







中文开源LLM汇总评测
模型推理
建议使用通用的模型推理工具包运行推理,一般都提供较好的UI以及兼容OpenAI 的API。常见的有:
- https://github.com/lm-sys/FastChat
- https://github.com/oobabooga/text-generation-webui
- https://github.com/ggerganov/llama.cpp
- https://github.com/nomic-ai/gpt4all
- https://github.com/vllm-project/vllm
其中
- 兼容性最好的是 text-generation-webui,支持 8bit/4bit 量化加载、GPTQ 模型加载、GGML 模型加载、Lora 权重合并、OpenAI 兼容API、Embeddings模型加载等功能,推荐!
- 苹果 M 系列芯片,推荐用 llama.cpp
- 开箱即用,选择 gpt4all,有桌面端软件。
注:如果模型参数过大无法加载,可以在 HuggingFace 上寻找其 GPTQ 4-bit 版本,或者 GGML 版本(支持Apple M系列芯片)。
目前30B规模参数模型的 GPTQ 4-bit 量化版本,可以在 24G显存的 3090/4090 显卡上单卡运行推理。
Base模型
值得关注的支持中文的开源 Base 模型(同类模型中选效果最好的、参数最大的)
| 名称 | 类型 | 参数量 | 上下文 | License | 地址 |
|---|---|---|---|---|---|
| Aquila-7B | Base | 7B | 2048 tokens | 商用 | https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila/Aquila-pretrain |
| Ziya-LLaMA-13B-Pretrain-v1 | Base | 13B | 2048 tokens | 非商用 | https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-Pretrain-v1 |
| Chinese-LLaMA-33B | Base | 33B | 2048 tokens | 非商用 | https://github.com/ymcui/Chinese-LLaMA-Alpaca |
| baichuan-7B | Base | 7B | 4096 tokens | 商用(需申请) | https://github.com/baichuan-inc/baichuan-7B |
不同模型的 token 对应的中文字符数不同,一般来说专门为中文设计的模型,其词表较大,相同中文字符数使用的 token 数量相比于 OpenAI (1 字符 2 token)较小,约为平均 1 字符 1 token。
Chat 模型
值得关注的支持中文的开源 Chat 模型(同类模型中选效果最好的)
| 名称 | 类型 | 参数量 | 上下文 | License | 地址 |
|---|---|---|---|---|---|
| BELLE-LLaMA-EXT-13B | SFT | 13B | 2048 tokens | 非商用 | https://github.com/LianjiaTech/BELLE |
| Chinese-Alpaca-Plus-13B | SFT | 13B | 2048 tokens | 非商用 | https://github.com/ymcui/Chinese-LLaMA-Alpaca |
| ChatGLM-6B | SFT | 6B | 2048 tokens | 非商用 | https://github.com/THUDM/ChatGLM-6B |
| Ziya-LLaMA-13B-v1.1 | SFT | 13B | 2048 tokens | 非商用 | https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1.1 |
| AquilaChat-7B | SFT | 7B | 2048 tokens | 商用 | https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila/Aquila-chat |
| WizardLM-30B-V1.0 | SFT | 30B | 2048 tokens | 非商用 | https://huggingface.co/WizardLM/WizardLM-30B-V1.0 |
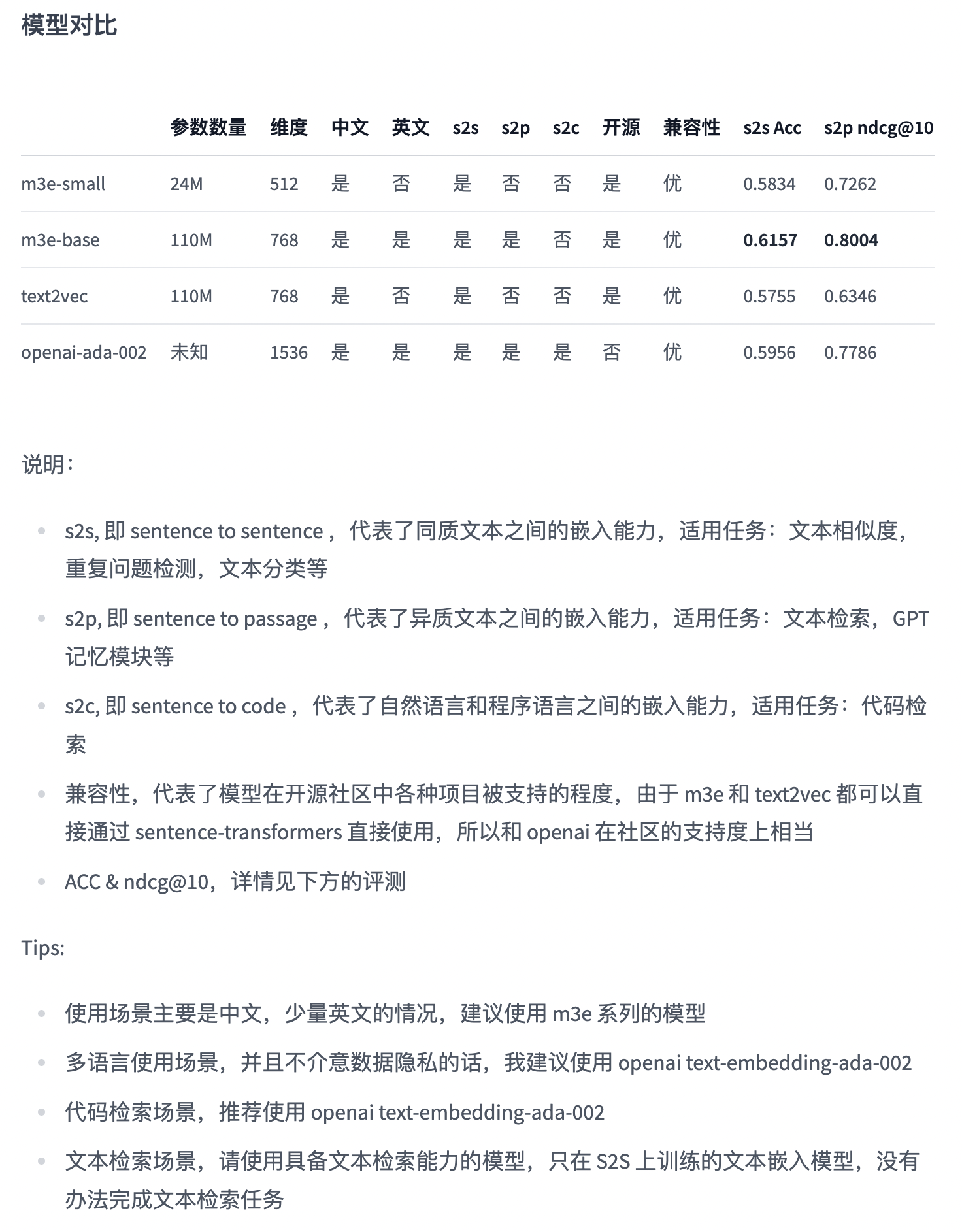
Embeddings 模型
用来替代 OpenAI 的 Embeddings 模型:
- m3e-base: 效果最好,非商用
- text2vec-large-chinese:可商用
Training Pipeline
OpenAI训练GPT的过程,具有参考意义















 2455
2455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









