







1. 背景
如何求解非凸优化问题,一直是无数学者冥思苦想的问题。事实上,一般的非凸优化问题大概率是NP-hard的,所以,除非P=NP,否则想要用通用的求解方法来在有限时间内求解,几乎是不可能的。然而,对于非凸优化中相对比较简单的部分,我们可以找到一些转换方法,来巧妙地进行求解。比如混合0-1非凸二次规划(mixed binary nonconvex quadratic program),就可以用本文介绍的共正规划(Copositive Programming,CP)方法来解决。
具体来说,CP是半定规划 (Semidefinite Programming, SDP)的一个推广,通过CP方法,混合0-1非凸二次规划问题可以被转化成一个有线性目标函数且带completely positive约束的凸问题。这一转换方法适用于许多组合优化、鲁棒优化问题的模型特点,为解决这些问题提供了一种思路。
本文借鉴了https://zhuanlan.zhihu.com/p/34772469的结构,并在此文的基础上,对CP的思路做了更详细的解释,并进行了延伸和拓展。因为篇幅有限,证明过程请读者参阅参考文献。
2. 如何用共正规划求解二次非凸优化问题
在正式介绍CP之前,我们先定义以下的记号。我们定义
C
q
:
=
{
X
∈
R
q
×
q
:
X
=
X
T
,
v
T
X
v
≥
0
,
∀
v
∈
R
+
q
}
\mathcal{C}_q:=\left\{X\in\mathbb{R}^{q\times q}: X=X^T, v^TXv\geq 0, \forall v\in \mathbb{R}_+^q\right\}
Cq:={X∈Rq×q:X=XT,vTXv≥0,∀v∈R+q}
为
q
q
q阶共正矩阵(Copositive Matrix)的集合;定义
C
q
∗
:
=
{
X
∈
R
q
×
q
:
X
=
∑
k
∈
[
K
]
z
k
(
z
k
)
T
f
o
r
s
o
m
e
f
i
n
i
t
e
{
z
k
}
k
∈
[
K
]
⊂
R
+
q
}
\mathcal{C}_q^*:=\left\{X\in\mathbb{R}^{q\times q}: X=\sum_{k\in [K]}z^k(z^k)^T \quad {\rm{for \ some \ finite\ }} \{z^k\}_{k\in[K]} \subset \mathbb{R}^q_+ \right\}
Cq∗:=⎩
⎨
⎧X∈Rq×q:X=k∈[K]∑zk(zk)Tfor some finite {zk}k∈[K]⊂R+q⎭
⎬
⎫
为
q
q
q阶全正(Completely positive Matrix)的集合。不难发现,
C
q
\mathcal{C}_q
Cq和
C
q
∗
\mathcal{C}_q^*
Cq∗都是锥。同时,可以证明
C
q
\mathcal{C}_q
Cq和
C
q
∗
\mathcal{C}_q^*
Cq∗互为对偶锥 (Burer, 2008)。
C
q
\mathcal{C}_q
Cq和
C
q
∗
\mathcal{C}_q^*
Cq∗的对偶性正是CP问题的根本所在。
2.1 引入:一维空间
考虑一维优化问题
v
∗
:
=
min
H
11
x
1
2
+
2
g
1
x
1
s.t.
−
1
≤
x
1
≤
1
\begin{gathered} v^* := &\min \ H_{11} x_1^2 + 2g_1 x_1 \\ &\text{s.t.} \quad -1 \leq x_1 \leq 1 \end{gathered}
v∗:=min H11x12+2g1x1s.t.−1≤x1≤1
为了解决这个问题,可以使用标准的微积分方法,分析在
(
−
1
,
1
)
(-1, 1)
(−1,1)区间内的关键点处的二次目标函数
H
11
x
1
2
+
2
g
1
x
1
H_{11}x_1^2 + 2g_1x_1
H11x12+2g1x1,以及端点
−
1
-1
−1 和
1
1
1 处的值。然而,在这里我们寻求一个等价的凸优化问题。令
F
:
=
{
x
1
:
−
1
≤
x
≤
1
}
\mathcal{F}:=\{x_1:-1\leq x\leq 1\}
F:={x1:−1≤x≤1},这个问题可以被等价地转化成
v
∗
=
min
H
11
X
11
+
2
g
1
x
1
s.t.
x
1
∈
F
,
X
11
=
x
1
2
\begin{gathered} v^* = &\min & H_{11} X_{11} + 2 g_1 x_1 \\ &\text{s.t. } & x_1 \in F, \quad X_{11} = x_1^2 \end{gathered}
v∗=mins.t. H11X11+2g1x1x1∈F,X11=x12
在这个基础上,我们可以再来做一步松弛,得到一个更简洁的约束条件
v
∗
=
min
H
11
X
11
+
2
g
1
x
1
s.t.
x
1
2
≤
X
11
≤
1
\begin{gathered} v^* = &\min & H_{11} X_{11} + 2 g_1 x_1 \\ &\text{s.t. } & x_1^2\leq X_{11} \leq 1 \end{gathered}
v∗=mins.t. H11X11+2g1x1x12≤X11≤1
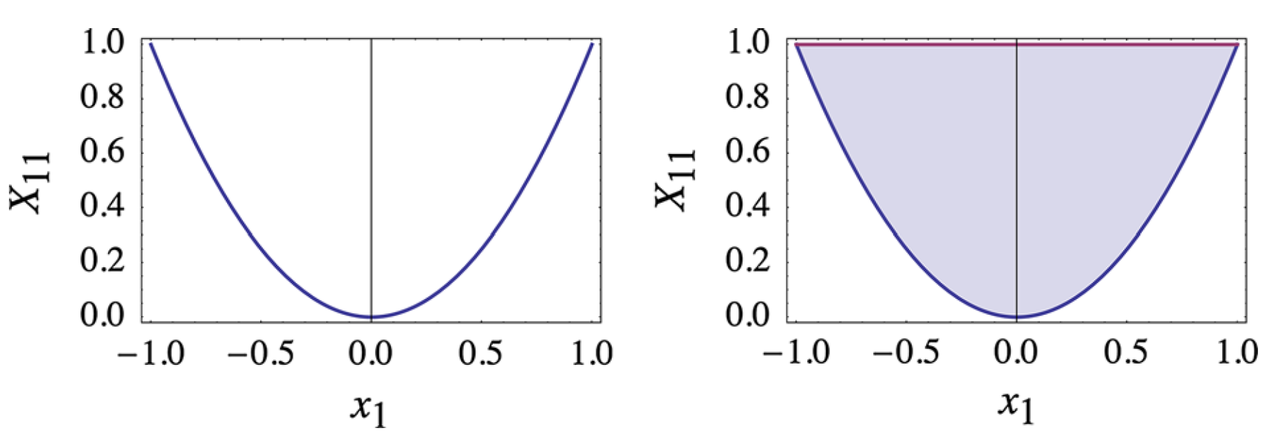
这个松弛的几何意义如下图所示,简单来说,我们将
(
x
1
,
X
11
)
(x_1,X_{11})
(x1,X11)从左图的
x
1
∈
F
x_1\in \mathcal{F}
x1∈F,
x
1
2
=
X
11
x_1^2=X_{11}
x12=X11放松到了一个convex hull上。如此一来,
x
1
x_1
x1和
X
11
X_{11}
X11可以被视为两个变量来处理,目标函数变成线性,同时,很容易验证这个松弛保持了最优值的不变。同时,我们还注意到,虽然右图中的最优值对应的
(
x
1
,
X
11
)
(x_1,X_{11})
(x1,X11)不一定唯一,但是所有的最优值都属于一个convex hull。这些性质会延续到后面的推广中。
2.2 拓展到二维和三维空间
下面我们考虑以下的二维问题
v
∗
=
min
⟨
H
,
X
⟩
+
2
⟨
g
,
x
⟩
s.t.
A
x
≤
b
,
X
=
x
x
T
,
x
∈
R
2
\begin{gathered} v^* = &\min & \langle H,X \rangle + 2\langle g,x \rangle \\ &\text{s.t. } & Ax \leq b,\ X=xx^T,\ x\in \mathbb{R}^2 \end{gathered}
v∗=mins.t. ⟨H,X⟩+2⟨g,x⟩Ax≤b, X=xxT, x∈R2
这里,
⟨
P
,
Q
⟩
=
t
r
a
c
e
(
Q
P
)
=
∑
i
∈
[
n
]
∑
j
∈
[
n
]
p
i
j
q
i
j
\langle P, Q \rangle = {\rm{trace}}(QP)=\sum_{i\in[n]}\sum_{j\in[n]}p_{ij}q_{ij}
⟨P,Q⟩=trace(QP)=∑i∈[n]∑j∈[n]pijqij。我们还要求
A
∈
R
3
×
2
A\in\mathbb{R}^{3 \times 2}
A∈R3×2,
b
∈
R
3
b\in \mathbb{R}^3
b∈R3,这使得这个问题的可行域是一个三角形(不失一般性,我们假设可行域非空)。我们记
G
0
:
=
{
(
x
,
x
x
T
)
:
x
∈
F
}
\mathcal{G}_0:=\{(x,xx^T):x \in \mathcal{F} \}
G0:={(x,xxT):x∈F},其中
F
\mathcal{F}
F是
x
x
x的可行域。类似一维的情况,我们希望能将
G
0
\mathcal{G}_0
G0做松弛,同时解除
X
=
x
x
T
X=xx^T
X=xxT的约束,将该问题的目标函数变成线性的。一个自然的做法是,将
G
0
\mathcal{G}_0
G0松弛为
G
:
=
c
o
n
v
‾
{
(
x
,
x
x
T
)
:
x
∈
F
}
\mathcal{G}:= \overline{\rm{conv}}\{(x,xx^T):x \in \mathcal{F} \}
G:=conv{(x,xxT):x∈F}。
做松弛之后,我们发现,在
d
i
m
(
A
)
≤
3
{\rm{dim}}(A)\leq3
dim(A)≤3的时候,我们可以证明,
G
\mathcal{G}
G可以被等价地转换成以下的形式(
P
⪰
0
P \succeq 0
P⪰0表示矩阵
P
P
P是正半定的):
G
=
{
(
x
,
X
)
:
Y
⪰
0
,
C
Y
C
T
≥
0
}
,
w
h
e
r
e
Y
=
(
1
x
T
x
X
)
,
C
=
(
b
,
−
A
)
.
\mathcal{G}=\left\{ (x,X): Y \succeq 0, CYC^T \geq 0 \right\}, {\rm where \ } Y = \begin{pmatrix} 1 & x^T \\ x & X \end{pmatrix}, \ C = (b, -A).
G={(x,X):Y⪰0,CYCT≥0},where Y=(1xxTX), C=(b,−A).
因此,原问题也就被松弛为:
v
∗
=
min
⟨
H
,
X
⟩
+
2
⟨
g
,
x
⟩
s.t.
b
b
T
−
A
x
b
T
−
b
x
T
A
T
+
A
X
A
T
≥
0
(
1
x
T
x
X
)
⪰
0.
\begin{array}{lll} v^* = &\min & \langle H,X \rangle + 2\langle g,x \rangle \\ &\text{s.t.} &bb^T-Axb^T-bx^TA^T+AXA^T \geq 0 \\ &&\begin{pmatrix} 1 & x^T \\ x & X \end{pmatrix} \succeq 0. \end{array}
v∗=mins.t.⟨H,X⟩+2⟨g,x⟩bbT−AxbT−bxTAT+AXAT≥0(1xxTX)⪰0.
我们还关心这个松弛是不是紧的,即松弛后的最优值是否和原问题的最优值相等。事实上,这个松弛实际上符合正半定规划(Semidefinite Programming,SDP)的形式,而SDP正是CP问题的一个特例,因此这个松弛的强对偶性质可以由SDP的相关方法得到。
同时,由于 d i m ( A ) ≤ 3 {\rm{dim}}(A)\leq3 dim(A)≤3时,上面的转换都成立,所以以上方法可以自然地推广到三维空间。
2.3 拓展到更高维度的空间&0-1变量
我们继续考虑更高维度的空间,由于取消了维度限制,我们可以通过引入松弛变量的方式把不等式约束转换成等式约束,并允许部分变量为0-1变量。因此我们讨论以下的mixed binary nonconvex quadratic program问题:
v
∗
=
min
⟨
H
,
X
⟩
+
2
⟨
g
,
x
⟩
s.t.
a
i
T
x
=
b
i
,
∀
i
∈
[
m
]
X
=
x
x
T
{
x
j
∈
{
0
,
1
}
,
∀
j
∈
B
x
j
≥
0
,
∀
j
∈
[
n
]
\
B
\begin{array}{lllll} v^* = &\min & \langle H,X \rangle + 2\langle g,x \rangle \\ &\text{s.t. } & a_i^T x = b_i, \quad \forall i \in [m] \\ && X = x x^T\\ && \left\{ \begin{array}{lll} x_j \in \{0,1\}, &\forall j \in B \\ x_j \geq 0, &\forall j \in [n] \backslash B \end{array} \right. \end{array}
v∗=mins.t. ⟨H,X⟩+2⟨g,x⟩aiTx=bi,∀i∈[m]X=xxT{xj∈{0,1},xj≥0,∀j∈B∀j∈[n]\B
类似低维的情况,我们也可以为这个问题找到一个松弛,即
v
∗
=
min
⟨
H
,
X
⟩
+
2
⟨
g
,
x
⟩
s.t.
a
i
T
x
=
b
i
,
∀
i
∈
[
m
]
a
i
T
X
a
i
=
b
i
2
∀
i
∈
[
m
]
x
j
=
X
j
j
,
∀
j
∈
B
(
1
x
T
x
X
)
∈
C
1
+
n
∗
\begin{array}{lllll} v^* = &\min & \langle H,X \rangle + 2\langle g,x \rangle \\ &\text{s.t. } & a_i^T x = b_i, \quad \forall i\in[m] \\ && a_i^T X a_i = b_i^2 \quad \forall i\in[m] \\ && x_j = X_{jj}, \quad \forall j \in B\\ && \begin{pmatrix} 1 & x^T \\ x & X \end{pmatrix} \in \mathcal{C}_{1+n}^* \end{array}
v∗=mins.t. ⟨H,X⟩+2⟨g,x⟩aiTx=bi,∀i∈[m]aiTXai=bi2∀i∈[m]xj=Xjj,∀j∈B(1xxTX)∈C1+n∗
相比于更低维度的问题,我们同样解除了二次约束
X
=
x
x
T
X=xx^T
X=xxT,将原问题转化成一个有线性目标函数且带completely positive约束的凸问题。关于强对偶性质,我们可以证明,两个问题的最优解是相同的。同时,如果
(
x
∗
,
X
∗
)
(x^*,X^*)
(x∗,X∗)是原问题的一个最优解,则
x
∗
x^*
x∗一定在松弛问题的最优解集的convex hull里。由于篇幅限制,具体的证明过程无法在此处展开,读者可以参考。
2.4 讨论:以上的问题为什么叫copositive programming
到目前为止,我们似乎都没有用到
C
q
\mathcal{C}_q
Cq这个所谓的copositive matrices集合,那么为什么以上这套转换方法被称为copositive programming呢?其实,上述quadratic programming问题是copositive programming的一个特例。首先,copositive programming的标准形式是:
v
∗
=
min
⟨
H
,
X
⟩
s.t.
⟨
A
i
,
X
⟩
=
c
i
,
∀
i
∈
[
m
]
X
∈
C
q
.
\begin{array}{lllll} v^* = &\min & \langle H,X \rangle \\ &\text{s.t.} & \langle A_i, X \rangle = c_i, \quad \forall i \in [m] \\ && X\in \mathcal{C}_q. \end{array}
v∗=mins.t.⟨H,X⟩⟨Ai,X⟩=ci,∀i∈[m]X∈Cq.
对于(2.6)中的问题(先不考虑0-1约束),我们令
A
i
=
a
i
a
i
T
A_i = a_i a_i^T
Ai=aiaiT,
c
i
=
b
i
2
c_i = b_i^2
ci=bi2,同时做适当变换消除目标函数中的一次项,即可得到
v
∗
=
min
⟨
H
,
X
⟩
s.t.
⟨
A
i
,
X
⟩
=
c
i
,
∀
i
∈
[
m
]
X
=
x
x
T
\begin{array}{lllll} v^* = &\min & \langle H,X \rangle\\ &\text{s.t.} & \langle A_i, X \rangle = c_i, \quad \forall i \in [m] \\ && X = xx^T \end{array}
v∗=mins.t.⟨H,X⟩⟨Ai,X⟩=ci,∀i∈[m]X=xxT
注意到
X
=
x
x
T
X = xx^T
X=xxT等价于
X
⪰
0
X\succeq 0
X⪰0且
Rank
(
X
)
=
1
\text{Rank}(X)=1
Rank(X)=1,因此(2.9)可以松弛为
v
∗
=
min
⟨
H
,
X
⟩
s.t.
⟨
A
i
,
X
⟩
=
c
i
,
∀
i
∈
[
m
]
X
⪰
0
\begin{array}{lllll} v^* = &\min & \langle H,X \rangle\\ &\text{s.t.} & \langle A_i, X \rangle = c_i, \quad \forall i \in [m] \\ && X \succeq 0 \end{array}
v∗=mins.t.⟨H,X⟩⟨Ai,X⟩=ci,∀i∈[m]X⪰0
同时,由于positive semidefinite matrices是copositive matrices的子集,因此(2.10)可以松弛成(2.8)的copositive programming标准形式。进一步,(2.8)可以通过Lagrangian松弛变为如下的对偶问题。
v
∗
∗
=
max
∑
i
=
1
m
c
i
y
i
s.t.
H
−
∑
i
=
1
m
y
i
A
i
=
S
S
∈
C
q
∗
\begin{array}{lllll} v^{**} = &\max &\sum_{i=1}^{m} c_i y_i \\ &\text{s.t.} & H-\sum_{i=1}^{m} y_i A_i = S \\ && S\in \mathcal{C}_q^* \end{array}
v∗∗=maxs.t.∑i=1mciyiH−∑i=1myiAi=SS∈Cq∗
我们发现,如果把(2.8)和(2.11)中的
X
∈
C
q
X\in \mathcal{C}_q
X∈Cq和
S
∈
C
q
∗
S\in \mathcal{C}_q^*
S∈Cq∗更改为
X
⪰
0
X\succeq0
X⪰0和
S
⪰
0
S\succeq0
S⪰0,则copositive programming变为标准的semidefinite programming。这进一步说明了为什么CP问题是SDP问题的一个拓展。
3. 共正规划求解二次非凸优化问题方法的应用
我们以On the Design of Sparse but Efficient Structures in Operations这篇文章为例,简单介绍一下共正规划的实际应用的可能性。事实上,验证一个问题可以被建模为共正规划问题,或者换言之,验证一个矩阵是copositive matrix,本身已经是一个NP-hard的问题。因此,应用共正规划方法求解问题,其核心在于:如何通过问题本身的特性,证明某一类实际问题可以等价于(或者至少对偶于)一个共正规划问题。
这篇文章研究了以下的问题:
在某些运营管理系统下,需要设计网络结构以应对随机需求。例如:a) 制造业中,工厂需要生产多种产品,但每条产线能生产的产品种类是有限的,工厂需要合理安排每条产线可生产的产品种类,以优化成本;b) 供应链管理中,每个供应商能覆盖的地区范围是有限的,需要优化最少的供应商网络,仍然保证能满足整个市场的需求。
在这类问题中,我们考虑两种极端情况下的网络:a)全连接网络,所有可能的连接都存在,能满足任何需求或任务,但这种网络同时却成本高昂、复杂度高;b)刚性网络,采用结构简单的网络,使用最少的连接以满足需求,但同时却又有适应性差的问题,一旦需求波动,效率会急剧下降。经验告诉我们,在很多实际应用中,删除 80% 以上的连接,仍然可以保持 95% 以上的系统性能。因此,我们需要寻找“稀疏但高效(Sparse but Efficient)”的网络,在平衡成本的同时,保证系统的鲁棒性。
这类问题可以被建模成以下的数学模型:
Z
(
d
~
)
=
min
x
i
j
∑
(
i
,
j
)
∈
G
(
V
,
A
)
c
i
j
x
i
j
s.t.
∑
i
∈
V
0
∪
{
s
}
,
(
i
,
j
)
∈
A
x
i
j
≥
d
~
j
,
j
∈
V
0
,
∑
i
∈
V
0
∪
{
s
}
,
(
i
,
j
)
∈
A
x
i
j
−
∑
i
∈
V
0
∪
{
t
}
(
j
,
i
)
∈
A
x
j
i
=
0
,
j
∈
V
0
,
x
i
j
≥
0.
\begin{array}{llll} Z(\tilde{d}) = & \min_{x_{ij}} &\sum_{(i,j) \in \mathcal{G}(\mathcal{V}, \mathcal{A})} c_{ij}x_{ij} \\ &\text{s.t.} \quad & \sum_{i \in \mathcal{V}_0 \cup \{s\}, (i,j) \in \mathcal{A}} x_{ij} \geq \tilde{d}_j, \quad j \in \mathcal{V}_0, \\ && \sum_{i \in \mathcal{V}_0 \cup \{s\}, (i,j) \in \mathcal{A}} x_{ij} - \sum_{i \in \mathcal{V}_0 \cup \{t\}(j,i) \in \mathcal{A}} x_{ji} = 0, \quad j \in \mathcal{V}_0, \\ && x_{ij} \geq 0. \end{array}
Z(d~)=minxijs.t.∑(i,j)∈G(V,A)cijxij∑i∈V0∪{s},(i,j)∈Axij≥d~j,j∈V0,∑i∈V0∪{s},(i,j)∈Axij−∑i∈V0∪{t}(j,i)∈Axji=0,j∈V0,xij≥0.
其中,
G
(
V
,
A
)
\mathcal{G}(\mathcal{V}, \mathcal{A})
G(V,A)是某种网络结构,其中
s
s
s是source node,
t
t
t是sink node,所有的流量均通过网络
G
\mathcal{G}
G从
s
s
s流到
t
t
t。
d
~
\tilde{d}
d~是有随机性的需求,并假设已知
d
~
\tilde{d}
d~的一阶矩和二阶矩。
Z
(
d
~
)
Z(\tilde{d})
Z(d~)是在给定网络结构
G
\mathcal{G}
G和需求
d
~
\tilde{d}
d~的前提下,能满足需求
d
~
\tilde{d}
d~的最小成本。问题的目标是求解分布鲁棒优化问题
Z
P
=
sup
d
~
∼
(
μ
d
,
Σ
d
)
E
[
Z
(
d
~
)
]
.
Z_P = \sup_{\tilde{\mathbf{d}} \sim (\mu_d, \Sigma_d)} \mathbb{E}[Z(\tilde{\mathbf{d}})].
ZP=d~∼(μd,Σd)supE[Z(d~)].
下面我们主要展示本文如何将
Z
P
Z_P
ZP利用CP技巧进行转化的。我们首先找到
(
3.1
)
(3.1)
(3.1)的对偶:
Z
(
d
~
)
=
max
(
y
,
z
)
∈
X
∑
j
∈
V
0
d
~
j
y
j
Z(\tilde{\mathbf{d}}) = \max_{(y,z) \in \mathcal{X}} \sum_{j \in \mathcal{V}_0} \tilde{d}_j y_j
Z(d~)=(y,z)∈Xmaxj∈V0∑d~jyj
其中
X
=
{
(
y
z
)
|
y
j
+
z
j
+
s
j
=
c
s
j
,
j
∈
V
0
(
1
−
c
i
j
)
(
y
j
+
z
j
)
(
1
−
z
i
)
=
0
,
(
i
,
j
)
∈
A
0
y
,
z
,
s
∈
{
0
,
1
}
n
}
\mathcal{X} = \left\{ \begin{pmatrix} \mathbf{y} \\ \mathbf{z} \end{pmatrix} \middle| \begin{aligned} & y_j + z_j + s_j = c_{sj}, \quad j \in \mathcal{V}_0 \\ & (1 - c_{ij})(y_j + z_j)(1 - z_i) = 0, \quad (i,j) \in \mathcal{A}_0 \\ & \mathbf{y}, \mathbf{z}, \mathbf{s} \in \{0,1\}^n \end{aligned} \right\}
X=⎩
⎨
⎧(yz)
yj+zj+sj=csj,j∈V0(1−cij)(yj+zj)(1−zi)=0,(i,j)∈A0y,z,s∈{0,1}n⎭
⎬
⎫
难点在于
Z
P
Z_P
ZP和
d
~
\tilde{d}
d~相关,而
d
~
\tilde{d}
d~是一个随机变量,如何将其转化成确定性优化的形式呢?作者证明,这个问题可以做如下的转换。首先,我们令
x
=
(
y
z
)
T
\mathbf{x}=(\mathbf{y}\ \mathbf{z})^T
x=(y z)T作为新的问题变量,原问题
(
3.3
)
(3.3)
(3.3)可以重新表述为:
Z
(
d
~
)
=
max
x
d
~
⊤
x
s.t.
a
i
⊤
x
=
b
i
,
∀
i
,
(
h
i
⊤
x
+
f
i
)
(
h
^
j
⊤
x
+
f
^
j
)
=
0
,
∀
(
i
,
j
)
∈
H
,
x
i
∈
{
0
,
1
}
,
∀
i
∈
B
.
\begin{array}{lll} Z(\tilde{\mathbf{d}}) = &\max_{\mathbf{x}} &\tilde{\mathbf{d}}^\top \mathbf{x} \\ &\text{s.t.} &a_i^\top \mathbf{x} = b_i, \quad \forall i, \\ &&(h_i^\top \mathbf{x} + f_i)(\hat{h}_j^\top \mathbf{x} + \hat{f}_j) = 0, \quad \forall (i, j) \in \mathscr{H}, \\ &&x_i \in \{0,1\}, \quad \forall i \in \mathscr{B}. \end{array}
Z(d~)=maxxs.t.d~⊤xai⊤x=bi,∀i,(hi⊤x+fi)(h^j⊤x+f^j)=0,∀(i,j)∈H,xi∈{0,1},∀i∈B.
由于我们只知道
d
~
\tilde{d}
d~的一阶矩和二阶矩信息,因此我们定义以下的变量:
a)期望变量
p
:
=
E
[
x
(
d
~
)
]
∈
R
+
N
\mathbf{p} := \mathbb{E}[\mathbf{x}(\tilde{\mathbf{d}})] \in \mathbb{R}_+^N
p:=E[x(d~)]∈R+N,
b)二阶矩阵
Y
:
=
E
[
x
(
d
~
)
d
~
⊤
]
∈
R
+
N
×
N
\mathbf{Y} := \mathbb{E}[\mathbf{x}(\tilde{\mathbf{d}})\tilde{\mathbf{d}}^\top] \in \mathbb{R}_+^{N \times N}
Y:=E[x(d~)d~⊤]∈R+N×N
c)协同矩阵
X
:
=
E
[
x
(
d
~
)
x
(
d
~
)
⊤
]
∈
R
+
N
×
N
\mathbf{X} := \mathbb{E}[\mathbf{x}(\tilde{\mathbf{d}})\mathbf{x}(\tilde{\mathbf{d}})^\top] \in \mathbb{R}_+^{N \times N}
X:=E[x(d~)x(d~)⊤]∈R+N×N。同时,我们还可以注意到:
E
[
(
1
d
~
x
(
d
~
)
)
(
1
d
~
x
(
d
~
)
)
⊤
]
=
(
1
μ
d
⊤
p
⊤
μ
d
Σ
d
Y
⊤
p
Y
X
)
\mathbb{E}\left[ \begin{pmatrix} 1 \\ \tilde{\mathbf{d}} \\ \mathbf{x}(\tilde{\mathbf{d}}) \end{pmatrix} \begin{pmatrix} 1 \\ \tilde{\mathbf{d}} \\ \mathbf{x}(\tilde{\mathbf{d}}) \end{pmatrix}^\top \right] = \begin{pmatrix} 1 & \mu_d^\top & \mathbf{p}^\top \\ \mu_d & \Sigma_d & \mathbf{Y}^\top \\ \mathbf{p} & \mathbf{Y} & \mathbf{X} \end{pmatrix}
E
1d~x(d~)
1d~x(d~)
⊤
=
1μdpμd⊤ΣdYp⊤Y⊤X
根据定义,这个矩阵显然是completely positive的,且完整包含了
d
~
\tilde{d}
d~的分布信息。利用以上定义的变量,可以将问题
(
3.4
)
(3.4)
(3.4)利用2.3节中介绍的方法写成下面的Completely positive programming问题。
Z
C
=
max
I
⋅
Y
s.t.
a
i
⊤
p
=
b
i
,
∀
i
=
1
,
…
,
M
;
a
i
⊤
X
a
i
=
b
i
2
,
∀
i
=
1
,
…
,
M
;
X
i
i
=
p
i
,
∀
i
∈
B
;
h
i
⊤
X
h
^
j
+
(
f
i
h
^
j
⊤
+
f
^
j
h
i
⊤
)
p
+
f
i
f
^
j
=
0
,
(
i
,
j
)
∈
H
;
C
P
=
(
1
μ
⊤
p
⊤
μ
Σ
Y
⊤
p
Y
X
)
∈
C
2
N
+
1
∗
;
μ
=
μ
d
;
Σ
=
Σ
d
.
\begin{array}{lllll} Z_C = & \max &I \cdot \mathbf{Y} \\ &\text{s.t.} & \mathbf{a}_i^\top \mathbf{p} = b_i, \quad \forall i = 1, \ldots, M; \\ && \mathbf{a}_i^\top X \mathbf{a}_i = b_i^2, \quad \forall i = 1, \ldots, M; \\ && X_{ii} = p_i, \quad \forall i \in \mathcal{B}; \\ && \mathbf{h}_i^\top X \hat{\mathbf{h}}_j + (f_i \hat{\mathbf{h}}_j^\top + \hat{f}_j \mathbf{h}_i^\top) \mathbf{p} + f_i \hat{f}_j = 0, \quad (i, j) \in \mathcal{H}; \\ && CP = \begin{pmatrix} 1 & \mu^\top & \mathbf{p}^\top \\\mu & \Sigma & \mathbf{Y}^\top \\\mathbf{p} & \mathbf{Y} & X \end{pmatrix} \in \mathcal{C}_{2N+1}^*; \\ && \mu = \mu_d; \\ &&\Sigma = \Sigma_d. \end{array}
ZC=maxs.t.I⋅Yai⊤p=bi,∀i=1,…,M;ai⊤Xai=bi2,∀i=1,…,M;Xii=pi,∀i∈B;hi⊤Xh^j+(fih^j⊤+f^jhi⊤)p+fif^j=0,(i,j)∈H;CP=
1μpμ⊤ΣYp⊤Y⊤X
∈C2N+1∗;μ=μd;Σ=Σd.
4. 小结
共正优化(Copositive Programming, CPP)是一类强大但计算复杂的凸优化问题,在组合优化、博弈论和机器学习等领域具有广泛应用。其核心思想是利用共正矩阵锥(Copositive Cone)来刻画约束,使得许多难解的非凸问题能够转化为凸优化问题求解。同时,我们可以将共正优化问题的对偶形式转化为完全正优化(Completely Positive Programming, CPP),其中决策变量属于完全正矩阵锥(Completely Positive Cone)。这种对偶关系为求解共正优化问题提供了新的思路,同时也揭示了共正锥与完全正锥之间的数学联系。
虽然共正优化在理论上提供了强大的建模能力,但由于共正锥的描述涉及所有非负向量,计算复杂度较高,因此在实际研究中不如半定规划深入。我们同样期待着共正优化在更多实际问题中的应用。
5. 参考文献
Burer, S. (2008). On the copositive representation of binary and continuous nonconvex quadratic programs. Mathematical Programming, 120(2), 479-495. doi:10.1007/s10107-008-0223-z
Dür, M. (2010). Copositive programming–a survey. Recent Advances in Optimization and its Applications in Engineering: The 14th Belgian-French-German Conference on Optimization (pp. 3-20). Berlin, Heidelberg: Springer Berlin Heidelberg.
Burer, S. (2015). A gentle, geometric introduction to copositive optimization. Mathematical Programming, 151(1), 89-116. doi:10.1007/s10107-015-0888-z
Yan, Z., Gao, S. Y., & Teo, C. P. (2018). On the Design of Sparse but Efficient Structures in Operations. Management Science, 64(7), 3421-3445. doi:10.1287/mnsc.2017.2761

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









