






在量化交易中,历史数据是策略开发和回测的基础。没有高质量的数据,再好的策略也只是空中楼阁。 这篇文章将为大家详细介绍三种常见的数据获取式: 爬虫、API接口和交易软件下载。每种方式都有其优缺点,适合不同的场景和需求。
一、爬虫:从网页中抓取数据
适合从公开的财经网站、新闻网站或数据平台抓取数据。页面上看得见的数据, 一般都可以
1. 爬虫的基本步骤
(1)明确要爬的网站是哪个
比如想获取股票今日数据,可以选择像新浪财经、东方财富网等公开数据平台。
(2)明确要的数据是什么,在网站的哪个部分
确定目标数据的具体内容,比如股票的收盘价、涨跌幅等。找到这些数据在网页中的位置。
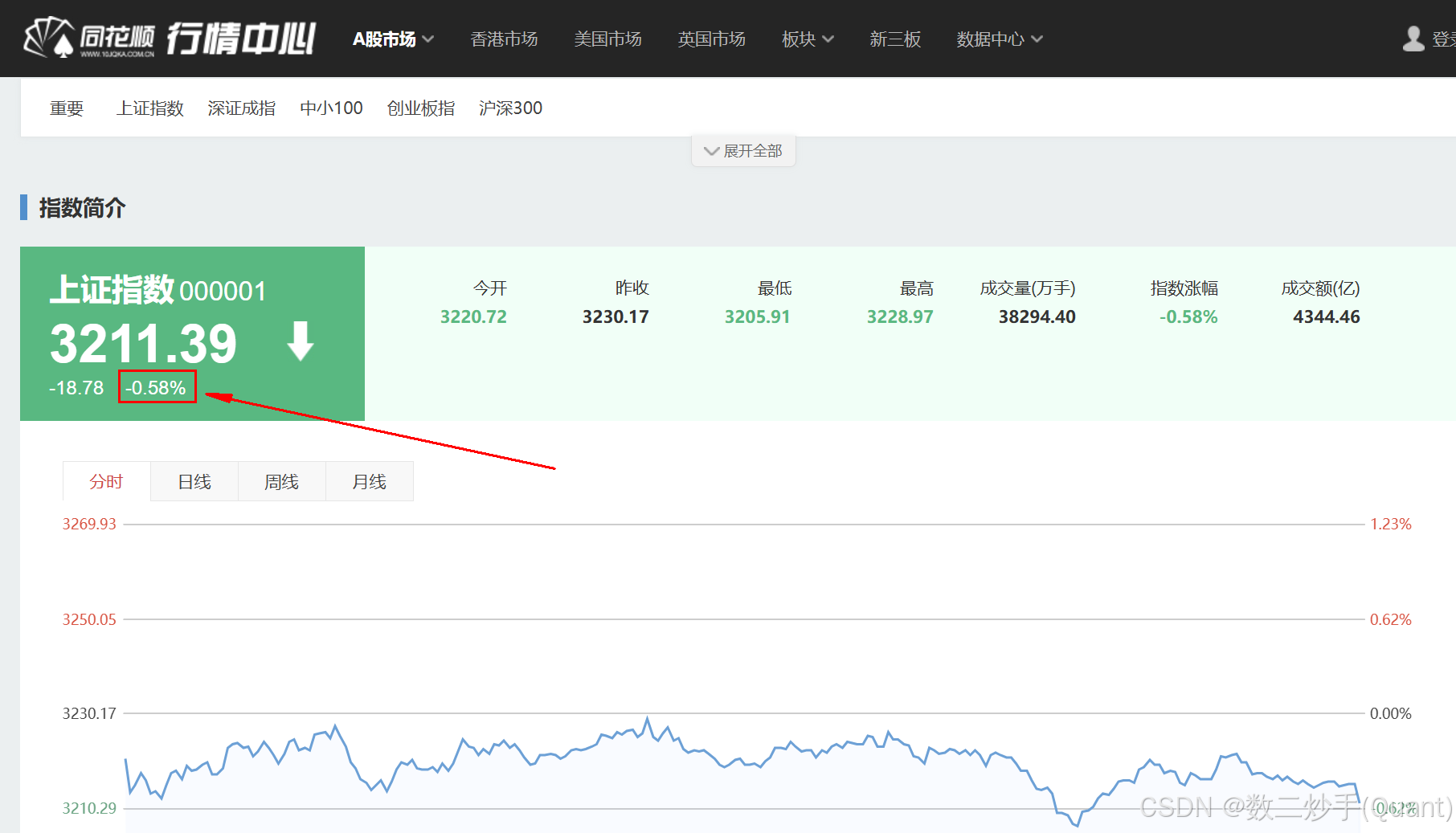
(3)按F12打开网页源码,找到数据所在的前端结构
通过浏览器的开发者工具(按F12),查看网页的HTML结构。单个数字数据一般会放在 <span> 或 <p> 标签中,但要注意外层是否有 <div> 包裹。
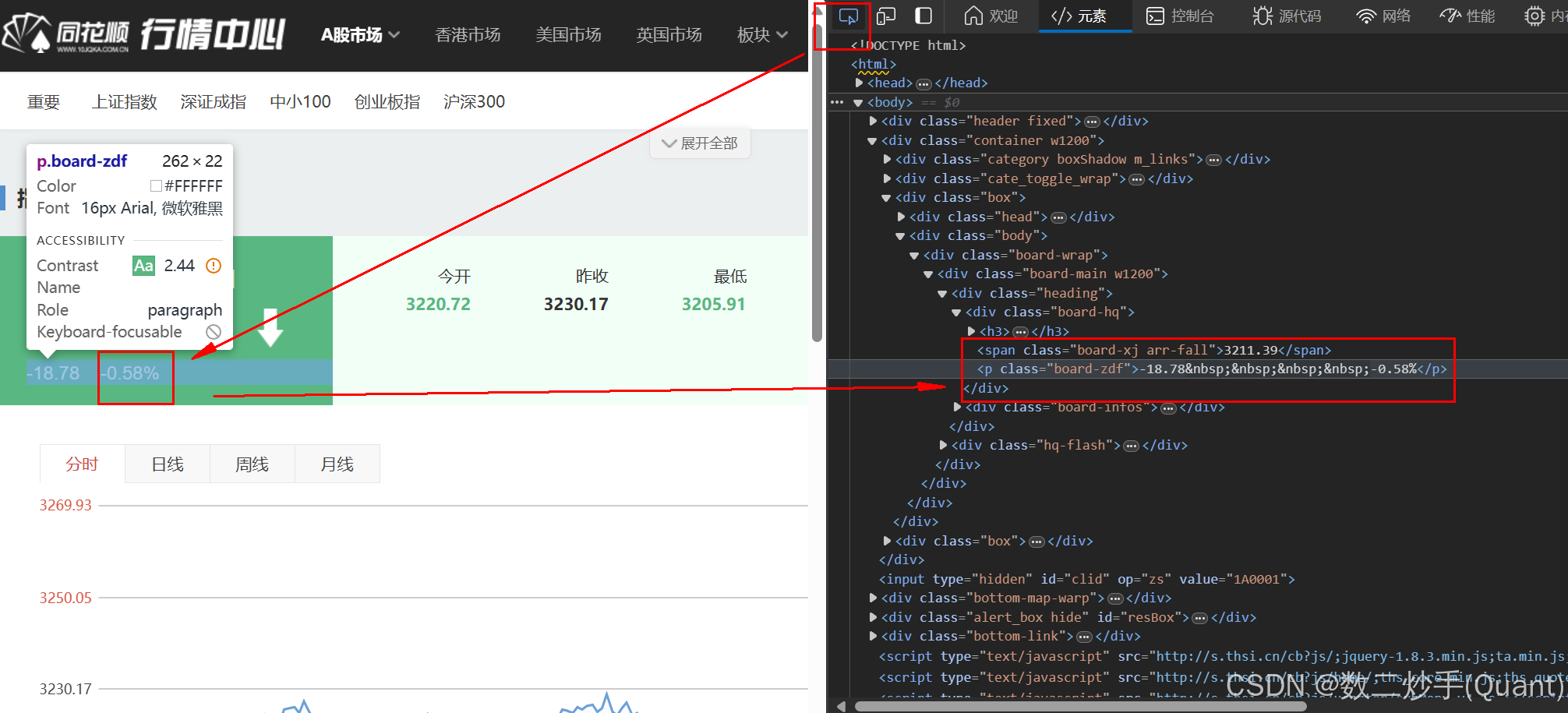
找到这个class = board-zdf的标签p, 里面-0.58%就是涨跌幅数据, 右键复制元素, 就得到了
<p class="board-zdf">-18.78 -0.58%</p> 这样一个标签结构
2. 爬虫的代码实现
有了网页源码, 数据所在的网页结构, 就可以把任务抛给大模型去解决了, 国产的豆包, deepseek都是很不错的
3. 爬虫的注意事项 (如何避免被封禁)
3.1 设置合理的请求频率: 频繁请求会加重服务器负担,容易被封禁IP。
-
建议:在请求之间添加随机延时:
import time import random time.sleep(random.uniform(1, 3)) # 随机等待1到3秒3.2 使用代理IP
有些网站爬多了, 有些会封禁ip不让爬,可以使用代理IP池来分散请求:
-
proxies = { 'http': 'http://your_proxy_ip:port', 'https': 'https://your_proxy_ip:port' } response = requests.get(url, proxies=proxies)3.3 模拟浏览器请求
有些网站会检查请求头(User-Agent),判断是否为爬虫。
-
建议:设置合理的请求头:(这边举个例子)
-
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' } response = requests.get(url, headers=headers)4. 完整的代码示例
-
import requests from bs4 import BeautifulSoup import chinese_calendar as calendar from datetime import datetime # 定义上证50的 URL url = "https://q.10jqka.com.cn/zs/detail/code/1B0016/" # 设置请求头,模拟浏览器访问 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36" } def fetch_shanghai50_data(): """获取上证50的今日涨跌幅并输出到控制台""" # 判断今天是否为工作日且非法定节假日 today = datetime.now().date() if calendar.is_workday(today) and not calendar.is_holiday(today): print(f"今天是工作日且非节假日: {today}") try: # 发送请求 response = requests.get(url, headers=headers) response.encoding = "utf-8" # 解析网页内容 soup = BeautifulSoup(response.text, "html.parser") # 找到 <p class="board-zdf"> 标签 board_zdf = soup.find("p", class_="board-zdf") if board_zdf: text = board_zdf.text.strip() # 获取文本内容 price_change_percent = text.split()[-1].replace("%", "") # 提取涨跌幅并去掉百分号 # 输出涨跌幅到控制台 print(f"上证50 的今日涨跌幅为: {price_change_percent}%") else: print("未能找到上证50的数据,请检查网页结构是否发生变化。") except Exception as e: print(f"获取上证50数据时出错: {e}") else: print(f"今天不是工作日或是节假日: {today}") # 执行函数 fetch_shanghai50_data()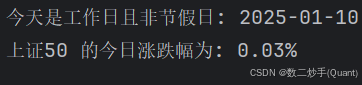
-
感兴趣的可以试试其他指数, 然后把输出的结果保存到Excel或者csv里
二、API接口:高效获取结构化数据
如果不想折腾爬虫,或者需要更高效、更稳定的数据来源,API接口是一个更好的选择。
1. 常见的金融数据API
-
Tushare:提供A股、期货、基金等金融数据。
-
Akshare: 提供A股、期货、基金等金融数据。(免费的多, 适合拿来获取)
-
Alpha Vantage:支持全球股票、外汇、加密货币等数据。
-
Yahoo Finance API:免费获取全球股票数据。
其实还有很多API, 比如东方财富和新浪财经, 腾讯等等, 但是这些api比较单一, 而Akshare和tushare是包含了以上这些api, 通过调用一个接口, 就可以访问其他接口, 更加方便.
Tushare: 比较好用, 需要注册登录来获取属于自己的key, 但是有些高级接口需要权限和积分, 高级接口每天,每分钟都有调用次数限制
Akshare: 我用来爬取各大指数的历史数据, 比如上证指数,创业板指等
另外俩个还没用过, 目前只关注A股比较多, 后期A股数据处理完了再试试别的api
2. 使用示例
1. 以Tushare为例,获取股票历史数据的代码如下:
import tushare as ts
# 设置Token
ts.set_token('your_token')
pro = ts.pro_api()
# 获取股票历史数据
df = pro.daily(ts_code='000001.SZ', start_date='20230101', end_date='20231001')
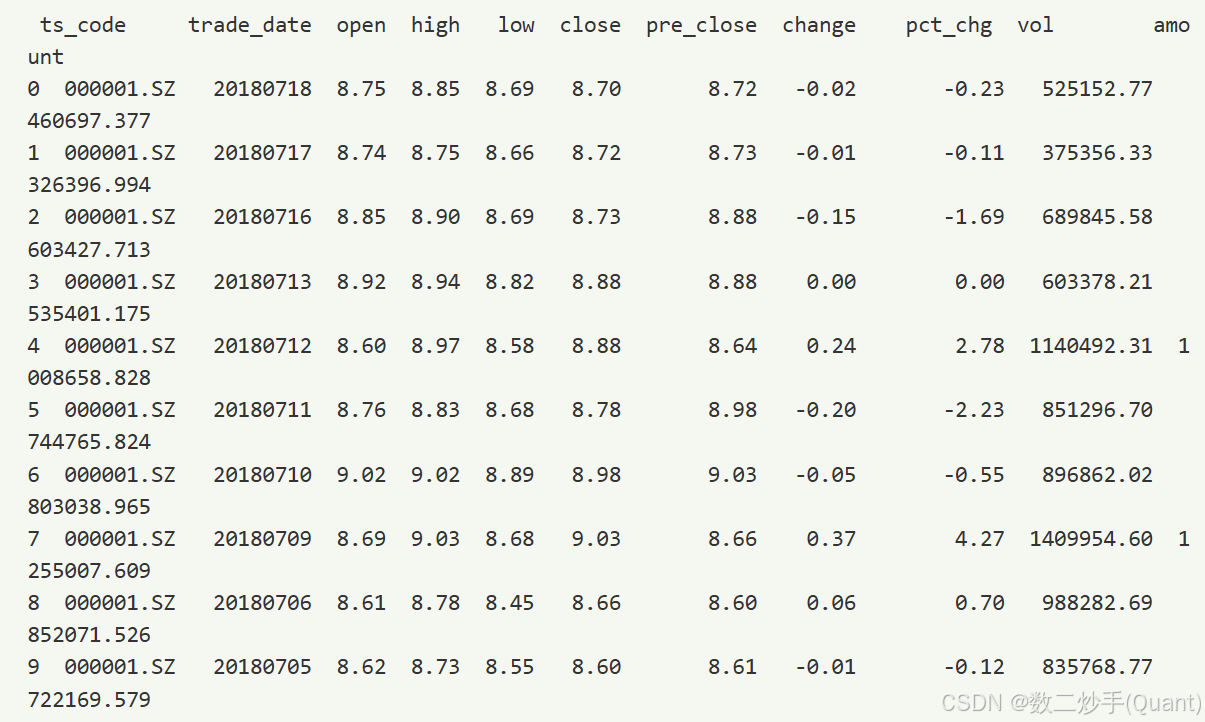
print(df)也可以通过日期取历史某一天的全部股票历史数据
df = pro.daily(trade_date='20180810')3. 结果案例
2. 以AKshare为例: 爬取各大指数的历史数据, 开盘价, 收盘价, 最高价, 最低价等
import akshare as ak
import pandas as pd
from openpyxl.styles import Alignment
from openpyxl.utils import get_column_letter
import time
import os
# 记录开始时间
start_time = time.time()
# 定义需要爬取的指数代码和名称
indices = {
"上证50": "000016", # 上证50指数代码
"沪深300": "000300", # 沪深300指数代码
"中证500": "000905", # 中证500指数代码
"中证1000": "000852", # 中证1000指数代码
"中证2000": "932000", # 中证2000指数代码
"上证指数": "000001", # 上证指数代码
"深证指数": "399001", # 深证指数代码
"创业板指": "399006", # 创业板指代码
}
# 检查文件是否存在
file_exists = os.path.exists("指数数据.xlsx")
# 创建一个 ExcelWriter 对象,用于写入多个工作表
with pd.ExcelWriter(
"指数数据.xlsx",
engine="openpyxl",
mode='a' if file_exists else 'w', # 如果文件存在,使用追加模式;否则,使用写入模式
if_sheet_exists='replace' # 覆盖已存在的工作表
) as writer:
# 如果文件存在,加载已有工作表
if file_exists:
from openpyxl import load_workbook
workbook = load_workbook("指数数据.xlsx")
existing_sheets = workbook.sheetnames # 获取所有已存在的工作表
else:
existing_sheets = [] # 如果文件不存在,没有已存在的工作表
for name, code in indices.items():
# 获取指数历史数据
df = ak.index_zh_a_hist(symbol=code, period="daily", start_date="19800101", end_date="20500101")
# 检查工作表是否已经存在
if name in existing_sheets:
# 如果工作表已存在,直接覆盖数据
df.to_excel(writer, sheet_name=name, index=False)
print(f"{name} 数据已覆盖写入工作表 {name}")
else:
# 如果工作表不存在,创建新表并写入数据
df.to_excel(writer, sheet_name=name, index=False)
print(f"{name} 数据已写入新工作表 {name}")
# 获取当前工作表的对象
worksheet = writer.sheets[name]
# 设置第一列自动宽度
column_letter = get_column_letter(1) # 第一列的字母编号(A)
worksheet.column_dimensions[column_letter].auto_size = True
# 记录结束时间
end_time = time.time()
# 计算总用时
total_time = end_time - start_time
print(f"所有指数数据已成功写入 指数数据.xlsx,总用时:{total_time:.2f} 秒")3. 结果实例2
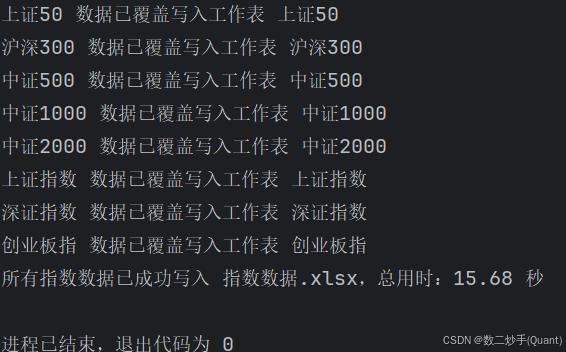
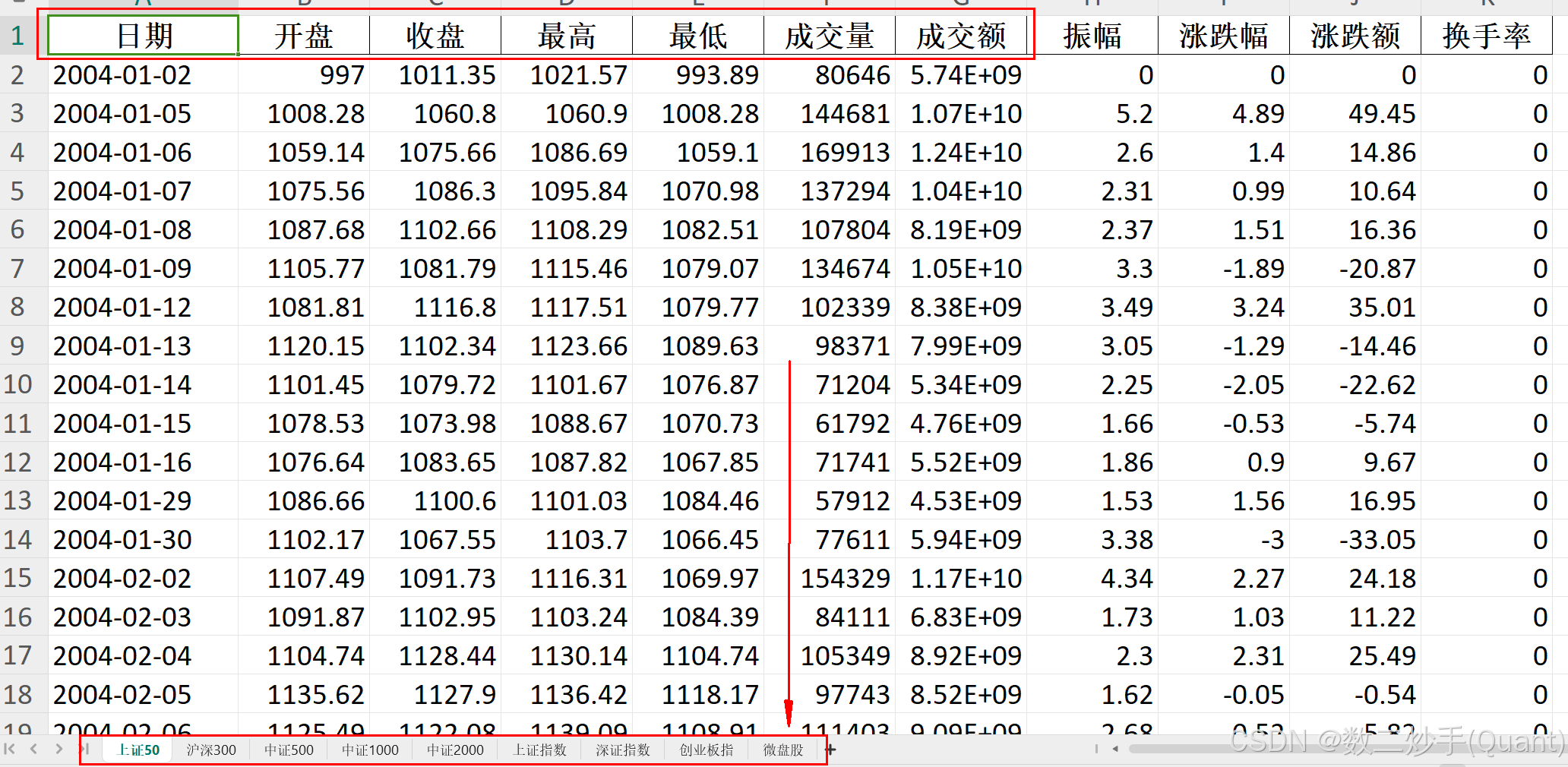
因为很多api都获取不了880823这个微盘股的数据, 所以我自己手动导入了一份, 每次爬取代码的时候, 都会把这个表格里的微盘股工作表删掉, 所以我采用加载每一个工作表的方式, 用时会多6秒
if file_exists:
from openpyxl import load_workbook
workbook = load_workbook("指数数据.xlsx")
existing_sheets = workbook.sheetnames # 获取所有已存在的工作表三、交易软件下载:简单直接
如果对编程完全不熟悉,或者只需要少量数据,可以直接通过交易软件下载历史数据。常见的交易软件包括:
-
同花顺:支持导出股票、基金等历史数据。
-
东方财富:提供丰富的财经数据下载功能。
-
通达信:可以下载微盘股数据。
1. 使用步骤
-
以通达信为例: 打开交易软件,找到目标股票或品种。 键盘直接输入对应的股票or指数代码
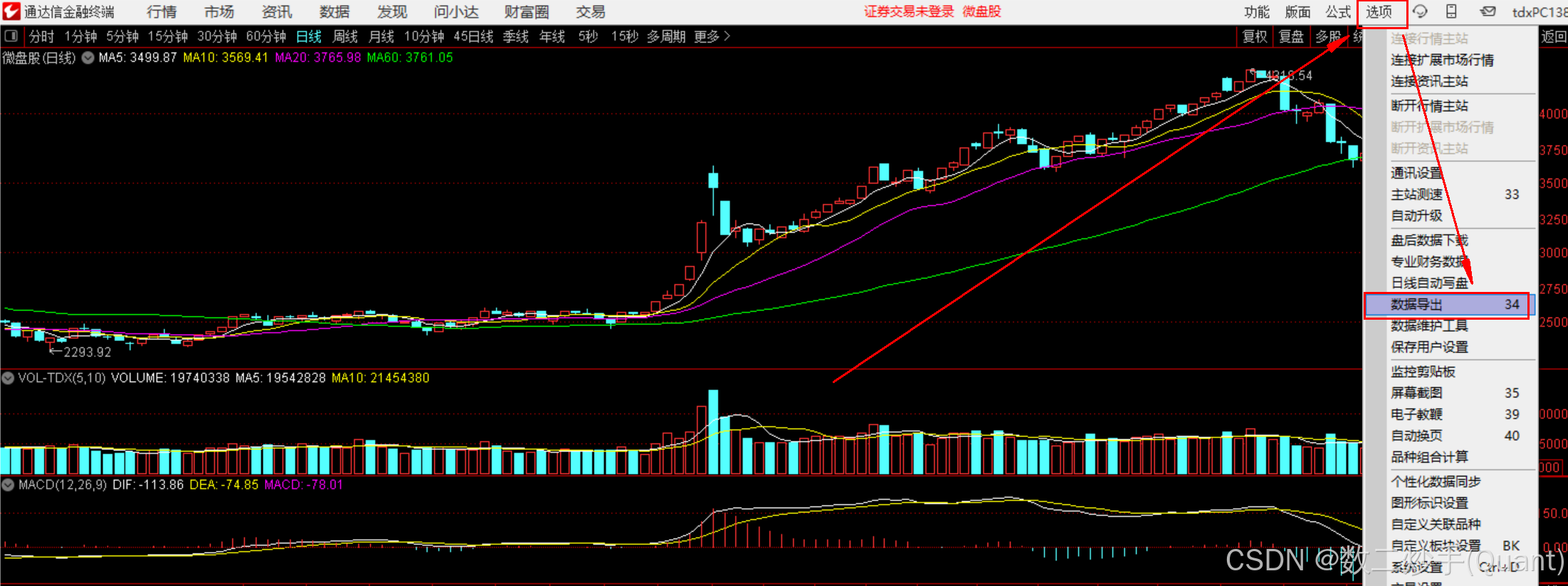
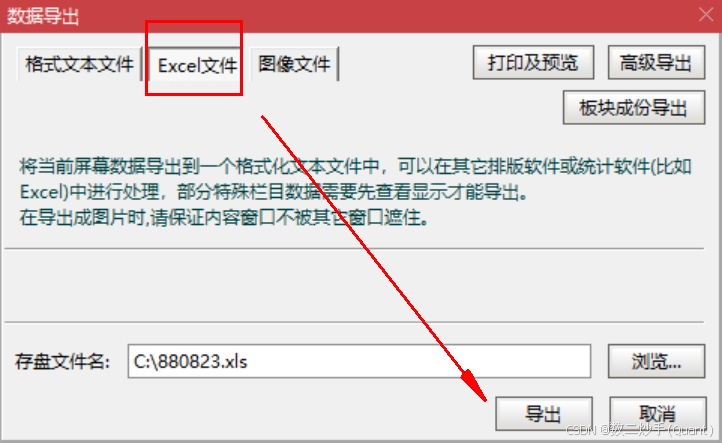
四、总结
获取历史数据是量化交易的第一步,选择合适的方式可以事半功倍。以下是三种方式的对比:
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 爬虫 | 灵活,适合自定义数据需求 | 需要处理反爬虫,代码复杂度高 | 小规模、特定网站的数据抓取 |
| API接口 | 数据质量高,稳定性强 | 可能有费用,部分API有限制 | 大规模、结构化数据获取 |
| 交易软件下载 | 操作简单,无需编程 | 数据量有限,灵活性差 | 少量数据,新手用户 |
作为白嫖用户, 或者作为刚接触量化的小白, 一定要学会自己获取数据, 除了行情数据, 像公司财务数据, 新闻事件数据等, 这些是比较难获取的, 一般需要权限或者付费, 所以要利用好不同的api, 为自己的历史数据库添砖java.
希望这篇文章能帮助大家优雅地获取历史数据!如果有任何问题或建议,欢迎在评论区留言讨论。觉得不错别忘了点赞、收藏和关注!!!
下集预告
数据导入excel, 优化数据, 设置单元格规则和格式等

















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









