







经过上次的KV cache量化后,我们发下显存占用有了明显的下降,证明我们的量化达到了一定成果,本篇继续介绍进行的W4A16 量化工作
W4A16 量
1.量化步骤
W4A16中的A是指Activation,保持FP16,只对参数进行 4bit 量化。使用过程也可以看作是三步。
第一步:同 KV Cache第一步
第二步:量化权重模型。利用第一步得到的统计值对参数进行量化,具体又包括两小步:
- 缩放参数。主要是性能上的考虑(回顾 PPT)。
- 整体量化。
第二步的执行命令如下:
# 量化权重模型 lmdeploy lite auto_awq \ --model /root/share/temp/model_repos/internlm-chat-7b/ \ --w_bits 4 \ --w_group_size 128 \ --work_dir ./quant_output
命令中 w_bits 表示量化的位数,w_group_size 表示量化分组统计的尺寸,work_dir 是量化后模型输出的位置。这里需要特别说明的是,因为没有 torch.int4,所以实际存储时,8个 4bit 权重会被打包到一个 int32 值中。所以,如果你把这部分量化后的参数加载进来就会发现它们是 int32 类型的。
最后一步:转换成 TurboMind 格式。
# 转换模型的layout,存放在默认路径 ./workspace 下
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128
这个 group-size 就是上一步的那个 w_group_size。如果不想和之前的 workspace 重复,可以指定输出目录:--dst_path,比如:
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128 \
--dst_path ./workspace_quant
接下来和上一节一样,可以正常运行前面的各种服务了,不过咱们现在用的是量化后的模型。
最后再补充一点,量化模型和 KV Cache 量化也可以一起使用,以达到最大限度节省显存。
2.量化效果
官方在 NVIDIA GeForce RTX 4090 上测试了 4-bit 的 Llama-2-7B-chat 和 Llama-2-13B-chat 模型的 token 生成速度。测试配置为 BatchSize = 1,prompt_tokens=1,completion_tokens=512,结果如下表所示。
| model | llm-awq | mlc-llm | turbomind |
|---|---|---|---|
| Llama-2-7B-chat | 112.9 | 159.4 | 206.4 |
| Llama-2-13B-chat | N/A | 90.7 | 115.8 |
可以看出,TurboMind 相比其他框架速度优势非常显著,比 mlc-llm 快了将近 30%。
另外,也测试了 TurboMind 在不同精度和上下文长度下的显存占用情况,如下表所示。
| model(context length) | 16bit(2048) | 4bit(2048) | 16bit(4096) | 4bit(4096) |
|---|---|---|---|---|
| Llama-2-7B-chat | 15.1 | 6.3 | 16.2 | 7.5 |
| Llama-2-13B-chat | OOM | 10.3 | OOM | 12.0 |
可以看出,4bit 模型可以降低 50-60% 的显存占用,效果非常明显。
总而言之,W4A16 参数量化后能极大地降低显存,同时相比其他框架推理速度具有明显优势。
实机进行W4A16 量化
先导入环境变量,去huggingface的镜像网站进行下载。
export HF_ENDPOINT=https://hf-mirror.comlmdeploy lite auto_awq merged --work-dir internlm2-chat-7b-4bit使用该命令进行量化,其他的参数使用默认值
量化之后,运行模型查看量化结果(量化模型和 KV Cache 量化也可以一起使用,以达到最大限度节省显存。因此我们采用结合KV Cache的量化)
量化结果:
结合KV cache=0.5运行模型:
lmdeploy chat internlm2-chat-7b-4bit --model-format awq --cache-max-entry-count 0.5 --meta-instruction "你是考研政治题库,内在是InternLM-7B大模型。你将对考研政治单选题,多选题以及综合题 做详细、耐心、充分的解答,并给出解析。"
查看模型运行成果,占用显存:15977MB,明显比只是用KV Cache时有了更多的下降。
结合KV cache=0.01运行模型:
lmdeploy chat internlm2-chat-7b-4bit --model-format awq --cache-max-entry-count 0.01 --meta-instruction "你是考研政治题库,内在是InternLM-7B大模型。你将对考研政治单选题,多选题以及综合题 做详细、耐心、充分的解答,并给出解析。"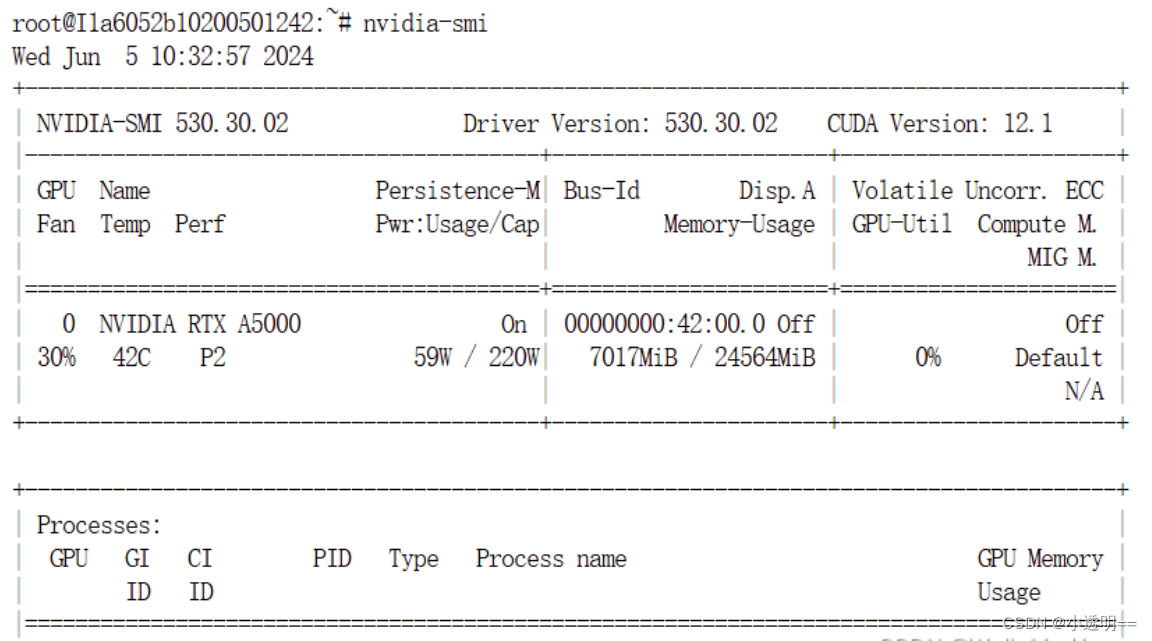
查看模型运行成果:显存占用大幅度降低,仅为7017MB,量化成果非常明显。
总结
在进行W4A16量化后得到了新的模型,再结合KV Cache量化后模型运行时占用的显存有了非常大幅度的下降,证明我们再存储占用方面取得了很好的量化成果,这也让我们对模型速度,精度等有了更多的考虑,后续会进行更多测试得到数据结果。

















 2115
2115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









