






本篇博客介绍一篇发表在2024 ACL finding上的文章:《LC4EE: LLMs as Good Corrector for Event Extraction》
方向:大模型事件抽取
本篇博客为个人阅读论文的总结与笔记,在这里进行简单的分享
论文链接:LC4EE: LLMs as Good Corrector for Event Extraction - ACL Anthology
摘要
事件提取(EE)是自然语言处理中的一项关键任务,但部署一个实用的EE系统仍然具有挑战性。一方面,强大的大型语言模型(LLMs)目前表现出较差的性能,因为EE任务比其他任务更复杂。另一方面,用于EE任务的最先进(SOTA)小型语言模型(SLMs)通常是通过微调开发的,缺乏灵活性,并且有相当大的改进空间。我们提出了一种方法,LLMs-as- corrector for Event Extraction (LC4EE),旨在利用SLMs优越的提取能力和LLMs的指令遵循能力来构建一个鲁棒性和高可用性的EE系统。通过利用LLMs识别并根据自动生成的反馈信息纠正SLMs预测的错误,可以显著提高EE的性能。在具有代表性的ACE2005和MAVEN-Arg数据集上进行事件检测(ED)和事件抽取任务的实验结果验证了该方法的有效性。
一、简介
事件是人类活动和交互的基本单位,包含对下游应用至关重要的丰富信息。事件抽取是从非结构化文本中识别和提取结构化事件信息的过程。它包括:1)事件检测,检测事件触发词并将其分类为预定义的事件类型。2)事件参数提取,提取与每个事件相关联的相关参数。
克服这一挑战的一种方法是探索利用强大的LLMs,并且已经有一些尝试。这些方法在EE任务中显示出LLMs的良好性能,但与SLMs相比仍有不足。虽然SLMs具有优越的性能,但主要是通过微调来完成EE任务,在根据用户反馈调整预测方面不够灵活,在性能上还有很大的提升空间。已有研究表明,LLMs可以根据反馈信息有效地调整自己的反应,这有利于提高任务表现。
因此,我们的目标是将LLMs和SLMs的优势结合起来,充分利用LLMs的指令跟随能力和反馈理解能力,以及SLMs优越的事件提取能力。通过基于误差反馈修正SLMs的预测误差,我们寻求提高EE任务的性能,并建立一个鲁棒性、高可用性的EE系统。
我们开发了一种LC4EE方法,该方法利用LLMs作为校正器,根据自动生成的误差反馈信息对EE任务的SLMs预测误差进行校正。我们的方法由两个主要部分组成:1)反馈生成规则诱导器。通过引导LLMs分析训练集样本,总结规则,自动生成反馈信息,用于识别和纠正SLMs的预测误差。将人工反馈与注释指导方针结合起来,以改进规则,从而形成一个规则存储库,用于在对有效集进行验证后生成反馈。2) LLMs校正器。最后,根据从反馈生成的规则存储库中检索到的规则,指导LLMs验证预测并为不正确的样本生成错误反馈信息,并根据这些信息进行修正。
文章贡献总结如下:
1、通过第2节的实验验证了LLMs可以很好地从误差反馈中学习。
2、设计LC4EE是基于第3节中自动生成的错误反馈来识别和纠正SLMs预测中的错误,这样可以充分利用错误中丰富的信息,最大限度地发挥SLMs和LLMs的优势。
3、在ACE2005和MAVEN-Arg上基于一些主流SLMs进行了ED和EE任务的实验,并使用先进的LLMs、GPT-3.5和GPT-4完成了修正。实验结果表明,LC4EE能够有效地提高系统的性能。
二、初步研究
在本节中,我们首先验证了LLMs在oracle设置下根据错误反馈信息纠正错误的能力(即只根据错误的样本进行纠正)。为了彻底探索这种能力,我们设计了四种粒度级别的反馈信息,并比较了它们的性能差异
2.1 实验设置
我们的方法不依赖于特定的EE模型和模式。因此,结构化的EE输出将与我们的方法一起工作。我们参考了当前关于EE任务的主流研究选择数据集、指标和相关模型来验证我们的方法。
数据集和指标。选择的数据集是ACE 2005 和MAVEN-Arg,它们是EE任务中的代表性数据集。数据集详细信息见附录a。在主流研究之后,使用Precision, Recall和F1分数进行评估。
小语言模型。选择了一些最先进的事件抽取模型,包括:1)EEQA,它将EE任务转化为问答任务。2) TEXT2EVENT ,它将整个EE过程统一在基于神经网络的序列到结构架构中。3) CLEVE ,基于对比预训练框架完成EE。这些模型的训练细节见附录B。
大型语言模型。提示词工程方法的性能在很大程度上取决于所选LLMs的能力。因此,我们选择使用目前最先进的LLMs, GPT-3.5 (OpenAI, 2022)和GPT-4 (OpenAI, 2023),来探索LLMs纠错能力的边界。
2.2 纠错反馈
为了获得更有效和准确的误差反馈,我们对SLMs预测进行了误差分析,并总结了误差类型。详细信息见附录C,下表3展示了误差类型。
表3:展示了误差类型
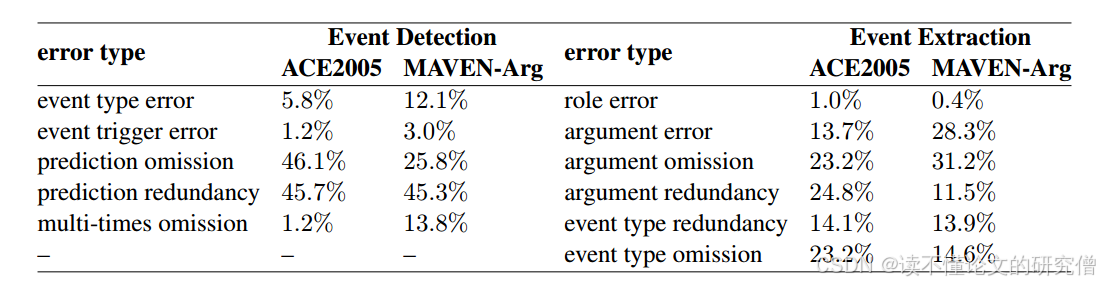
根据误差分析结果,通过自动将预测结果与标签信息进行比较,得到每个样本的误差反馈。为了探讨错误反馈对LLMs纠错能力的影响,我们设计了四种不同粒度级别的错误反馈和相应的纠错规则。反馈的粒度逐步细化,包括:L1:简单的“不正确”,L2:错误类型信息与相应数量,L3:错误元素,L4:具体错误信息。详细的定义和示例见附录D。
例子:在本节中,将使用ED任务的示例指定不同粒度级别错误反馈的定义,ED任务与EAE任务类似。“After years of intense war, diplomatic talks finally began, but sadly, many soldiersdied before peace could be achieved.”。SLMs的原始预测结果是[[" talks ", " Contact.Meet "]。标签信息为 [[“war”, “Conflict.Attact”], [“died”, “Life.Die”]]。将原始预测结果与标签信息进行比较,可以得到误差信息。
误差反馈解释:
L1:错误反馈信息只是“不正确”。这一级别的反馈表明预测是不正确的,但没有说明是如何不正确的。鉴于此,我们知道需要进行修正,但缺乏详细的指导。这种纠错很大程度上依赖于LLMs的语义理解能力。
L2:错误反馈信息由错误类型和相应数量组成。例如,{“预测遗漏”:2,“预测冗余”:1}。这表明预测中遗漏了两个事件,而冗余预测了一个事件。在这种情况下,我们省略了 “Conflict.Attack”for“war” 和“Life.Die”for“died”,并冗余预测“Contact.Meet”“为“talks”。
L3:错误反馈信息提供不正确的元素信息元素错误表示不正确的触发或参数信息,例如[[“战争”,“预测遗漏”],[“死亡”,“预测遗漏”],[“谈话”,“预测冗余”]]。
L4: 错误反馈信息提供了特定的错误。这个级别提供了详细的预测错误,例如, [[[“war”, “Conflict.Attack”],“Prediction omission”], [[“died”, “Life.Die”], “Prediction omission”], [[“talks”, “Contact.Meet”],“Prediction redundancy”]].
更正:基于L4反馈,它提供了最详细的信息:“war”这个词应该引发“Conflict.Attack”。事件,但它被省略了。“died””这个词应该代表“Life.Die””事件,但它也被省略了。
““talks”这个词被错误地预测为““Contact.Meet”。但是考虑到上下文,这个预测可能被认为是多余的,因为它不符合““Contact.Meet”的定义。““Contact.Meet”强调面对面的交流。
修正预测:根据L4反馈修正预测:添加 [[“war”, “Conflict.Attack”]] 以捕捉激烈战争的事件。添加[[[“died”, “Life.Die”]]。以反映许多士兵死亡的后果。评估 [[“talks”, “Contact.Meet”]];如果它符合“Contact.Meet”的定义。,则可保留;否则,它应该从预测结果中删除。
这个纠正过程强调了详细的错误反馈在改进事件提取任务预测中的重要性,确保从文本中更准确和全面地纠正事件提取信息。
2.3 实验结果及分析
我们从测试集中的SLMs预测中抽样了100个具有预测误差的实例。结果见图1和附录E。从实验结果可以看出,除了MAVEN-Arg上的EE任务外,其他任务都有非常明显的提升,F1分数的提升幅度高达50%以上,并且反馈粒度越细,性能提升越明显。对于MAVEN-Arg上的EE任务,由于数据集本身具有更多的事件类型、更精细的分类和更复杂的文本,这与ACE 2005相比要困难得多,因此可能需要更精细的粒度反馈。但总的来说,结果可以验证基于详细的误差反馈信息,LLMs可以很好地纠正误差。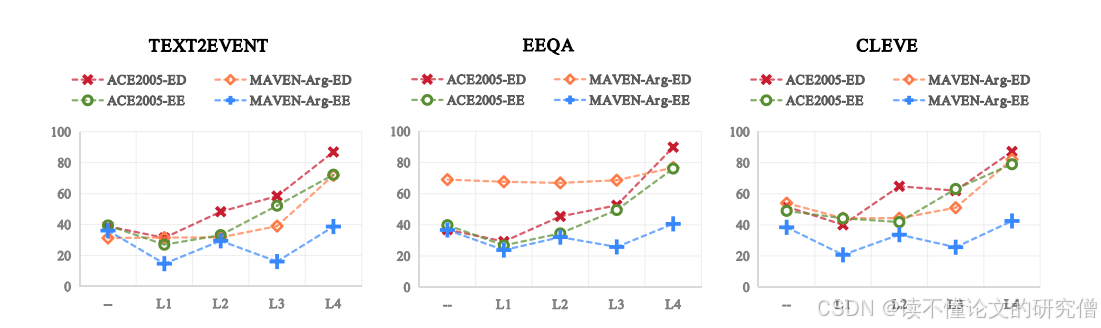
图1:4个粒度级反馈信息对不同性能的比较初步研究结果。“-”表示修正前SLMs的原始性能。
表4:不同粒度反馈信息的EE任务初步研究的具体结果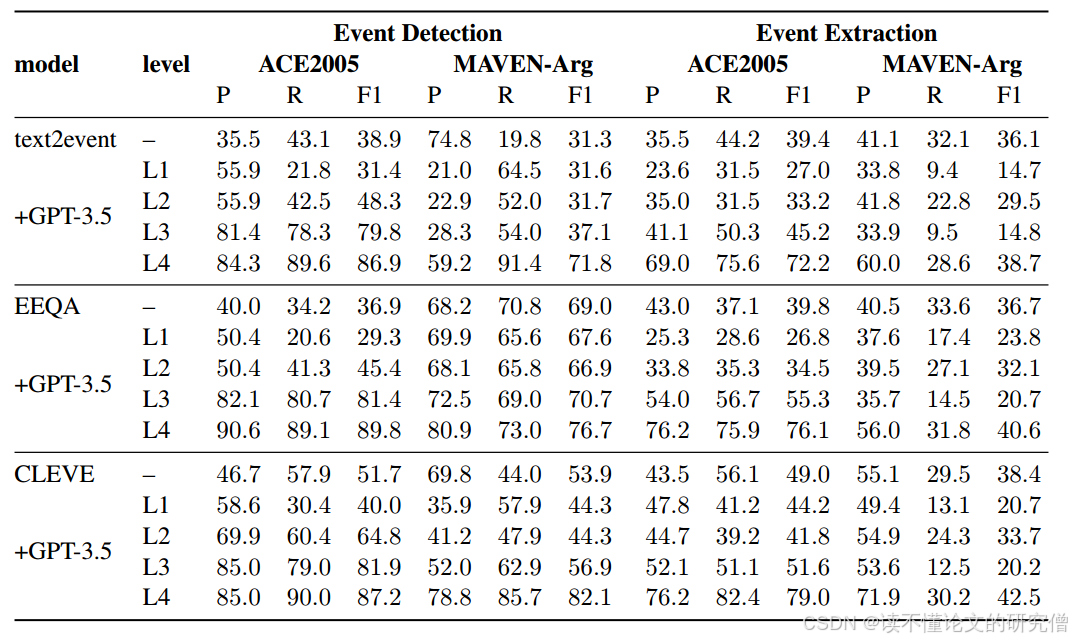
从实验结果可以看出,除了MAVEN-Arg上的EE任务外,其他任务都有非常明显的提升,F1分数的提升幅度高达50%以上,并且反馈粒度越细,性能提升越明显。对于MAVEN-Arg上的EE任务,由于数据集本身具有更多的事件类型、更精细的分类和更复杂的文本,这与ACE 2005相比要困难得多,因此可能需要更精细的粒度反馈。但总的来说,结果可以验证基于详细的误差反馈信息,LLMs可以很好地纠正误差。
三、LC4EE模型
第2节的初步研究已经验证了LLMs具有很强的纠错能力,当有详细的错误信息时,纠错能力会有很大的提高。然而,在实际应用中,获得大量详细的误差反馈是不可行的。
因此,在本节中,我们将探讨LLMs提供尽可能精细的错误自动反馈,然后根据反馈对不正确的样本进行修正。我们设计的LC4EE模型如图2所示,它由两个主要组件组成:用于反馈生成的规则诱导器和LLMs Corrector(校正器)。用于反馈生成的规则诱导器用于基于错误样本的规则总结,用于错误反馈生成。这些规则将在LLMs Corrector中检索,然后根据生成的反馈进行更正。我们将在下面详细描述这两个组件。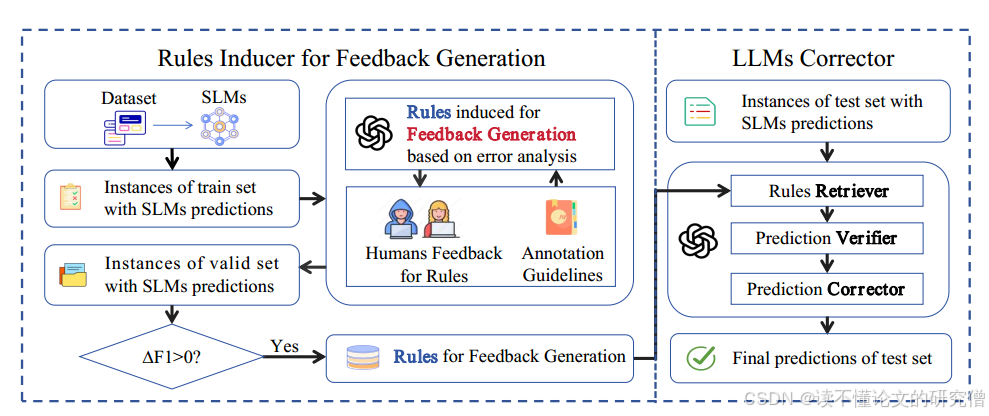
图2:LC4EE概述,它由一个用于反馈生成的规则诱导器和一个LLMs校正器组成。
3.1 反馈生成规则诱导器
为了生成尽可能精细和准确的误差反馈信息,我们引导LLMs归纳预测误差识别规则,并根据这些规则生成反馈。这些规则结合人工反馈和注释指南信息进行迭代改进。
为了便于LLMs进行规则归纳,我们根据事件类型对样本进行分类。对于误差分析中错误频率较高的事件类型,我们从训练集中采样SLMs预测,同时提供预测结果和标签信息,指导GPT-4分析样本,总结规则以识别预测错误,并为错误样本生成反馈,并进行相应的演示。人类通过指出规则的不准确或不恰当,提供与注释指南信息相结合的反馈,从而指导LLMs迭代地完善规则,增强对事件模式的理解,示例如下:
图3是ED任务"Contact.Meet" 事件类型的规则诱导过程示例
根据误差分析,我们发现在ED任务中,预测"Contact.Meet"有很高的出错频率。我们从训练集预测中选择了8个样本,包括正确样本和错误样本。结合"Contact.Meet"的定义。在注释指南中,我们指导GPT-4分析错误原因,并总结一些规则来生成反馈信息。在这个过程中,我们将反馈给GPT-4,指出总结出的规则的不恰当之处和不准确之处,并提出我们迭代完善规则的实际要求。在实际应用过程中,发现GPT-4能够很好地生成反馈生成规则和相应的提示,需要较少的人工交互和纠正,减轻了人类的负担。
我们在有效集上验证人类批准的规则。当∆F1 > 0时,表示F1评分提高,规则有效。我们保留这些规则并建立规则存储库。规则详情见附录G。
EE任务纠正规则的一个例子:
规则类型1:根据ED任务中更正的事件类型信息进行更正。首先,为了排除事件类型错误的影响,我们基于修正后的ED任务中的事件类型信息,消除了参数提取中大量的事件类型冗余错误。然后,针对事件类型遗漏错误,我们指示LLMs根据事件模式中定义的更正后的事件类型对应的角色列表生成提示,从文本中查找合适的参数。
3.2 基于反馈的LLMs校正器
利用几种高质量的反馈生成规则,设计了由检索器、验证器和校正器组成的LLMs校正器。检索器用于检索生成反馈的合适规则。验证器用于识别不正确的预测并生成反馈。校正器用于根据反馈对误差进行校正。
规则检索器:首先,为了更好地识别错误样本并生成更准确的反馈,我们的目标是找到最合适的规则。通过分析来自训练集的数据,我们建立了一个对应于事件类型的候选触发词字典,作为关键字列表。利用LLMs优越的关键字匹配能力,我们获得了样本的候选触发词。与预测中的候选触发词和事件类型相关联的事件类型对应的规则可以从规则存储库中检索。
验证器:基于retriver根据预测结果中的事件类型检索到的反馈生成规则和从样本文本中提取的候选触发词,我们指导LLMs结合语义信息对每个样本进行评估并生成反馈信息,类似于第2节提到的L4粒度。如果不符合任何规则,则验证样品为错误样品。利用验证器过滤不正确的样本并获得错误反馈信息。
纠错器:纠错器根据验证器提供的错误反馈信息和第2节的纠错规则,对不正确的预测进行纠错。我们保留原有的正确预测,最终得到经LLMs修正后的最终预测结果。
在附录H中提供了一个例子:
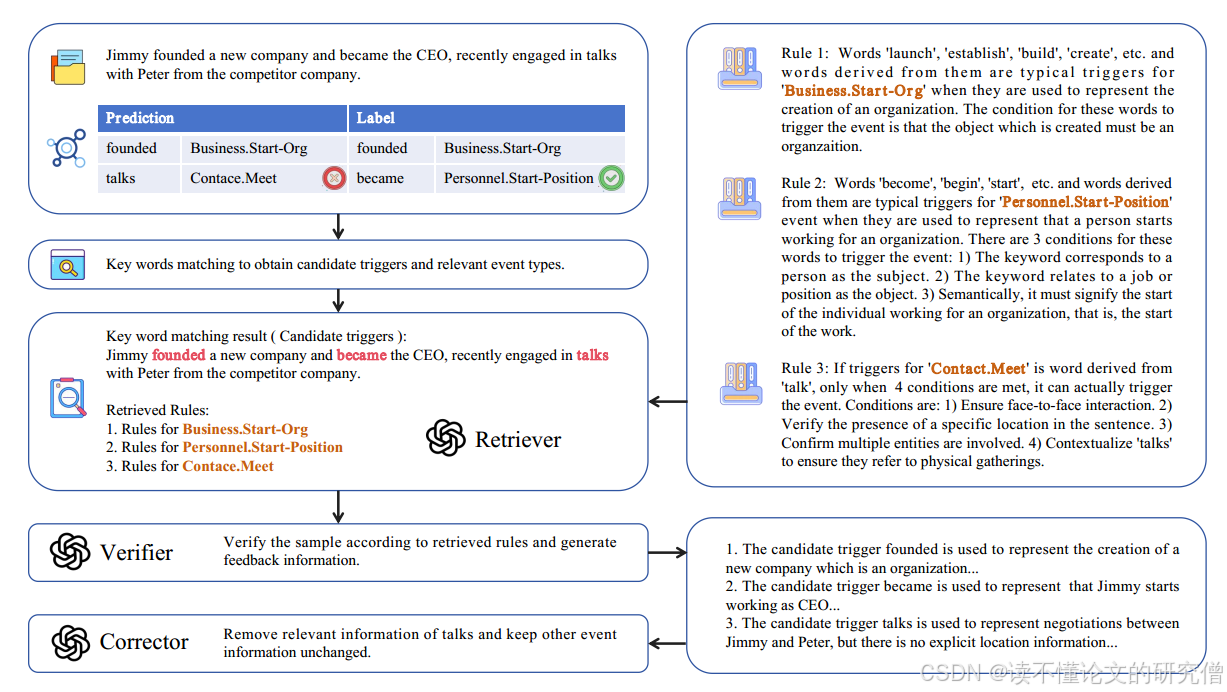
图4:LLMs Corrector的一个示例(ED)
LLMs用于执行关键字匹配任务,以获取候选触发词及其对应的事件类型。得到的结果是[“founded”, “Business.Start_Org”], [“talks”, “Contact.Meet”]] ,候选触发词是“became”。然后,使用retriver,从规则存储库中检索与候选触发词的事件类型和预测结果中的事件类型相对应的规则。如果检索失败,则默认认为预测结果是正确的,并保持不变。接下来,使用Verifier,使用检索到的规则来验证预测结果是否正确,并生成相应的反馈信息。在本例中,“founded”及其对应的事件类型“Business.Start_Org”满足用于表示新公司创建的规则,表明预测是正确的。“became”及其对应的事件类型“Personnel.Start_Position” 符合规则,提示一个人工作的开始,但它不在预测结果中,表明预测中有遗漏,应该添加。“talks”不符合规则,因为不清楚谈话是否面对面,但相关信息在预测结果中,因此应该删除。最后,利用校正器根据反馈信息对预测结果进行校正。LLMs最终修正后的预测结果为 [[“founded”, “Business.Start_Org”],[“became”, “Personnel.Start_Position”]]。
3.3 LC4EE结果及分析
LC4EE的校正结果如表1所示,验证了我们方法的有效性以及LLMs对误差识别和校正的能力。详细分析如下。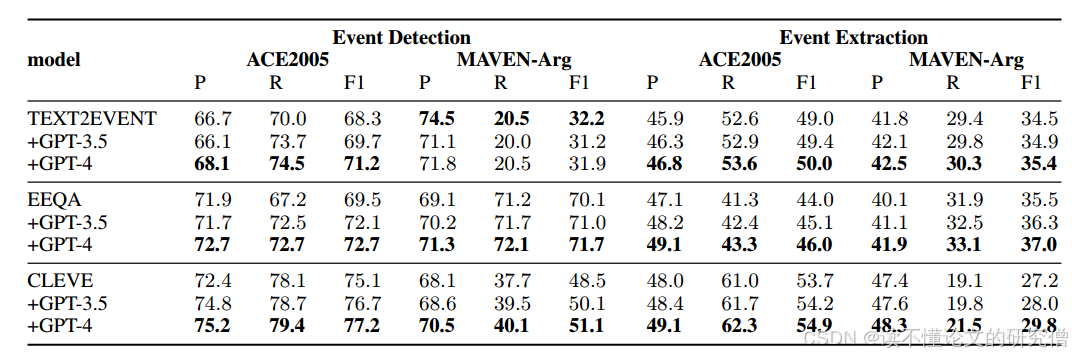
表1:LC4EE根据自动生成的反馈完成校正得到的结果
总体的结果。通过实验结果,我们发现LLMs基于少数有限规则产生的反馈几乎可以显著提高所有性能。特别是,在相对简单的ACE 2005数据集上观察到的ED任务的最佳性能,平均提高了2.7%。LLMs需要相对较少的分析,可以产生更高质量的反馈。然而,与ED任务相比,EE任务的表现不那么令人印象深刻。一个重要的因素是来自ED任务的错误传播,这在附录c中提到的错误分析中已经揭示。此外,EE任务本身更复杂,要求LLMs对上下文有更全面的语义理解,但仍然取得了显著的改进。Maven-Arg的结果也不如ACE2005的结果。这是因为Maven-Arg数据集本身更复杂,在SLMs预测中错误样本的比例明显更高,这对LLMs来说更具挑战性。
验证器分析。从两个方面评估验证器:错误识别能力和生成反馈的质量。基于Verifier检索规则的平均错误识别率为92.4%,表明该模型具有较好的错误识别能力。我们抽取了100条反馈信息进行人工检查,其中87%符合人类标准。
校正器分析。基于反馈信息的修正正确率为72.4%,反映了正确修正样本占所有修正样本的比例。这表明,尽管LLMs不可避免地会进行一些将正确答案变成错误的修正,但修正错误的好处显然超过了引入新错误的成本。
为了进行更全面的分析,在表3和表5中补充了基于采样数据的修正细节。
表5:基于EEQA的ACE 2005中LC4EE的修正细节。“Origin”表示与错误类型相关的错误样本占所有样本的比例。“Correction”为LC4EE修正后的比例,减少的百分比用括号表示。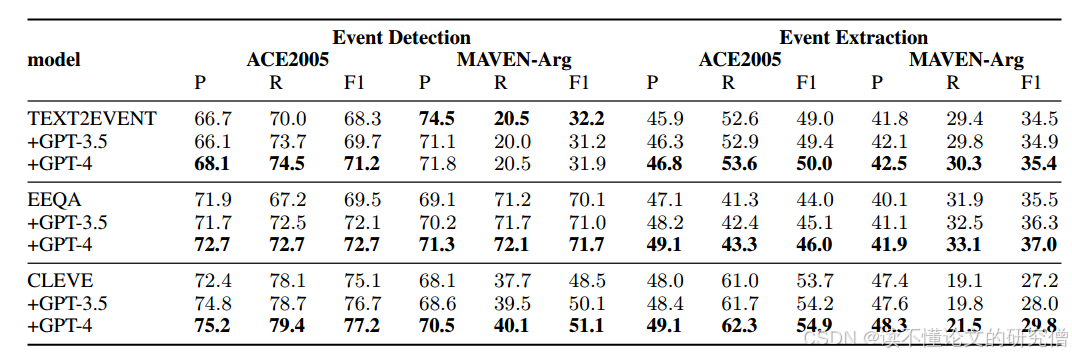
四、结论与未来工作
我们提出了LC4EE模型,该模型结合了SLMs优越的EE能力和LLMs强大的语义理解和指令遵循能力。这样,基于自动生成的反馈信息,利用LLMs来修正SLMs的预测误差。该模型不仅有效地提高了EE任务性能,而且建立了更加灵活实用的EE系统。通过实验验证了该方法的有效性。在未来的工作中,我们计划将LC4EE扩展到更多的任务、模型和数据集。此外,我们将增加反馈生成规则的数量并提高其质量,以进一步提高EE任务的性能。
缺点
由于我们的主要目标是验证我们的方法的有效性,因此目前的工作仍然存在一些局限性。LC4EE的主要局限性有两个:1)为了保证错误样本的比例,我们选择了最复杂的任务Event Extraction任务,该任务的性能还有很大的提升空间。我们选择的模型、任务和数据集是有限的。在未来,我们计划进行更多的实验来扩展我们的方法。2)为了提高校正效率和节约成本,我们只对预测误差频率较高的事件类型引入规则。这样,性能可以得到更明显的提高。在未来的工作中,我们将增加规则的数量并优化我们的规则,以进一步提高EE性能。

















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









