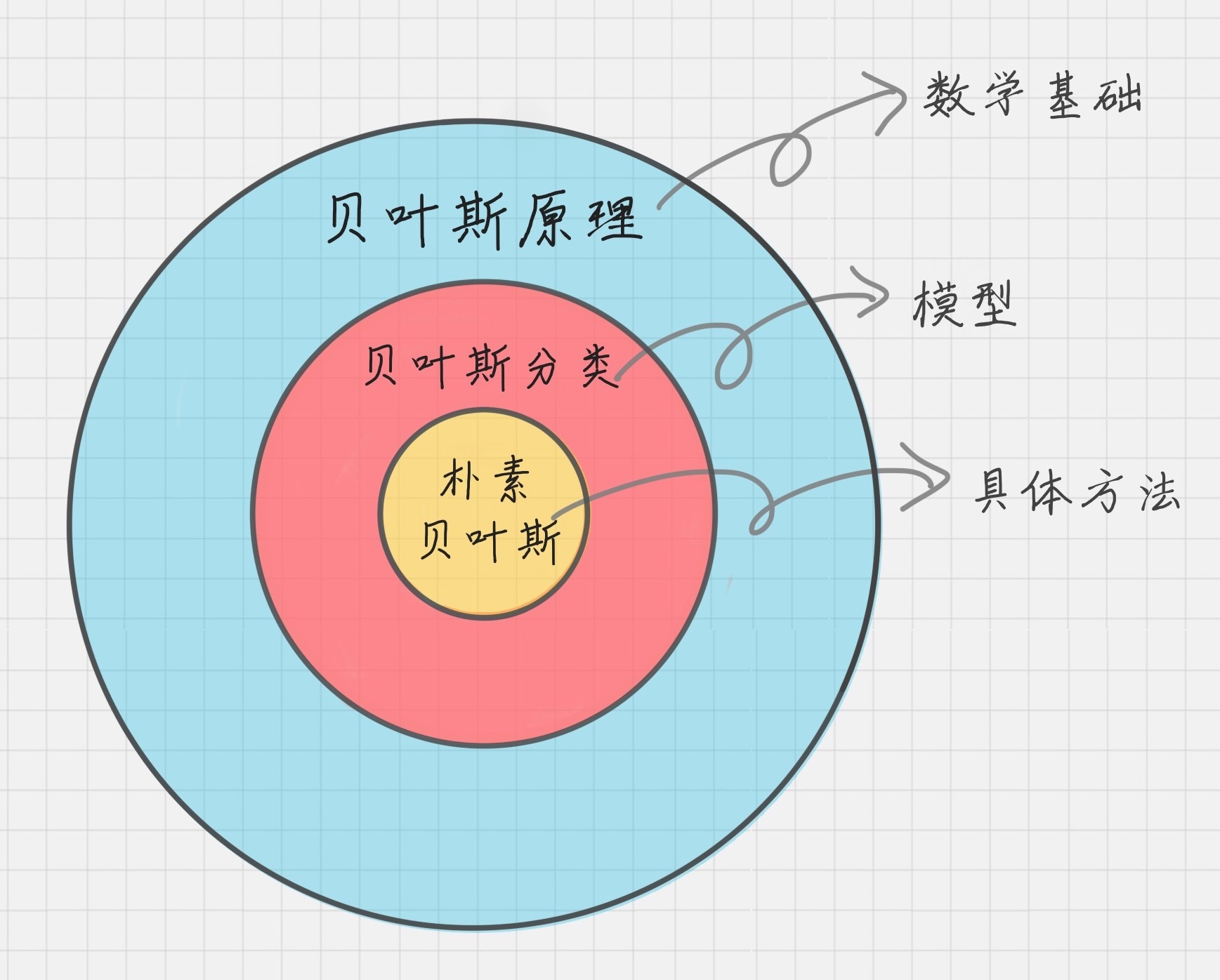
朴素贝叶斯
- 应用:分类
- 类型:有监督
- 中英文简述:
- 中文:朴素贝叶斯是一种基于概率论的分类算法,它假设各个特征之间相互独立(即朴素),并使用贝叶斯定理来计算样本属于某个类别的概率。朴素贝叶斯算法广泛应用于文本分类、垃圾邮件过滤、情感分析等领域。
- 英文:Naive Bayes is a classification algorithm based on probability theory, which assumes that each feature is independent of each other (i.e. naive), and uses Bayes’ theorem to calculate the probability that the sample belongs to a certain category. Naive Bayes algorithm is widely used in text classification, spam filtering, sentiment analysis and other fields.
- 算法步骤:
- 中文:
- 数据预处理:对原始数据进行清洗、去重、归一化等预处理操作。
- 特征选择:从预处理后的数据中选择合适的特征,去除无关或冗余的特征。
- 数据划分:将预处理后的数据划分为训练集和测试集。
- 计算先验概率:根据训练集中各个类别的样本数量计算各个类别的先验概率。
- 计算条件概率:对于每个特征,根据训练集中各个类别下该特征的出现频率,计算在各个类别下该特征的条件概率。
- 预测:对于每个测试样本,根据先验概率和条件概率,计算出该样本属于每个类别的后验概率,并选取后验概率最大的类别作为预测结果。
- 模型评估:使用测试集对模型进行评估,计算分类准确率、召回率、F1值等指标。
- 英文:
- Data preprocessing: The original data is cleaned, de-duplicated, normalized and other preprocessing operations.
- Feature selection: Select appropriate features from the preprocessed data and remove irrelevant or redundant features.
- Data partitioning: The pre-processed data is divided into training set and test set.
- Calculate prior probability: Calculate prior probability of each category according to the number of samples of each category in the training set.
- Calculation of conditional probability: For each feature, the conditional probability of the feature under each category is calculated according to the frequency of the feature under each category of the training set.
- Prediction: For each test sample, the posterior probability of the sample belonging to each category is calculated according to the prior probability and conditional probability, and the category with the largest posterior probability is selected as the prediction result.
- Model evaluation: The test set is used to evaluate the model, and the classification accuracy, recall rate, F1 value and other indicators are calculated.
- 中文:
- 算法优缺点:
- 优点:
- 计算效率高:朴素贝叶斯算法的计算量较小,速度快,适用于大规模数据的分类问题。
- 算法简单、易于实现:朴素贝叶斯算法是一种简单的分类算法,易于实现和理解。
- 可处理高维数据:朴素贝叶斯算法可以很好地处理高维数据,对于特征选择和数据预处理要求不高。
- 对缺失数据不敏感:朴素贝叶斯算法对于缺失数据不敏感,即使有些特征值缺失,仍能进行分类。
- 缺点:
- 独立性假设可能不成立:朴素贝叶斯算法的核心是条件独立性假设,这个假设在实际问题中不一定成立,可能导致分类误差增加。
- 依赖于先验概率:朴素贝叶斯算法依赖于先验概率的确定,如果先验概率不准确,将会影响分类结果。
- 对输入数据的准备方式较为敏感:朴素贝叶斯算法对于输入数据的准备方式较为敏感,需要进行适当的数据预处理和特征选择。
- 无法处理连续型数据:朴素贝叶斯算法假设特征之间相互独立,对于连续型数据需要进行离散化处理。
- 英文:
- The advantages of naive Bayes algorithm include:
- High computing efficiency: naive Bayes algorithm has a small amount of computation, fast speed, and is suitable for large-scale data classification problems.
- The algorithm is simple and easy to implement: Naive Bayes algorithm is a simple classification algorithm, easy to implement and understand.
- Processing high-dimensional data: Naive Bayes algorithm can handle high-dimensional data well, and has no high requirements for feature selection and data preprocessing.
- Insensitive to missing data: Naive Bayes algorithm is insensitive to missing data and can classify even if some eigenvalues are missing.
- Disadvantages of naive Bayes algorithm include:
- Independence assumption may not be valid: The core of naive Bayes algorithm is conditional independence assumption, which may not be valid in practical problems and may lead to increased classification errors.
- Dependent on prior probability: Naive Bayes algorithm relies on the determination of prior probability. If the prior probability is inaccurate, it will affect the classification result.
- Sensitive to the preparation of input data: Naive Bayes algorithm is sensitive to the preparation of input data, which requires appropriate data preprocessing and feature selection.
- Unable to process continuous data: Naive Bayes algorithm assumes that features are independent of each other, so discrete processing is required for continuous data.
- The advantages of naive Bayes algorithm include:
- 优点:
- 其他:
- 先验概率和后验概率:先验概率是指在考虑观测数据前,已经对概率进行了估计的概率,后验概率是指考虑了观测数据之后,对概率进行更新后的概率。
- 贝叶斯定理:贝叶斯定理是指在已知先验概率的情况下,通过观测数据更新概率的公式,是朴素贝叶斯算法的核心理论。
 (geekbang.org))
支持向量机
-
应用:分类和回归
-
类型:有监督
-
中英文简介:
-
中文:
支持向量机(Support Vector Machine,SVM)是一种常见的监督学习算法,广泛应用于分类和回归问题中。它的主要思想是在数据空间中找到一个最优的超平面,将不同类别的数据分开,从而实现分类的目的。具体来说,支持向量机的分类器是一个二分类模型,它将输入数据映射到高维空间,通过寻找一个最优的超平面(即支持向量),将不同类别的数据分开。在分类过程中,将未知的数据点映射到高维空间中,然后通过计算点到超平面的距离,来判断数据点所属的类别。
-
英文:Support Vector Machine (SVM) is a common supervised learning algorithm, widely used in classification and regression problems. Its main idea is to find an optimal hyperplane in the data space, separate different categories of data, so as to achieve the purpose of classification.Specifically, the classifier of support vector machines is a binary classification model that maps input data into a high-dimensional space and separates different categories of data by finding an optimal hyperplane (i.e. support vector). In the classification process, the unknown data points are mapped into a high-dimensional space, and then the category of the data points is determined by calculating the distance between the points and the hyperplane.
-
-
优缺点:
- 中文:
- 优点:
- 在高维空间中表现出色:SVM 可以将数据映射到高维空间中,以便于对复杂的非线性问题进行分类,从而获得更好的分类效果。
- 能够处理非线性问题:SVM 通过使用核函数(Kernel)将数据映射到高维空间中,使得SVM能够处理非线性分类问题。
- 有很好的泛化能力:SVM 的决策边界是由支持向量决定的,能够减少过拟合现象的发生。
- 在小样本数据上表现出色:SVM 可以处理小样本数据,减少训练样本数量对其性能的影响。
- 缺点:
- 对于大规模数据集和高维数据集,训练时间和存储空间消耗较大。
- 对噪声数据和缺失数据较为敏感。
- 对于核函数的选择比较敏感,不同的核函数可能会对分类结果产生不同的影响。
- 在某些情况下,SVM 的预测结果比较难以理解和解释。
- 优点:
- 英文:
- 优点:
- Excellent performance in high-dimensional space: SVM can map data into high-dimensional space, so as to facilitate the classification of complex nonlinear problems, so as to obtain better classification effect.
- Able to deal with nonlinear problems: SVM uses Kernel to map data into high-dimensional space, enabling SVM to deal with nonlinear classification problems.
- Excellent generalization ability: SVM decision boundary is determined by support vector, which can reduce the occurrence of overfitting.
- Excellent performance on small sample data: SVM can handle small sample data and reduce the impact of the number of training samples on its performance.
- 缺点:
- For large data sets and high dimensional data sets, the training time and storage space consumption is large.
- It is sensitive to noise data and missing data.
- The selection of kernel function is sensitive, and different kernel functions may have different effects on classification results.
- In some cases, SVM prediction results are difficult to understand and interpret.
- 优点:
- 中文:
-
核函数:在支持向量机(SVM)中,核函数是一种将数据点映射到高维空间的函数。SVM利用核函数将原始数据映射到高维空间,然后在高维空间中构建一个超平面,实现分类任务。核函数的选择对于SVM的性能和分类结果具有重要影响。
1. 需要根据实际问题选择合适的核函数,以获得最佳的分类效果。不同类型的问题可能需要不同类型的核函数,例如**线性核函数**、**多项式核函数**和**径向基核函**数等。
2. 需要注意核函数的参数选择,例如**径向基核函数需要选择参数 γ**,**而多项式核函数需要选择参数 d**,这些参数对于分类结果的影响非常重要。
3. 需要注意过拟合的问题,如果**核函数的复杂度过高**,可能会导致**过拟合**现象的发生。

K近邻
-
应用:分类和回归
-
类型:有监督
-
中英文简述:
- KNN(K-Nearest Neighbors)算法是一种常用的基于实例学习的监督学习算法,它通过寻找最接近目标样本的 K 个邻居来预测目标样本的类别或数值。该算法的基本思想是:如果一个样本在特征空间中的 K 个最相似的样本中,大多数属于某一个类别,那么该样本也属于这个类别;在 KNN 算法中,每个样本都表示为一个特征向量,每个特征向量有多个特征组成。在预测时,KNN 算法会计算目标样本与训练集中所有样本的距离,并选取距离最近的 K 个样本,然后根据这 K 个样本的类别,通过投票的方式来确定目标样本的类别。
- 英文:KNN (K-Nearest Neighbors) algorithm is a commonly used supervised learning algorithm based on instance-based learning. It predicts the class or value of a target sample by finding the K nearest neighbors in the feature space. The basic idea of the algorithm is that if most of the K most similar samples in the feature space belong to a certain class, then the target sample also belongs to that class.In KNN algorithm, each sample is represented as a feature vector, which consists of multiple features. During prediction, the algorithm calculates the distance between the target sample and all the samples in the training set, selects the K nearest samples, and then determines the class of the target sample by a voting mechanism based on the classes of the K nearest samples.
-
算法执行步骤
- 计算样本之间的距离:对于每个测试样本,计算它与所有训练集样本之间的距离,通常使用欧几里得距离或曼哈顿距离。
- 找到最近的K个邻居:选择距离测试样本最近的K个训练集样本。
- 确定类别:根据K个邻居的类别,使用投票的方式来确定测试样本的类别。如果是分类问题,则选择类别出现最多的邻居的类别作为测试样本的类别;如果是回归问题,则选择K个邻居的平均值作为测试样本的输出。
-
算法的优缺点:
- 中文:
- 优点:
- 适用于多分类问题。
- 对数据没有假设,对离群点不敏感。
- 缺点:
- 对于样本不平衡的数据,分类精度较低。
- 需要指定K值,K值的选择会影响分类的效果。
- 对于高维数据,样本点之间的距离容易失真。
- 优点:
- 英文
- Advantages:
- Suitable for multi-class problems.
- No assumptions about data, insensitive to outliers.
- Disadvantage:
- Low classification accuracy for imbalanced data.
- Need to specify the K value, and the choice of K value can affect the classification performance.
- For high-dimensional data, distances between samples can be distorted.
- Advantages:
- 中文:
-
其他(维灾难)
- 对于高维数据,样本点之间的距离容易失真。维度灾难指的是,随着数据维度的增加,样本点之间的距离变得越来越大,这使得在高维空间中进行数据分析变得更加困难。同时,高维数据往往会包含大量的噪声和冗余信息,这使得数据的处理和分析变得更加复杂和耗时。维度灾难是机器学习领域中一个常见的问题,需要采取合适的数据预处理和特征选择方法来降低维度,提高算法的性能和效率。
- 举个例子来说,假设我们有一组具有10个特征的数据集,其中9个特征的值都是相似的,只有1个特征值是非常大的。那么如果我们使用欧式距离来计算样本点之间的距离,那么这个特征值将会对距离计算产生非常大的影响,甚至可能使得其他9个特征对距离计算的影响被忽略,这样可能会导致我们的距离计算结果失真。这就是高维数据的“维度灾难”问题,它会导致我们的算法无法处理高维数据,因为样本点之间的距离无法准确地反映它们之间的相似性。

主成分分析
-
应用:降维
-
类型:无监督
-
中英文简述
1. 中文:PCA(Principal Component Analysis)是一种常用的**数据降维**方法,它可以将原始数据转化为**低维度**的表示,并且保留了**尽可能多的原始数据的信息**。主成分分析的主要目标是找到一组**新的变量**,这些变量是**原始变量的线性组合**,使得这组新的变量能够解释原始数据的大部分方差。这些**新的变量被称为主成分**,第一个主成分解释的方差最大,第二个主成分解释的方差次大,以此类推。PCA的基本思想是:将原始数据映射到新的坐标系中,使得在新的坐标系中,**数据的方差最大化**。这些新的坐标系由原始数据的主成分组成,它们是原始数据的**正交基**。在实际应用中,主成分分析可以用于数据可视化、数据降维、去除噪声、特征选择等领域。 2. 英文:Principal Component Analysis (PCA) is a commonly used data **dimension reduction** method. It can transform original data into **lower-dimensional** representation and retain as much information of original data as possible. The main goal of principal component analysis is to find a **new set of variables** that are **linear combinations of the original variables** such that this new set of variables explains most of the variance of the original data. **These new variables are called principal components**, with the first principal component explaining the largest variance, the second principal component explaining the next largest variance, and so on; The basic idea of PCA is to map the original data into a new coordinate system so that **the variance of the data in the new coordinate system is maximized**. These new coordinate systems are composed of principal components of the original data, which are **orthogonal bases** for the original data. In practical applications, principal component analysis can be used in data visualization, data dimension reduction, noise removal, feature selection and other fields. -
算法执行步骤
- 中文:
- 中心化数据:将数据按列进行中心化,即减去每列数据的平均值,使得每列数据的均值为0。
- 计算协方差矩阵:将中心化后的数据计算协方差矩阵,表示每两个不同的变量之间的相关性。
- 计算协方差矩阵的特征值和特征向量:求解协方差矩阵的特征值和特征向量,特征向量代表了数据在每个主成分上的投影方向。
- 选择主成分:按照特征值从大到小的顺序,选取最大的k个特征值对应的特征向量作为主成分,一般选择特征值大于1的特征向量。
- 生成新数据集:用选择出来的主成分构造新的数据集,即将中心化后的数据投影到主成分上。
- 可视化分析:将生成的新数据集进行可视化分析,帮助我们理解数据的结构和分布。
- 英文:
- Centered data: Center the data by subtracting the mean of each column from each value in the column, making the mean of each column equal to 0.
- Calculate the covariance matrix: Calculate the covariance matrix of the centered data, which represents the correlations between different variables.
- Calculate the eigenvectors and eigenvalues of the covariance matrix: Calculate the eigenvectors and eigenvalues of the covariance matrix, where the eigenvectors represent the direction of the data projection on each principal component.
- Select principal components: Select the top k eigenvectors with the largest eigenvalues in descending order as principal components, typically choosing those with eigenvalues greater than 1.
- Generate a new dataset: Construct a new dataset by projecting the centered data onto the selected principal components.
- Visualization analysis: Visualize the new dataset to help understand the structure and distribution of the data.
- 中文:
-
算法优缺点
- 中文:
- 优点:
- 去除冗余信息,提高计算效率;
- 降维后能够更好地显示数据内部的相关性;
- 可以去除噪声的影响。
- 缺点:
- 它是一个线性变换,只能找出线性关系的主成分,不能找出非线性关系的主成分;
- PCA的结果可能难以解释,因为它把原始的特征合并成新的特征;
- 对于高维数据,PCA计算量大,运算复杂度高。
- 优点:
- 英文
- Advantages:
- Eliminates redundant information and improves computational efficiency;
- Better displays internal correlations within the data after dimensionality reduction;
- Can remove the influence of noise.
- Disadvantages:
- It is a linear transformation that can only find the principal components with linear relationships, not those with nonlinear relationships;
- The results of PCA may be difficult to interpret because it combines original features into new features;
- For high-dimensional data, PCA has a large calculation workload and high computational complexity.
- Advantages:
- 中文:
-
其他:
-
中文
-
方差最大化:
在主成分分析中,“方差最大化”指的是找到一个新的坐标系,使得数据在这个坐标系下的方差最大。方差是数据分散程度的度量,因此最大化方差可以让我们找到最主要的特征,也就是最能够描述原始数据变化的那些维度。通过最大化方差,我们可以获得最具有代表性的主成分,从而将原始数据在这些主成分上进行重构。重构后的数据能够更好地描述原始数据,也可以用于数据降维、可视化、去除噪声等应用。
-
正交基:
“正交基”是指在新的坐标系中,各个主成分之间相互独立,即互相垂直,也就是正交的。正交基是数学中一种常见的概念,表示基向量之间互相独立,可以用来描述一个向量空间。在主成分分析中,我们选择的主成分就是正交基,它们可以用于描述原始数据的各个方面。
-
英文
-
Maximize variance:
In principal component analysis, “maximizing variance” refers to finding a new coordinate system that maximizes the variance of the data in that coordinate system. Variance is a measure of the degree of dispersion of the data, so maximizing variance allows us to identify the most important features, i.e., the dimensions that best describe the variation in the original data. By maximizing variance, we can obtain the most representative principal components, which can be used to reconstruct the original data along these components. The reconstructed data can better describe the original data and can be used for applications such as dimensionality reduction, visualization, noise reduction, etc.
-
Orthogonal basis:
An “orthogonal basis” refers to a set of basis vectors in a new coordinate system that are mutually independent, i.e., perpendicular to each other. Orthogonal basis is a common concept in mathematics used to describe a vector space. In principal component analysis, the principal components we select are an orthogonal basis that can be used to describe various aspects of the original data.

-
-
AdaBoost
-
应用:分类
-
类型:有监督
-
中英文简介:
-
中文:
AdaBoost(Adaptive Boosting,自适应增强算法)是一种集成学习算法,通过组合多个弱分类器来构建一个强分类器。AdaBoost是一种迭代算法,每次迭代中,它根据已有分类器的表现来调整训练数据集的权重,使得在之后的训练中,分类器更加关注那些被误分类的数据。AdaBoost主要应用于二分类和多分类问题,常用于图像识别、人脸识别、文本分类等领域。
-
英文:
AdaBoost (Adaptive Boosting) is an ensemble learning algorithm that combines multiple weak classifiers to construct a strong classifier. It is an iterative algorithm that adjusts the weights of the training dataset based on the performance of the existing classifiers, so that the classifiers focus more on the misclassified data in the subsequent training. AdaBoost is mainly used for binary and multiclass classification problems, and is commonly used in image recognition, face recognition, text classification and other fields.
-
-
算法执行过程:
-
中文:
-
给每个训练样本分配一个权重,初始时每个样本权重相等。
-
进行T轮迭代,每一轮迭代都会训练一个弱分类器:
a. 在当前样本权重下,使用一个弱分类器训练数据。
b. 计算该弱分类器的误差率。
c. 计算该弱分类器的系数。
d. 更新每个样本的权重,使得被该弱分类器分类错误的样本的权重增加,被分类正确的样本的权重减小。
-
将所有弱分类器加权组合成一个强分类器。
-
输出最终的强分类器。
-
-
英文:
-
Assign a weight to each training sample, and initially all weights are equal.
-
Conduct T rounds of iterations, and train a weak classifier in each round:
a. Train the data using a weak classifier under the current sample weight.
b. Calculate the error rate of the weak classifier.
c. Calculate the coefficient of the weak classifier.
d. Update the weight of each sample, so that the weight of the misclassified samples by the weak classifier is increased, and the weight of the correctly classified samples is decreased.
-
Combine all weak classifiers with weights to form a strong classifier.
-
Output the final strong classifier.
-
-
-
算法的优缺点:
- 中文:
- 优点:
- 可以有效地处理高维度数据,具有较高的准确性和泛化能力。
- 相对于单一的分类器,AdaBoost算法可以获得更好的分类性能。
- 缺点:
- 对于异常值和噪声数据较敏感。
- 训练时间较长,不适用于实时性要求较高的场景。
- 对于分类器性能较弱的情况,容易产生过拟合现象。
- 优点:
- 英文:
- Advantages:
- Can effectively handle high-dimensional data and has high accuracy and generalization ability.
- Compared to a single classifier, AdaBoost algorithm can achieve better classification performance.
- Disadvantages:
- Sensitive to outliers and noisy data.
- Long training time, not suitable for scenarios with high real-time requirements.
- For weak classifier performance, it is prone to overfitting.
- Advantages:
- 中文:
-
其他(集成学习)
集成学习(Ensemble Learning)是指将多个分类器(或回归器)的输出结果进行整合,以获得比单个分类器更好的分类性能的一种机器学习技术。集成学习的核心思想是通过结合多个模型的预测结果,减少预测误差和提高预测精度。常用的集成学习方法包括Bagging、Boosting、Stacking等。
Ensemble learning is a machine learning technique that combines the outputs of multiple classifiers (or regressors) to achieve better classification performance than any individual classifier. The core idea of ensemble learning is to reduce prediction error and improve prediction accuracy by combining the prediction results of multiple models. Common ensemble learning methods include Bagging, Boosting, Stacking, etc.
PageRank
-
应用:排序 链接分析
-
类型:无监督学习
-
中英文简介
-
中文:
PageRank是一种计算网页重要性的算法,最初由Google公司的创始人之一Larry Page和Sergey Brin于1998年提出。它的基本思想是基于图的链接结构来计算网页的重要性,将网页之间的链接看做一张有向图,通过对链接的结构进行分析和计算,可以得出每个网页的排名。排名高的网页通常具有更高的质量和价值。
PageRank的计算过程是一个迭代的过程,通过不断更新每个网页的得分,直到收敛为止。PageRank算法考虑到了每个页面的入链和出链数量以及入链页面的权重,并将这些信息结合在一起,计算每个页面的PageRank得分。除此之外,PageRank算法还考虑了链接页面的重要性,以及链接页面和被链接页面之间的距离等因素。
PageRank算法广泛应用于搜索引擎等领域,被视为衡量网页重要性的重要指标之一。
-
英文:
PageRank is an algorithm for calculating the importance of web pages, initially proposed by one of the co-founders of Google, Larry Page and Sergey Brin in 1998. Its basic idea is to calculate the importance of web pages based on the graph link structure, considering each link between web pages as a directed graph. By analyzing and calculating the link structure, the rank of each web page can be obtained. Web pages with high rank usually have higher quality and value.
The calculation process of PageRank is an iterative process, continuously updating the score of each web page until it converges. The PageRank algorithm takes into account the number of inbound and outbound links of each page, the weight of inbound pages, and combines this information to calculate the PageRank score of each page. In addition, the PageRank algorithm also considers the importance of linking pages, and the distance between the linking pages and linked pages.
PageRank algorithm is widely used in search engines and other fields, and is regarded as an important indicator for measuring the importance of web pages.
-
-
算法执行步骤:
- 中文:
- 确定初始的页面分数。对于一个具有n个页面的网络,初始分数可以为 1 / n 1/n 1/n。
- 根据链接情况计算每个页面的贡献值。一个页面的贡献值是由其它页面指向该页面的链接数和这些页面的分数决定的。具体地,一个页面的贡献值为它们指向该页面的所有页面的分数之和,除以这些页面指向链接的总数。
- 更新每个页面的分数。计算公式为:新的页面分数 = 阻尼因子 + (1 - 阻尼因子) * 页面的贡献值之和。其中,阻尼因子是一个介于0和1之间的数,表示用户不会一直停留在一个页面,而是有一定的概率跳转到其它页面。
- 重复执行步骤2和3,直到每个页面的分数收敛为止。
- 英文:
- Determine the initial page scores. For a network with n pages, the initial score can be set to 1 / n 1/n 1/n.
- Calculate the contribution of each page based on its link structure. The contribution of a page is determined by the number of links pointing to it and the scores of those pages. Specifically, the contribution of a page is the sum of the scores of all pages that link to it, divided by the total number of links those pages have.
- Update the scores of each page. The formula is: new page score = damping factor + (1 - damping factor) * sum of contributions from linking pages. The damping factor is a number between 0 and 1 that represents the likelihood of a user navigating away from the current page.
- Repeat steps 2 and 3 until the scores of all pages converge.
- 中文:
-
算法优缺点:
- 中文:
- 优点:
- 能够更加客观地反映页面的权重和质量;
- 考虑了页面之间的链接结构和链接质量;
- 能够有效地过滤垃圾信息和作弊行为。
- 缺点:
- 计算复杂度较高,需要大量的计算资源和时间;
- 对于规模较大的网络,收敛速度较慢,需要更长的时间才能得到结果;
- 容易被操纵,例如人为地增加链接数来提高页面的排名。
- 优点:
- 英文:
- Advantages:
- Can reflect the weight and quality of pages more objectively;
- Takes into account the link structure and link quality between pages;
- Able to effectively filter out spam information and cheating behavior.
- Disadvantages:
- High computational complexity, requiring a large amount of computing resources and time;
- Slow convergence speed for large-scale networks, requiring more time to obtain results;
- Vulnerable to manipulation, such as artificially increasing the number of links to improve page ranking.
- Advantages:
- 中文:
EM算法
-
应用:聚类
-
类型:无监督
-
中英文简介:
-
中文:
EM算法(Expectation-Maximization Algorithm)是一种常用于概率模型参数估计的迭代算法。它是一种求解含有隐变量的概率模型参数的有效方法,应用广泛,例如在聚类、图像分割、文本处理等领域中。
EM算法基于最大似然估计的思想,通过迭代求解似然函数的极大值来获得参数的最优估计值。
-
英文:
The EM algorithm (Expectation-Maximization Algorithm) is an iterative algorithm commonly used for estimating the parameters of probabilistic models. It is an effective method for solving the parameter estimation problem of probabilistic models with latent variables, and has broad applications in fields such as clustering, image segmentation, and text processing.
Based on the idea of maximum likelihood estimation, the EM algorithm iteratively seeks the maximum likelihood of the likelihood function to obtain the optimal estimate of the parameters.
-
-
执行过程:
-
中文:
- E步骤(Expectation):计算隐变量的后验概率(条件概率)。
- M步骤(Maximization):最大化对数似然函数,计算模型参数的最优值。
重复执行以上两个步骤,直到收敛,即似然函数的变化量小于设定的阈值为止。由于EM算法基于最大似然估计的思想,因此可以用于许多概率模型的参数估计,例如高斯混合模型、隐马尔可夫模型等。
-
英文:
- E-step (Expectation): Calculate the posterior probabilities (conditional probabilities) of the latent variables.
- M-step (Maximization): Maximize the log-likelihood function to obtain the optimal values of model parameters.
Repeat the above two steps until convergence, that is, until the change in the likelihood function is smaller than the set threshold. Since the EM algorithm is based on the maximum likelihood estimation, it can be used for parameter estimation of many probabilistic models, such as Gaussian mixture models, hidden Markov models, etc.
-
-
模型优缺点;
-
中文:
- 优点:
- 适用范围广:EM算法可以用于估计含有隐变量的概率模型参数,适用于许多领域,例如聚类、图像分割、文本处理等;
- 鲁棒性较强:EM算法可以处理数据中的噪声和缺失值等问题,因为它能够考虑隐变量的影响;
- 模型灵活性强:EM算法可以用于估计多种概率模型,例如高斯混合模型、隐马尔可夫模型等;
- 缺点:
- 收敛速度慢:由于EM算法需要进行迭代计算,因此收敛速度较慢,特别是在数据量较大的情况下;
- 容易陷入局部最优解:由于EM算法是基于局部搜索的方法,因此有可能会陷入局部最优解,导致估计的参数不是全局最优解;
- 对初始值敏感:EM算法的性能很大程度上取决于初始值的选择,不同的初始值可能会导致不同的结果。
- 优点:
-
英文:
- Advantages:
- Wide applicability: The EM algorithm can be used to estimate the parameters of probability models that contain hidden variables, and is applicable to many fields, such as clustering, image segmentation, and text processing.
- Strong robustness: The EM algorithm can handle problems such as noise and missing values in the data, because it takes into account the influence of hidden variables.
- Flexibility: The EM algorithm can be used to estimate the parameters of various probability models, such as Gaussian mixture models and hidden Markov models.
- Disadvantages:
- Slow convergence: Because the EM algorithm requires iterative calculations, the convergence speed is relatively slow, especially when dealing with large datasets.
- Susceptibility to local optimal solutions: As the EM algorithm is based on local search methods, it may be susceptible to local optimal solutions, leading to suboptimal parameter estimates.
- Sensitive to initial values: The performance of the EM algorithm depends to a large extent on the choice of initial values, and different initial values may lead to different results.
- Advantages:
-
L1正则化与L2正则化
统计学
基础统计概念
假设检验
什么是假设检验?请简述假设检验的基本原理和流程。
-
中文:
假设检验是一种基于统计学的方法,用于检验某个统计模型的假设是否符合实际情况。在假设检验中,我们通常会制定一个原假设和一个备择假设,然后通过收集样本数据来判断原假设是否成立。具体地,我们会计算出一个检验统计量,然后与一个临界值比较,从而得出原假设被接受还是被拒绝的结论。
-
英文:
Hypothesis testing is a statistical method used to test whether a statistical model hypothesis fits the actual situation. In hypothesis testing, we usually formulate a null hypothesis and an alternative hypothesis, and then collect sample data to determine whether the null hypothesis is true. Specifically, we calculate a test statistic, and compare it with a critical value, in order to accept or reject the null hypothesis.
-
流程
- 确定原假设和备择假设:在进行假设检验之前,需要先确定要检验的假设。通常情况下,我们会制定一个原假设(通常是不变的、常规的、无差异的假设)和一个备择假设(通常是我们想要验证的假设),并根据实际问题来选择适当的假设。
- 选择合适的检验统计量:在确定了原假设和备择假设之后,需要选择一个合适的检验统计量,用于比较样本数据和假设之间的差异。不同的检验问题需要选择不同的检验统计量。
- 确定显著性水平:显著性水平是指在检验过程中所接受的误差率,通常设定为0.05或0.01。它表示我们拒绝原假设的最小概率阈值。
- 计算检验统计量的值:使用已有的样本数据,计算出选定的检验统计量的值。
- 计算临界值:根据显著性水平和假设检验的类型,计算出与显著性水平对应的临界值,用于比较检验统计量的值。
- 判断原假设是否被拒绝:将计算出的检验统计量的值与临界值进行比较,如果检验统计量的值小于临界值,就接受原假设,否则拒绝原假设,接受备择假设。
原假设和备择假设有什么区别?它们的作用分别是什么?
原假设(Null Hypothesis,H0)通常是一种默认的假设,它假定不存在任何显著差异或效应。在假设检验中,我们会尝试验证这种假设是否成立。如果我们在验证过程中得到的结论是拒绝原假设,则可以推断出存在某种显著差异或效应。
备择假设(Alternative Hypothesis,H1或HA)则是我们所希望验证的假设。通常,备择假设是在原假设不成立的前提下提出的,它代表了可能存在的显著差异或效应。在假设检验中,如果我们拒绝原假设,则可以认为备择假设成立。
什么是显著性水平?它与假设检验有什么关系?
显著性水平(Significance Level)是指在假设检验中所设置的拒绝原假设的概率阈值,通常用 α 表示。它反映了犯错的风险或错误接受原假设的风险。
在进行假设检验时,我们需要设置显著性水平,以判断假设检验结果是否显著。通常情况下,我们会将显著性水平设定在 0.05 或 0.01 等较小的值。这意味着,如果得到的检验结果的 p 值小于等于显著性水平,则我们将拒绝原假设,否则我们接受原假设。
显著性水平与假设检验密切相关,它可以影响到我们对假设的接受或拒绝。**如果显著性水平设置得太高,那么我们可能会错误地接受原假设,从而得出不准确的结论;如果显著性水平设置得太低,那么我们可能会错误地拒绝原假设,从而导致失去一些有用的信息。**因此,显著性水平的设置需要在保证统计推断准确性的前提下,尽量考虑研究的具体情况和数据类型。
什么是p值?p值的大小与假设检验的结果有什么关系?
p值(p-value)是假设检验中的一个重要统计量,用于描述检验统计量或样本数据所提供的证据程度。p值是指在原假设成立的情况下,得到比实际观察到的结果更极端的概率,通常用一个小数表示。
在假设检验中,如果得到的 p 值小于等于事先设定的显著性水平(如0.05或0.01),则我们拒绝原假设,认为备择假设更加合理。反之,如果得到的 p 值大于显著性水平,我们则接受原假设,认为数据对原假设的支持较强。
p值的大小与假设检验结果的关系可以表述为以下几点:
- p值小于设定的显著性水平,说明检验结果显著,我们应该拒绝原假设。
- p值大于设定的显著性水平,说明检验结果不显著,我们应该接受原假设。
- p值越小,表示得到比实际观察到的结果更极端的概率越小,证据越充分,拒绝原假设的可能性越大。
- p值越大,表示得到比实际观察到的结果更极端的概率越大,证据越不充分,接受原假设的可能性越大。
总之,p值的大小与假设检验的结果密切相关,它是判断原假设是否成立的重要指标之一。p值越小,则越有理由拒绝原假设,接受备择假设。
请举例说明假设检验在实际研究中的应用,并简要介绍该应用中的假设和检验过程。
假设检验在实际研究中有着广泛的应用,以下是一个例子,以说明在具体研究中如何应用假设检验。
假设有一家医院想要评估一种新药物是否对疾病的治疗有显著效果。在这个例子中,我们可以制定以下两个假设:
- 原假设(Null Hypothesis):新药物对疾病的治疗没有显著效果。
- 备择假设(Alternative Hypothesis):新药物对疾病的治疗有显著效果。
为了测试这个假设,医院可以将患者分为两组:一个接受新药物治疗的实验组和一个接受传统治疗的对照组。然后,我们可以通过检验两组患者在治疗后疾病恢复的程度,来比较新药物治疗和传统治疗之间的差异。
我们可以使用一个双样本t检验来比较两组之间的均值差异。具体来说,我们可以计算两组的均值和标准差,然后计算t值和p值,来检验新药物治疗和传统治疗之间的差异是否显著。
如果得到的p值小于设定的显著性水平(例如0.05),则我们拒绝原假设,接受备择假设,认为新药物治疗和传统治疗之间存在显著差异。如果p值大于显著性水平,我们则接受原假设,认为新药物治疗和传统治疗之间的差异不显著。
总之,假设检验可以帮助我们在实际研究中验证我们的假设,从而得出一些有价值的结论,例如,新药物治疗是否更加有效。在假设检验中,我们需要根据具体情况制定原假设和备择假设,选择合适的检验方法,并设置显著性水平来做出决策。
检验
t检验
-
中英文简介
-
中文:
T检验是一种用于比较两个样本均值是否有显著差异的统计方法。通常用于分析两个样本之间的差异,比如比较一个治疗组和一个对照组的均值是否有显著差异,或者比较两个时间点的均值是否有显著差异。
T检验分为独立样本T检验和配对样本T检验两种。独立样本T检验用于比较两个独立的样本之间的均值差异,而配对样本T检验则用于比较同一组样本在不同时间点或条件下的均值差异。
在T检验中,我们通过计算t值(t-statistic)来判断两个样本均值是否有显著差异。t值越大,表示两个样本均值之间的差异越显著。我们还需要计算p值(p-value),p值越小,表示差异越显著,一般当p值小于0.05时,认为差异是显著的。
T检验是一种简单而有效的统计方法,广泛应用于各种实验和研究中。
-
英文:
T-test is a statistical method used to compare whether there is a significant difference between the means of two samples. It is commonly used to analyze differences between two samples, such as comparing the mean of a treatment group and a control group, or comparing the mean at two different time points.
There are two types of T-tests: independent samples T-test and paired samples T-test. The independent samples T-test is used to compare the mean difference between two independent samples, while the paired samples T-test is used to compare the mean difference of the same group of samples at different time points or under different conditions.
In T-tests, we use the t-value to determine whether there is a significant difference between the means of the two samples. The larger the t-value, the more significant the difference between the means. We also calculate the p-value, and the smaller the p-value, the more significant the difference. Generally, when the p-value is less than 0.05, we consider the difference to be significant.
T-test is a simple and effective statistical method widely used in various experiments and research.
-
-
使用场景
- 检验两个独立样本的均值是否存在显著差异:例如比较两个不同群体的平均数(例如男性和女性的平均身高)是否存在显著差异。
- 检验一个样本的均值与一个已知值是否存在显著差异:例如检验一组学生的平均成绩是否显著高于某一标准分数。
- 检验两个相关样本的均值是否存在显著差异:例如比较同一组人的两次测试分数是否存在显著差异。
- 检验回归分析中自变量系数是否显著不为零:例如判断某一自变量对因变量的影响是否显著。
-
使用前提:
- 中文:
- 数据符合正态分布
- 方差相等,满足方差齐性
- 英文:
- The data follow a normal distribution.
- The variances are equal, satisfying homogeneity of variance.
- 中文:
-
t检验的结论
-
中文:
在t检验中,我们通常根据计算出的t值和p值,来对比两个样本均值是否有显著差异。一般情况下,可以按照以下方式表述T检验的结论:
- 当p值小于显著性水平(一般为0.05)时,我们拒绝原假设(即两个样本的均值相等),并认为差异是显著的,可以得出结论:“存在显著差异"或"拒绝原假设”。
- 当p值大于显著性水平时,我们无法拒绝原假设(即两个样本的均值相等),不能认为差异是显著的,可以得出结论:“不存在显著差异"或"接受原假设”。
另外,在给出结论时,还需要同时考虑t值的大小和正负号。如果t值为正,说明样本1的均值大于样本2的均值;如果t值为负,说明样本1的均值小于样本2的均值。因此,可以在结论中添加更具体的描述,例如:"样本1的均值显著高于样本2的均值"或"样本1的均值显著低于样本2的均值"等。
-
英文:
-
In t-test, we usually compare the means of two samples by calculating the t-value and p-value. The conclusion of t-test can be stated as follows:
- When the p-value is less than the significance level (usually 0.05), we reject the null hypothesis (that the means of the two samples are equal) and conclude that there is a significant difference between the means, which can be expressed as “significant difference exists” or “reject the null hypothesis”.
- When the p-value is greater than the significance level, we cannot reject the null hypothesis and conclude that there is no significant difference between the means, which can be expressed as “no significant difference exists” or “accept the null hypothesis”.
In addition, when giving the conclusion, we also need to consider the magnitude and sign of the t-value. If the t-value is positive, it indicates that the mean of sample 1 is greater than the mean of sample 2; if the t-value is negative, it indicates that the mean of sample 1 is less than the mean of sample 2. Therefore, we can add more specific descriptions in the conclusion, such as “the mean of sample 1 is significantly higher than that of sample 2” or “the mean of sample 1 is significantly lower than that of sample 2”, etc.
-
-
-
公式
独立样本 T 检验的公式为: t = X ˉ 1 − X ˉ 2 s p 1 n 1 + 1 n 2 其中, X ˉ 1 和 X ˉ 2 分别是两个样本的均值, n 1 和 n 2 分别是两个样本的大小, s p 是两个样本方差的合并估计量,计算公式为: s p = ( n 1 − 1 ) s 1 2 + ( n 2 − 1 ) s 2 2 n 1 + n 2 − 2 配对样本 T 检验的公式为: t = D ˉ s D / n D ˉ 是样本差值的均值, s D 是样本差值的标准差, n 是样本大小。 独立样本T检验的公式为: \\ t = \frac{\bar{X}_1 - \bar{X}_2}{s_p \sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}\\ 其中,\bar{X}_1和\bar{X}_2分别是两个样本的均值,n_1和n_2分别是两个样本的大小,s_p是两个样本方差的合并估计量,计算公式为:\\ s_p = \sqrt{\frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1+n_2-2}}\\ \\ 配对样本T检验的公式为:\\ t = \frac{\bar{D}}{s_D / \sqrt{n}}\\ \bar{D}是样本差值的均值,s_D是样本差值的标准差,n是样本大小。 独立样本T检验的公式为:t=spn11+n21Xˉ1−Xˉ2其中,Xˉ1和Xˉ2分别是两个样本的均值,n1和n2分别是两个样本的大小,sp是两个样本方差的合并估计量,计算公式为:sp=n1+n2−2(n1−1)s12+(n2−1)s22配对样本T检验的公式为:t=sD/nDˉDˉ是样本差值的均值,sD是样本差值的标准差,n是样本大小。
F检验
-
简介:
-
中文:
F检验是一种常用的统计方法,用于检验多个总体方差是否相等,是一种基于方差分析(ANOVA)的统计方法。F检验的原理是通过比较多个样本的方差之间的比值,来检验这些样本是否来自方差相等的总体。
-
英文:
F-test is a commonly used statistical method, which is used to test whether multiple population variances are equal, based on the principle of analysis of variance (ANOVA). The F-test compares the ratio of variances between multiple samples to determine whether these samples come from populations with equal variances.
-
-
应用场景:
- 检验多个组别的平均数是否有显著差异:例如比较不同药品对疾病治疗效果的差异,或比较不同年龄组别的身高是否存在差异。
- 检验回归模型的拟合是否显著:例如检验一个自变量回归模型的拟合效果是否优于一个只包含截距项的模型。
- 检验多个总体方差是否相等:例如比较不同制造商生产的产品的方差是否相等。
-
使用前提:
- 样本来自正态分布或近似正态分布的总体。
- 样本之间相互独立,即不同样本之间的观察值相互独立。
- 各组样本的方差相等或近似相等。
- 数据的测量尺度应该至少是区间或比例水平的。
-
公式:
F = MSB MSW 其中, F 表示 F 检验统计量, M S B 表示组间均方差, M S W 表示组内均方差。 组间均方差是各组均值与总体均值之间的平方和除以组数减一,组内均方差是各组方差的平均值。 F 检验的原理是比较组间均方差和组内均方差的大小,来判断组之间方差是否显著不同。 F = \frac{\text{MSB}}{\text{MSW}}\\ 其中,F表示F检验统计量,\mathrm{MSB}表示组间均方差,\mathrm{MSW}表示组内均方差。\\ 组间均方差是各组均值与总体均值之间的平方和除以组数减一,组内均方差是各组方差的平均值。\\ F检验的原理是比较组间均方差和组内均方差的大小,来判断组之间方差是否显著不同。 F=MSWMSB其中,F表示F检验统计量,MSB表示组间均方差,MSW表示组内均方差。组间均方差是各组均值与总体均值之间的平方和除以组数减一,组内均方差是各组方差的平均值。F检验的原理是比较组间均方差和组内均方差的大小,来判断组之间方差是否显著不同。
-
F检验和t检验的异同:
- 异:
- 应用场景不同:t检验通常用于比较两个独立样本或一个样本和一个已知值之间的均值差异,而F检验则用于比较多个组别或因素之间的均值差异或方差差异。
- 检验目标不同:t检验的目标是比较两个样本或群体的均值差异是否显著,而F检验则是比较多个组别或因素的均值差异或方差差异是否显著。
- 计算方法不同:t检验的计算方法基于样本均值和标准差,而F检验则基于样本的方差和均值比。
- 同:
- 都需要满足一定的前提条件,如样本来自正态分布总体、样本方差齐性等。
- 都是基于假设检验的方法,需要设置显著性水平和检验统计量,通过比较检验统计量和临界值来判断假设是否成立。
- 异:















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}