







归一化含义
归一化的具体作用是归纳统一样本的统计分布性。归一化在
0-1
之间是统计的概率分布, 归一化在-1--+1
之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,且 sigmoid
函数的取值是
0
到
1
之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。归一化是统一在 0-1
之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于 0
或与其均方差相比很小。
为什么要归一化
(
1
)为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
(2)为了程序运行时收敛加快。 下面图解。
(3)同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
(4)避免神经元饱和。啥意思?就是当神经元的激活在接近
0
或者
1
时会饱和,在这些区域,梯度几乎为 0
,这样,在反向传播过程中,局部梯度就会接近
0
,这会有效地“杀死”
梯度。
(5)保证输出数据中数值小的不被吞食
为什么归一化能提高求解最优解速度
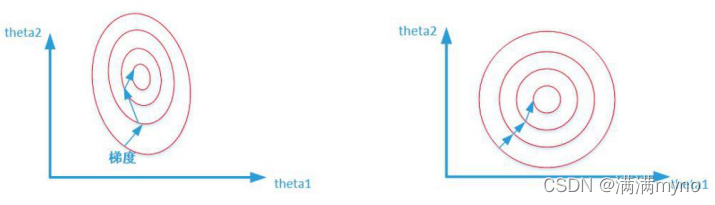
两张图代表数据是否均一化的最优解寻解过程(圆圈可以理解为等高线)。左图表示未经归一化操作的寻解过程,右图表示经过归一化后的寻解过程。
当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
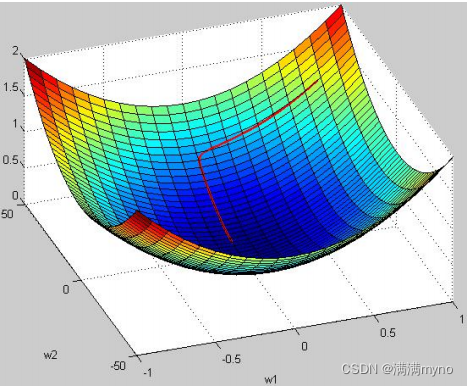
3D图解未归一化
归一化有哪些类型
1
)线性归一化
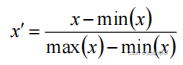
适用范围:比较适用在数值比较集中的情况。
缺点:如果
max
和
min
不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。
2
)标准差标准化
含义:经过处理的数据符合标准正态分布,即均值为
0
,标准差为
1
其中
μ
为所有样本数据的均值,σ
为所有样本数据的标准差。
3
)非线性归一化
适用范围:经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log
、指数,正切等。
局部响应归一化作用
LRN
是一种提高深度学习准确度的技术方法。
LRN
一般是在激活、池化函数后的一种方法。
在
ALexNet
中,提出了
LRN
层,对局部神经元的活动创建竞争机制,使其中响应比较大对值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
批归一化(Batch Normalization)
以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化 Batch Normalization
(
BN
)
批归一化(BN)算法的优点
下面我们来说一下
BN
算法的优点:
a)
减少了人为选择参数。在某些情况下可以取消
dropout
和
L2
正则项参数
,
或者采取更小的L2 正则项约束参数;
b)
减少了对学习率的要求。现在我们可以使用初始很大的学习率或者选择了较小的学习率算法也能够快速训练收敛;
c)
可以不再使用局部响应归一化。
BN
本身就是归一化网络
(
局部响应归一化在
AlexNet
网络中存在)
d)
破坏原来的数据分布,一定程度上缓解过拟合(防止每批训练中某一个样本经常被挑选到,文献说这个可以提高 1%
的精度)。
e)
减少梯度消失,加快收敛速度,提高训练精度。
批归一化和群组归一化
批量归一化(
Batch Normalization
,以下简称
BN
)是深度学习发展中的一项里程碑式技术,可让各种网络并行训练。但是,批量维度进行归一化会带来一些问题——
批量统计估算不准确导致批量变小时,BN
的误差会迅速增加。在训练大型网络和将特征转移到计算机视觉任务中(包括检测、分割和视频),内存消耗限制了只能使用小批量的 BN
。
何恺明团队 http://tech.ifeng.com/a/20180324/44918599_0.shtml
提出群组归一化
Group Normalization (简称
GN)
作为
BN
的替代方案。
GN
将通道分成组,并在每组内计算归一化的均值和方差。
GN
的计算与批量大小无关,并且其准确度在各种批量大小下都很稳定。在 ImageNet
上训练的
ResNet-50
上,
GN
使用批量大小为 2
时的错误率比
BN
的错误率低
10.6
%
;
当使用典型的批量时,
GN
与
BN
相当,并且优于其他标归一化变体。而且,GN
可以自然地从预训练迁移到微调。在进行
COCO
中的目标检测和分割以及 Kinetics
中的视频分类比赛中,
GN
可以胜过其竞争对手,表明
GN
可以在各种任务中有效地取代强大的 BN
。
Weight Normalization 和 Batch Normalization
Weight Normalization
和
Batch Normalization
都属于参数重写(
Reparameterization
)的方法,只是采用的方式不同,Weight Normalization
是对网络权值
W
进行
normalization
,因此也称Weight Normalization;
Batch Normalization
是对网络某一层输入数据进行
normalization
。
Weight Normalization 相比
Batch Normalization
有以下三点优势:
1
、
Weight Normalization
通过重写深度学习网络的权重
W
的方式来加速深度学习网络参数 收敛,没有引入 minbatch
的依赖,适用于
RNN
(
LSTM
)网络(
Batch Normalization
不能直接用于RNN
,进行
normalization
操作,原因在于:
1
、
RNN
处理的
Sequence
是变长的;
2
、
RNN 是基于 time step
计算,如果直接使用
Batch Normalization
处理,需要保存每个
time step
下, mini btach 的均值和方差,效率低且占内存)。
2
、
Batch Normalization
基于一个
mini batch 的数据计算均值和方差,而不是基于整个Training set 来做,相当于进行梯度计算式引入噪声。因此,Batch Normalization 不适用于对噪声敏感的强化学习、生成模型(Generative model:GAN,VAE)使用。相反,Weight Normalization对通过标量 g 和向量 v 对权重 W 进行重写,重写向量 v 是固定的,因此,基于 Weight Normalization 的 Normalization 可以看做比 Batch Normalization 引入更少的噪声。不需要额外的存储空间来保存 mini batch 的均值和方差,同时实现 Weight Normalization 时,对深度学习网络进行正向信号传播和反向梯度计算带来的额外计算开销也很小。因此,要比采用Batch Normalization进normalization 操作时,速度快。 但是, Weight Normalization 不具备 Batch Normalization 把网络每一层的输出 Y 固定在一个变化范围的作用。因此,采用 Weight Normalization 进行 Normalization 时需要特别注意参数初始值的选择。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











