







案例实战---Apr 算法之公众号关联分析
一、案例背景
订阅号每天只能推送一次,一次最多可以发 8 篇图文,但这 8 篇文章必须打包在一块,一个含有大海报&大标题的“头条”,以及7个“次条”。公司的业务范围正在迅速扩大,所以在推送文章时,需要考虑到文章类型的多样性,因此,每天的推送排版,他都要考虑不同的文章类型之间的契合性。
要是陈列不当,次条的阅读量就很惨淡。当然,要是选择恰当,头条和次条就能相互促进,表现喜人,只是,这并不常见。
头条一般都是确定的,主要是次条文章的挑选。那针对不同类型的头条文章,到底应该怎么罗列订阅号的“次条”比较好呢?或者,换句话说,读者可能会同时喜欢看什么类型的内容呢?
二、明确目标
那公众号阅读行为能否像用户的购买行为一样,能挖掘出不同类型文章之间的关联关系?
答案是肯定的。但问题的关键是,怎么定义阅读行为?
在订阅号的场景下,可以将用户在一天内看的所有文章当作是用户的一次阅读行为。
通过对用户阅读行为的关联分析,就能更多地了解顾客的阅读习惯,从而为订阅号每日推文的组合提供参考。
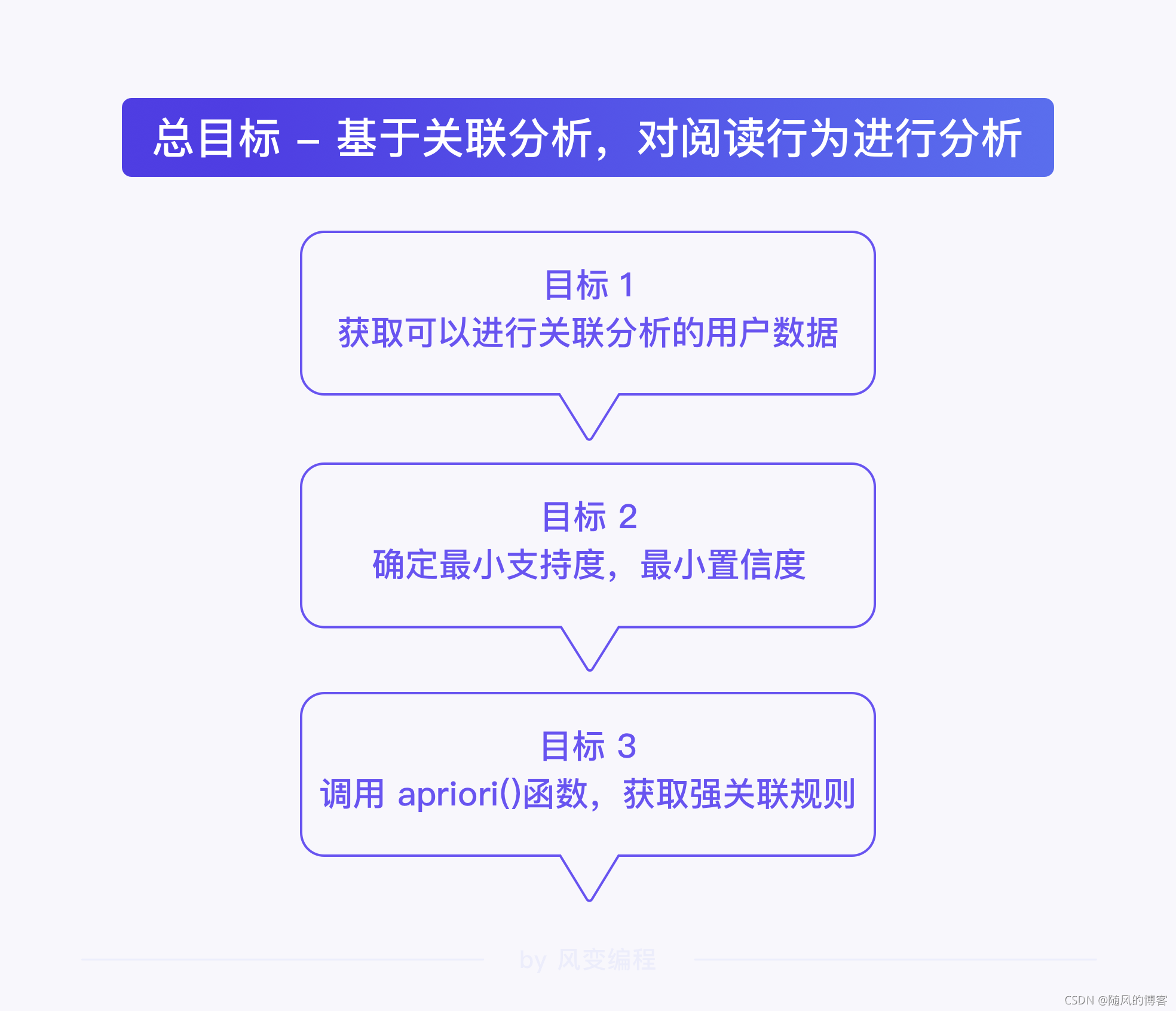
基于这一目标,以及使用 Apr 算法实现关联分析的流程,我们拆解到如下三个分目标:
从运营那我们拿到了一份记录用户阅读轨迹的数据。公众号用户访问数据.csv
In [ 37 ]
1 import pandas as pd
2 # 以 gbk 的编码模式读取并查看【公众号用户访问数据.csv】数据
3 user_data = pd.read_csv('./工作/公众号用户访问数据.csv',encoding='gbk')
4 user_data
运行
Out [ 37 ]
用户编号 文章类别 阅读数 看一看 点赞 赞赏 被转载 访问日期
0 1 数据分析 20051 1203 2406 80 601 2020/9/21
1 2 数据分析 11690 584 1519 46 233 2020/9/17
2 3 数据分析 5720 400 572 45 228 2020/9/2
3 4 数据分析 22502 1125 3150 45 900 2020/9/24
4 5 数据分析 11201 560 1344 89 448 2020/9/8
... ... ... ... ... ... ... ... ...
194 98 pandas 7454 521 819 29 223 2020/9/20
195 98 pandas 7587 379 910 22 151 2020/9/20
196 99 数据分析 12179 852 1217 48 487 2020/9/23
197 99 pandas 11715 585 1288 46 351 2020/9/23
198 99 matplotlib 11542 692 1269 11 230 2020/9/23
一天内会有多名用户进入订阅号,而一个用户一天内可能阅读了多篇文章
比如2020/9/21这一天,其中3名用户的阅读轨迹如下图所示。同一个用户在同一天阅读的所有文章我记做 1 次阅读,如此,我就有了以下 3 条阅读记录(事务)。
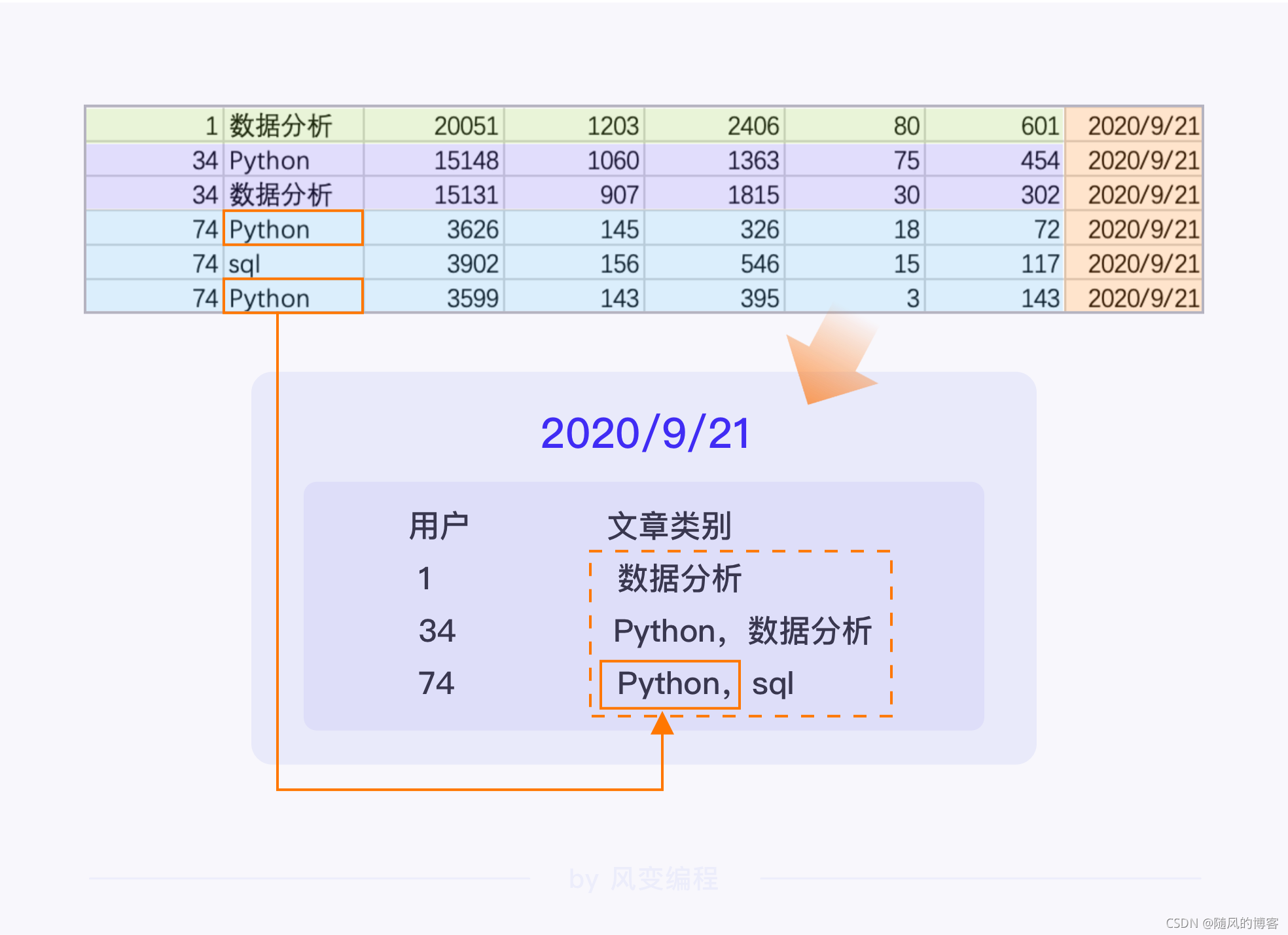
我们分析的是文章类型之间的联系,而不是单篇文章的数量关系,因此,尽管编号为74的用户同时看了2篇Python,这里也只记做1个。
综上,初步判断这份数据是可以达成总目标的,但不能直接进行关联分析,需要对数据进一步处理。
我们的第一个分目标是:获取可以直接进行关联分析的用户数据。
三、数据处理
目标 1:获取可以进行关联分析的用户数据,基于这个分目标,我们需要先对原数据进行处理,而处理这一环节,由两个步骤组成:数据清洗和数据整理。
3.1关于数据清洗,略…
3.2数据整理
前面,经过我们对目标的探讨,可以直接进行关联分析的数据,理想状态应该是长这样的:
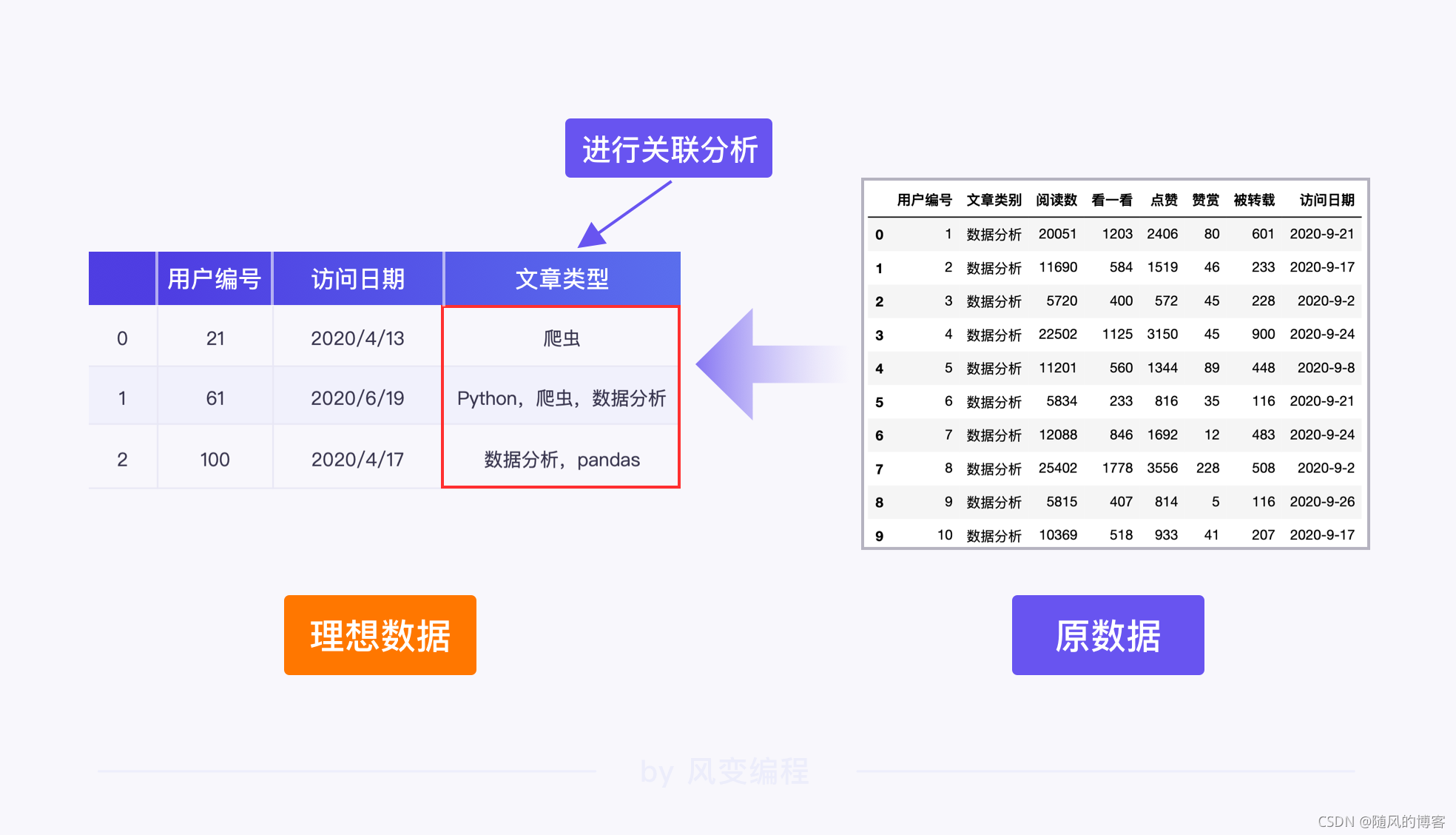
处理这份数据的关键在于:① 提取数据 ② 数据去重 ③数据转换(列表) ④分组聚合
汇集同一个用户阅读的文章类型,也就是数据的合并,可能会联想到用sum()函数,将“文章类型”列进行求和,字符串就会“拼接”起来,像这样:
In [ 39 ]
1 test1 = pd.DataFrame({
'班级': [1, 2, 2, 1], '姓名': ['王薇', '刘敏', '陈芳', '袁芬']})
2 test1 = test1.groupby(['班级']).sum()
3 test1
运行
Out [ 39 ]
姓名
班级
1 王薇袁芬
2 刘敏陈芳
数据确实是“并”在一起了,但字符串首尾相连,连个空格都没有,后续不好处理。
问题似乎出在数据的格式上,既然字符串在聚合时会无缝拼接,不如先转换成列表,再来合并。
In [ 40 ]
1 test2 = pd.DataFrame({
'班级': [1, 2, 2, 1], '姓名': [['王薇'], ['刘敏'], ['陈芳'], ['袁芬']]})
2 test2 = test2.groupby(['班级' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6479
6479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









