






1. 大语言模型基础
1.1. 通往AGI之路——大语言模型
1.1.1. 语言模型发展史
- 百亿参数LLM历史
-
OpenAI:GPT-3、Codex、InstruGPT、ChatGPT、GPT-4;
-
Google:T5(严格来说属于bert时代,不属于大模型)、PaLM、Bard;
-
Facebook:OPT、LLaMA;
-
清华大学:GLM

-
- 语言模型各阶段:
- 统计语言模型(马尔可夫假设,ngram语言模型)
- 神经语言模型(Word2vec、表示学习)
- 预训练语言模型 PLM (ELMO、Bert、GPT2、预训练+微调)
- 大语言模型 LLM (GPT3、CahtGPT)
- LLM和PLM的区别:
- LLM表现出的涌现能力是PLM不具备的;
- LLM重新定义了人机交互的方式;(prompt指令)
- LLM的开发模糊了科研与工程的界限;(算法模型 + 分布式训练/大数据处理)
- LLM带来的“革命”:
- NLP领域,LLM统一了各种NLP子任务,NLP范式发生变革;
- 信息检索领域,传统的搜索引擎受到挑战,例如new bing;
- CV领域,很多人开始研究视觉语言模型,处理多模态对话,如GPT4;
- 互联网APP,构建于LLM之上,高效办公,如office365 Copilot;
- LLM的涌现能力:
- In-context learning能力;
- 指令遵循能力;
- 逐步推理能力(链式思考能力);
- LLM 还需解决的问题:
- LLM 涌现能力产生的原因还需探索;
- 训练成本巨大;
- 将LLM与人类的价值观(诚信、守法、反歧视等)或偏好对齐很难;
1.1.2. GPT家族
- GPT-1(2018):
- 奠定了预训练+微调的范式;
- 奠定了GPT系列模型的基座(transformer deocoder + 自回归);
- GPT-2(2019):
- 模型扩大到10亿,预训练数据也很多;
- 不微调就可以运行各种nlp任务;
- 将所有NLP任务统一为单词预测(文本生成)问题;
- 但是效果一般;
- GPT-3(2020):
- 模型扩大到千亿;
- 涌现出In-context learning能力、指令遵循能力、简单推理的能力;
- 被认为是范式从PLM到LLM迁移的革命;
- GPT-3.5(2021):
- 通过增加github代码数据,提升了复杂推理、链式思考能力;
- 使用基于人类反馈的强化学习算法(RLHF)对齐人类偏好;
- 指令微调,大大提高LLM遵循指令的能力;
- ChatGPT(2022)
- 以对话形式训练GPT-3.5,以chatbot形式出现;
- 几乎无所不能(海量知识储备、数学推理、精准多轮对话、和人类价值观对齐);
- 几个月火遍全世界,改写了AI历史;
- GPT-4(2023)
- 多模态输入(文本、图片同时输入);
- 比ChatGPT的涌现能力更强;
- 花了6个月进行对齐微调;
1.1.3. LLM预训练
- 数据来源:
- 网页数据(获取多语言知识)
- 对话数据(提升对话能力)
- 书籍(提升长文本处理能力)
- 科学文本(论文 科技书 数学网页,提升科学推理能力)
- 代码(提升复杂推理、链式思考能力)
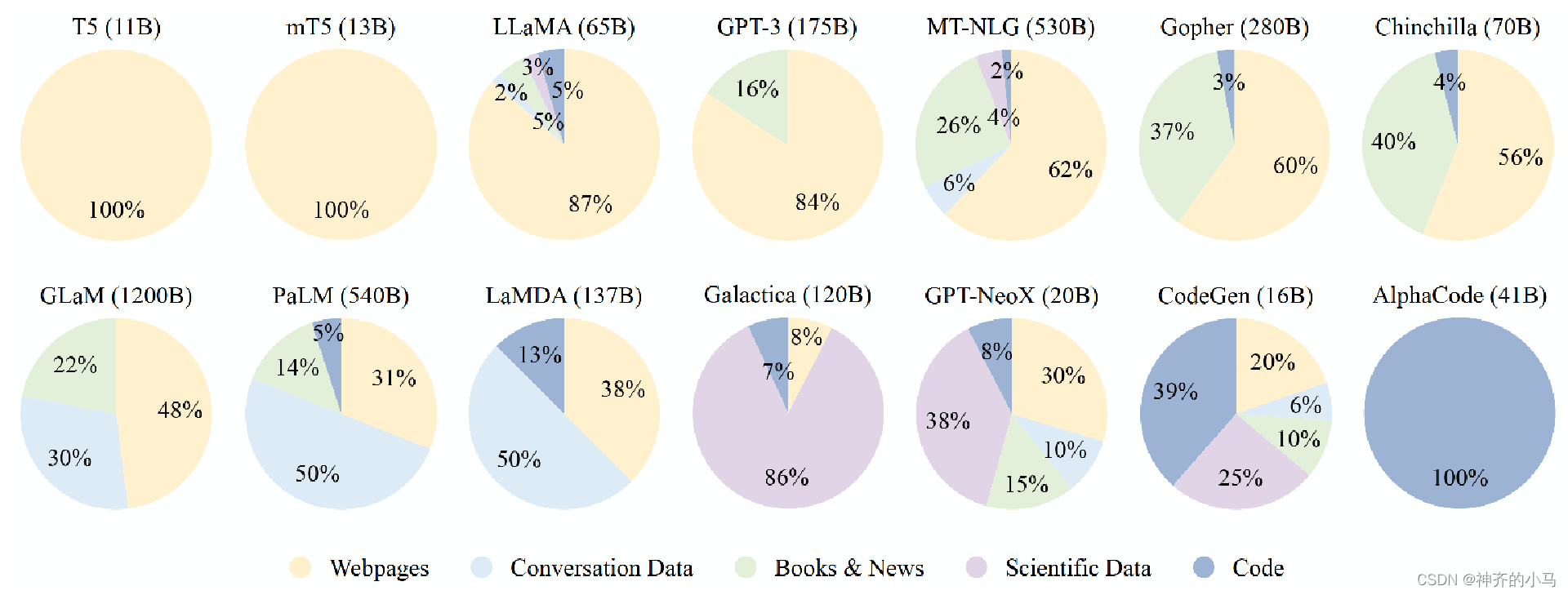
- 数据预处理:

- 数据质量极其重要,可以: 1. 过滤无关语言的文档; 2. 基于困惑度检测非正常句子; 3. 根据标点分布、句子长度等统计,过滤低质量文本; 4. 根据html标签、链接、歧视辱骂关键词等,删除文本段;
- LLM架构:
- 大多数 LLM使用 Pre Layer Norm,使用绝对位置编码(Learned)或者相对位置编码(Relative),GeLU激活函数或其变体,上下文长度在2048

- 大多数 LLM使用 Pre Layer Norm,使用绝对位置编码(Learned)或者相对位置编码(Relative),GeLU激活函数或其变体,上下文长度在2048

- 预训练任务:
- 自回归语言模型(逐字预测)
- 降噪自编码(还原噪声)
- 预训练参数:
- 大多数LLM: BatchSize逐渐增加、学习率比较小、使用了warmup(学习率前期很小,训练过程中逐渐增加到设定值,这是为了防止参数随机初始化到斜率很高的地方,导致模型拟合慢)、学习率会衰减、 使用Adam类优化器、使用混合精度加速训练、使用了权重衰减、 使用了梯度截断、dropout设置为0.1
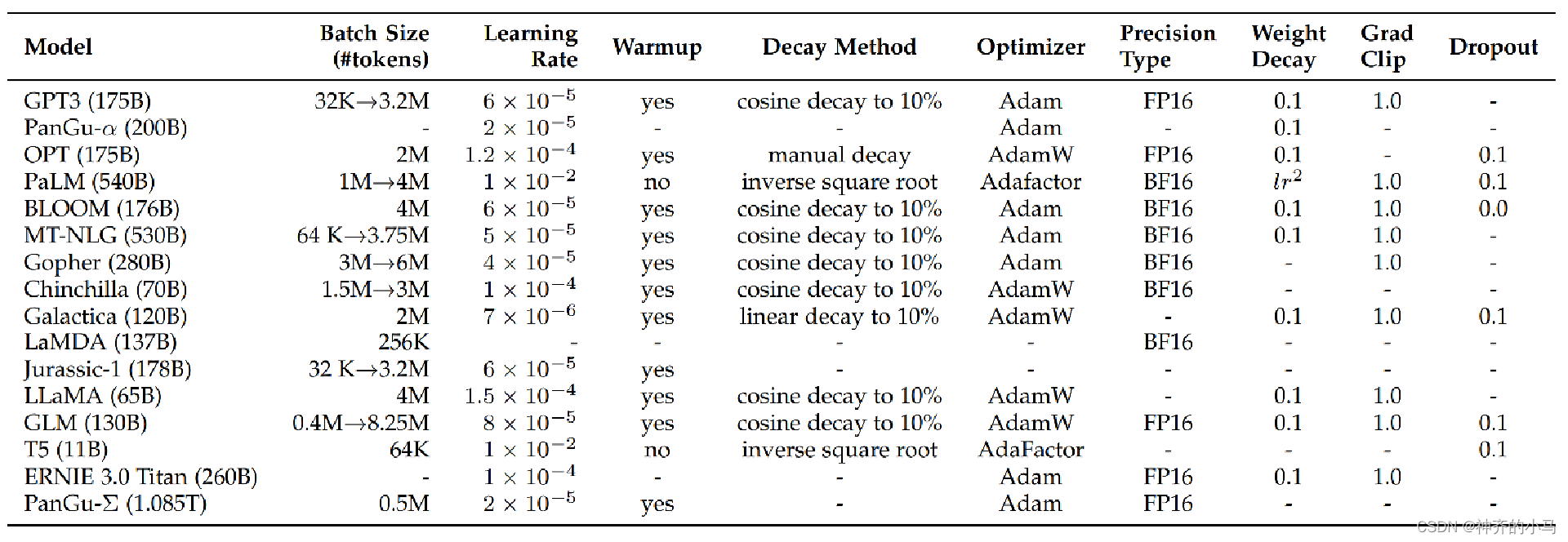
- 大多数LLM: BatchSize逐渐增加、学习率比较小、使用了warmup(学习率前期很小,训练过程中逐渐增加到设定值,这是为了防止参数随机初始化到斜率很高的地方,导致模型拟合慢)、学习率会衰减、 使用Adam类优化器、使用混合精度加速训练、使用了权重衰减、 使用了梯度截断、dropout设置为0.1
-
混合精度训练(加快收敛):
- 参数以FP32存储;
- 正向计算过程中,遇到FP16算子,需要把算子输入和参数从FP32转换成FP16进行计算;
- 将Loss层设置为FP32进行计算;
- 反向计算过程中,首先乘以Loss Scale值,避免反向梯度过小而产生下溢;
- FP16参数参与梯度计算,其结果将被转换回FP32;
- 除以loss scale值,还原被放大的梯度;
- 判断梯度是否存在溢出,如果溢出则跳过更新,否则优化器以FP32对原始参数进行更新。
1.1.4. LLM微调
- 微调分类:
- Instruction Tuning(指令微调):提升模型遵循人类指令执行任务的能力
- Alignment Tuning(对齐微调): 保持模型和人类的价值观或偏好对齐
- Efficient Tuning(效率微调):只更新部分参数,减小完整微调的成本
- 指令微调(样本格式:表示已有数据,人工手写的数据):
- 指令微调对解锁LLM的能力至关重要;
- 使用了指令微调的小模型的效果有可能会超过未微调的大模型;(关于GPT4大小的猜测?)
- 指令微调使LLM可以处理未见过的任务(训练集里面未出现此任务的指令及问答对儿);
- 指令微调使LLM可以克服以下弱点:
- 重复生成或者重复问题;
- 补全问题,而不是回答问题;
- 指令微调可以泛化到跨语言任务上;(问题用中文、答案回英文)

-
对齐微调——RLHF算法:
-
标准:有用性,一定是在帮用户解决问题;诚实性,知道自己的能力边界、不撒谎;无害性,不应该攻击或歧视、应该拒绝违法或犯罪请求;
-
三要素:
-
需要对齐的预训练模型;
-
基于人类反馈学习的奖励模型;
-
模型输出一个反应人类偏好的数值;
-
奖励模型一般是LM的较小版本,如6B的GPT3;
-
-
一个强化学习算法;(PPO)
-
-
- 效率微调:
- LoRA被广泛应用到开源LLM(如LLaMA、BLOOM)上
- Low-Rank Adaption(LoRA) 在每个linear层,对训练参数施加低秩约束。
- 一般的参数更新为:W = W + ∆W,LoRA:
- 首先冻结原始矩阵W(大模型的W维数很高);
- 然后用两个分解后的矩阵A、B去近似∆W,
- 其中: A∈R^m∗k B∈R^n∗k ∆W=A∙B^T k≪min(m,n)
1.2. 论文精读
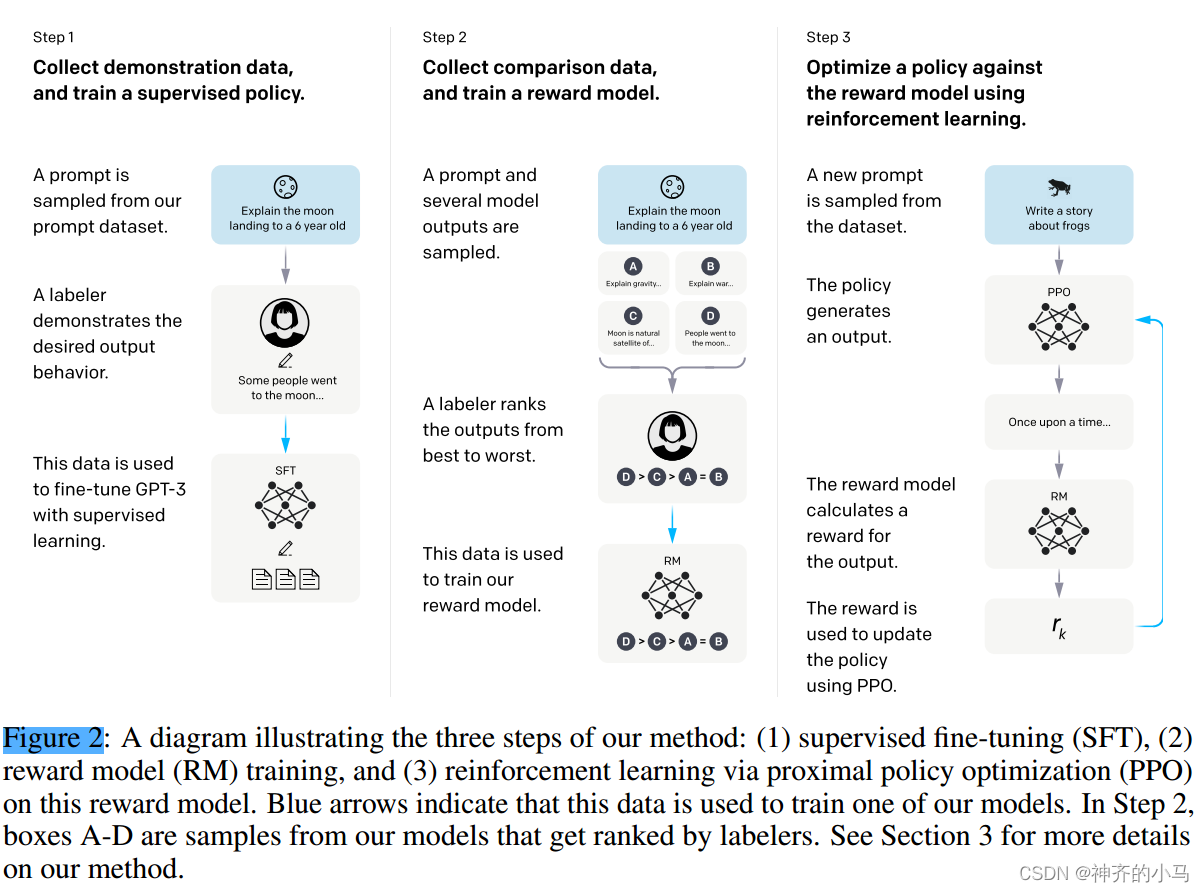
1.2.1. InstructGPT(2022)
- 论文题目:Training language models to follow instructions with human feedback
- 论文地位:首次提出RLHF算法(基于人类反馈的强化学习)来微调LLM(GPT3),InstructGPT作为ChatGPT的前身,在指令微调、对齐微调(生成安全性)方面表现出色,证明了较小规模的模型在经过微调后在特定任务上性能可能优于较大规模模型。














 1778
1778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









