







论文信息:[1312.6114] Auto-Encoding Variational Bayes 提出了变分自编码器(Variational auto-encoder,VAE),用于图像生成模型。2016年Carl Doersch写了一篇VAEs的tutorial[1606.05908] Tutorial on Variational Autoencoders,对VAEs做了更详细的介绍。后面的内容主要基于这一篇tutorial。
摘要
传统的AE作为生成模型的局限性很大,虽然AE能够重建原数据。然而,这样的模型不一定有用:知道一个图像不太真实并不能帮助我们合成一个真实的图像。相反,人们通常关心生成更多与数据集中已有的样例类似但又不完全相同的数据。
变分自编码器(Variational Autoencoder, VAE)是一种生成式深度学习模型,通过结合自编码器架构与变分推断方法,能够在不依赖复杂采样过程的情况下,学习高维数据的潜在表示。VAE通过学习数据特征的分布,来描述数据的特征,通过对分布采样生成隐变量来重新生成图片,从而比传统的自编码器拥有更好的解释性,泛化性。
VAE在图像生成、数据增强、无监督学习等多个领域展现出广泛的应用潜力。
Abstract
This week’s report delves into Variational Autoencoders (VAE), a type of generative deep learning model that combines autoencoder architecture with variational inference. VAE learn to represent high-dimensional data by sampling latent variables from a learned distribution, enabling them to generate new data samples that resemble the training data. The report explains the concept of latent variables, the VAE framework, and the reparameterization trick that allows for differentiable sampling. It also includes a implementation of a VAE trained on the MNIST dataset. The summary highlights VAEs’ applications in unsupervised learning, image generation, and data augmentation, while noting their limitations and extensions like conditional VAE (CVAE) and beta-VAE.
隐变量
以生成手写字符图像的问题为例,为简单起见,我们只关心数字 0-9 的建模。如果字符的左半部分包含 5 的左半部分,则右半部分不能包含 0 的左半部分,否则该字符将非常明显地不像任何真正的数字。直观地说,如果模型在为任何特定像素分配值之前首先决定要生成哪个字符,这会有所帮助。这种决策被称为隐变量(潜在变量)。隐变量 z 就是一个内在的变量, 它在这张图片生成之前先决定了要生成0~9这10张中的哪一张 P(X|z) 从另一个角度来说, 它决定了这张图片所有像素点之间的关系; 如果要生成"5", 那就不可能左边写"5"的一半, 右边写"4"的一半。
在可以说模型能够代表数据集之前,我们需要确保对于数据集中的每个数据点X,都有一个(或多个)潜在变量,这会导致模型生成与X非常相似的数据。正式地说,假设我们在高维空间Z中有一个潜在变量z的向量,我们可以根据在Z上定义的一些概率密度函数P(z)轻松地对其进行采样。给定函数f(z;θ),由某个空间Θ中的向量θ参数化,其中f:Z×Θ→X 。其中,f是确定性的,因此如果z是随机的且θ是固定的,则f(z;θ)是空间X中的随机变量。我们希望优化θ,以便我们从P(z)中采样到的z,可以由f(z;θ)得到类似于我们数据集中的X。
为了使这个概念在数学上更加精确,我们的目标是根据下式,在整个生成过程中最大化训练集中每个X的概率:
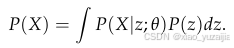
一般会认为 P ( X ∣ z ; θ ) = N ( X ∣ μ ( z ; θ μ ) , σ 2 ( z ; θ σ ) ⋅ I ) P(X|z;θ)=N(X|μ(z;θ_μ),σ^2(z;θ_σ)⋅I) P(X∣z;θ)=N(X∣μ(z;θμ),σ2(z;θσ)⋅I), 即是一个高斯分布; 均值和方差都是由 z 经过两个对应的神经网络计算而来。
变分自编码器
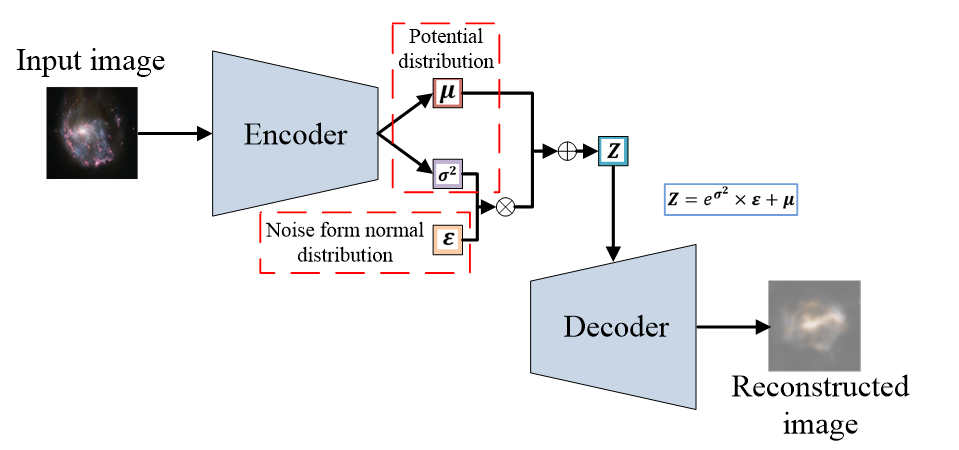
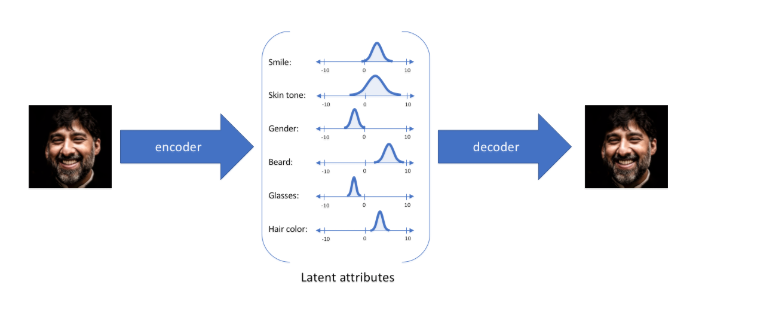
假设任何人像图片都可以由表情、肤色、性别、发型等几个特征的取值来唯一确定,那么我们将一张人像图片输入自动编码器后将会得到这张图片在表情、肤色等特征上的取值的向量X’,而后解码器将会根据这些特征的取值重构出原始输入的这张人像图片。
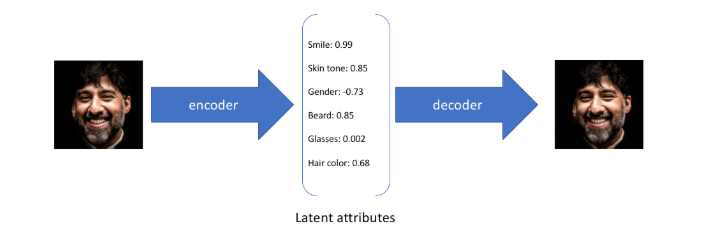
但如果输入蒙娜丽莎的照片,将微笑特征设定为特定的单值(相当于断定蒙娜丽莎笑了或者没笑)显然不如将微笑特征设定为某个取值范围(例如将微笑特征设定为x到y范围内的某个数,这个范围内既有数值可以表示蒙娜丽莎笑了又有数值可以表示蒙娜丽莎没笑)更合适,于是:
就可以把确定的事件描述为概率分布:
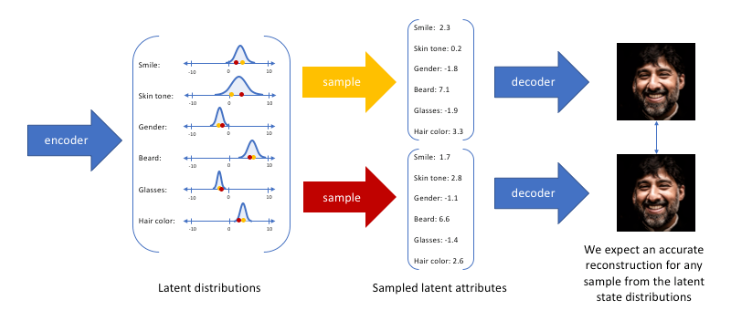
然后最后再采样得到所谓的latent变量(隐变量)Z
定义隐变量
模型在开始绘制数字之前需要做出的“潜在”决定实际上相当复杂。它不仅需要选择数字,还需要选择绘制数字的角度、笔画宽度以及抽象的风格属性。更糟糕的是,这些属性可能是相关的:如果写得更快,可能会产生更多倾斜的数字,这也可能会导致笔画更细。理想情况下,我们希望避免手动决定z的每个维度编码的信息(尽管我们可能希望为某些维度手动指定它)。我们还希望避免明确描述z维度之间的依赖关系——即潜在结构。
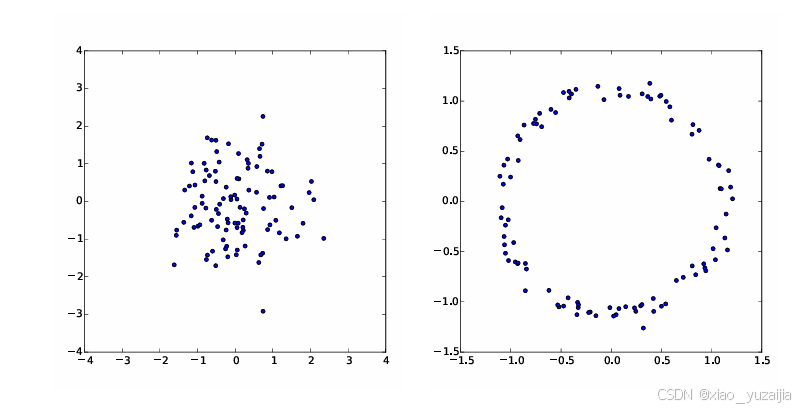
VAE 采取了一种不同的方法来处理这个问题:他们假设z的维度没有简单的解释,而是断言z的样本可以从一个简单的分布中抽取,即N(0,I),其中I是单位矩阵。需要注意的是,任何d维分布都可以通过取一组具有d个变量的正态分布,并通过足够复杂的函数映射它们来生成。例如,假设我们想构造一个值位于环上的二维随机变量。如果z是二维且服从正态分布,则g(z)=z/10+z/||z||大致呈环形,如图 2 所示。因此,如果提供强大的函数逼近器,我们可以简单地学习一个函数,该函数将我们独立的、正态分布的z值映射到模型可能需要的任何潜在变量,然后映射这些潜在变量映射到X。
也就是说尽管z本身没有任何实际意义,但是通过神经网络的学习我们可以将具有正态分布的z,映射到具有某些意义的隐变量去,进而通过隐变量映射为X。
目标函数
单纯通过采样来计算 P ( X ) = ∑ P ( X ∣ z i ; θ ) P ( z i ) P(X)=∑P(X|z_i;θ)P(z_i) P(X)=∑P(X∣zi;θ)P(zi)是不行的, 因为样本数无法做到足够大. 事实上, 对于绝大多数的 z 来说, 生成的 X 都是不存在的, 即P(X|zi;θ) 为0; 这对于计算这个求和是没什么用的, 只会浪费计算资源. 因此, 要想办法只抽那些能生成 X 的 z , 即减小 z 的采样空间; 所以我们前面说的 P(zi) 也就变成了 P(z|X) (省略了下标 i ; 这里P(z|X)仍然是一个高斯分布), 同时我们还需要另外一个分布 Q(z|X) 来逼近P(z|X), 从而生成我们想要的 z .
所以我们引入KL散度来度量Q(z|X),P(z|X)。所以我们的另一个目标就是最小化这个KL散度项。
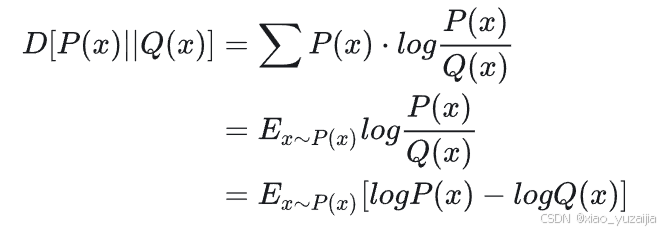
写成期望的形式,然后继续推导
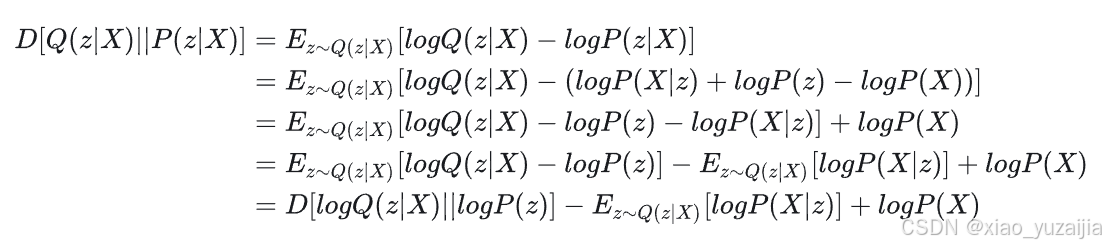
移项得到
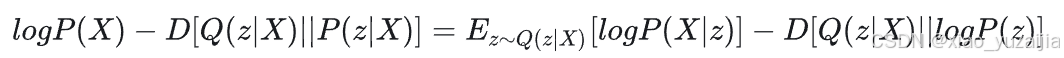
巧妙的是。等式左边就是我们要最大化的两个目标,一个是 l o g ( P ( X ) ) log(P(X)) log(P(X)) , 一个是负的KL散度项 − D [ Q ( z ∣ X ) ∣ ∣ P ( z ∣ X ) ] -D[Q(z|X)||P(z|X)] −D[Q(z∣X)∣∣P(z∣X)]
下面看如何计算等式右边。
首先我们要确定概率密度的形式; 一般采用正态分布, 即 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2) . 因此, 第二项可以改为 $D[N(μ(X;θμ),σ2(X;θσ))||N(0,I)] , 其中 , 其中 ,其中 μ(X;θ_μ)$ 和$ σ^2(X;θ_σ)$ 分别用两个神经网络来完成. 接下来我们就可以用两个正态分布的KL散度公式来计算这一项
对于第一项 E z ∼ Q ( z ∣ X ) [ l o g P ( X ∣ z ) ] E_{z∼Q(z|X)}[logP(X|z)] Ez∼Q(z∣X)[logP(X∣z)], 由于是采用随机梯度下降的方法来优化, 因此对于一个batch来说, 可以将所有单个样本的 logP(X|z) 求和并取平均数来作为期望的估计. 但是这样出了一个问题, 那就是把 Q(z|X) 弄丢了; 换一个角度来说, 每次训练的时候, 梯度传不进 Q 里. 我们需要让Encoder产生能被Decoder正确解码的latent variable, 或者说让他们是interactive的. 因此这里引入一个trick, 叫做"reparameterization trick"(重参数化), 如图所示:
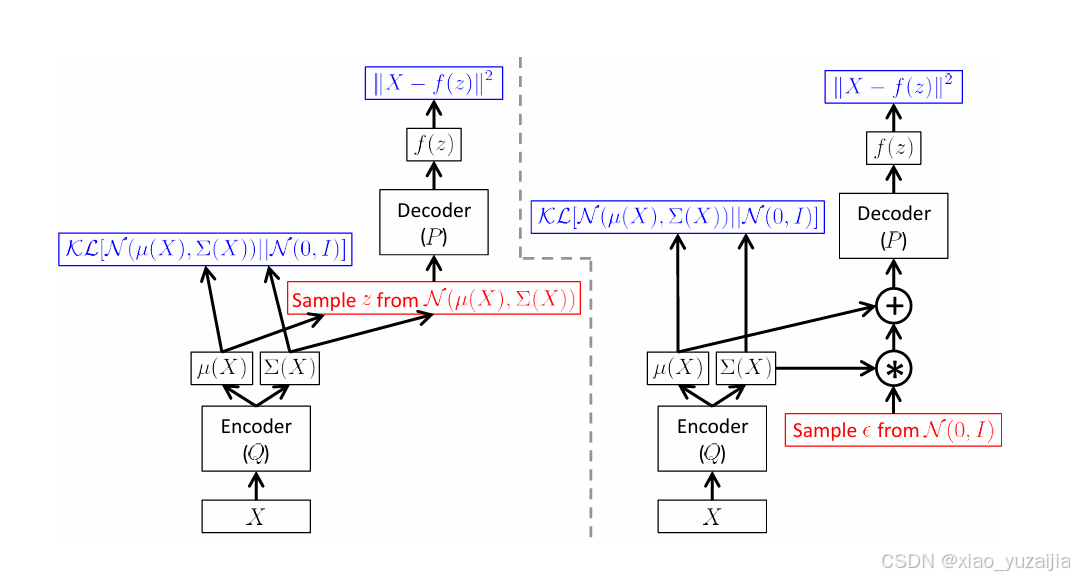
上图中, 红色框(sample)是一个不可back prop的operation. 左边是没有采用reparameterization trick的图, sample操作在整个bp路径的中间, 因此无法反传梯度; 右边是采用了reparameterization trick的图, 用Encoder计算出 μ 和 Σ (方差, 即 σ2 )之后, 不是直接在这个分布上采样, 而是在另外的一个标准正态分布上采样之后, 乘以 σ (scale)再加上 μ (shift). 通过这种方法, 就把不可反向传播的操作转移到了梯度回传路径外面.
实验
pytorch实现
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# 设置超参数
batch_size = 128
epochs = 10
learning_rate = 1e-3
latent_dim = 20 # 潜在空间的维度
# 数据预处理(使用MNIST数据集)
transform = transforms.ToTensor()
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 定义编码器(Encoder)
class Encoder(nn.Module):
def __init__(self, latent_dim):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(28*28, 400)
self.fc21 = nn.Linear(400, latent_dim) # 潜在变量的均值
self.fc22 = nn.Linear(400, latent_dim) # 潜在变量的标准差
def forward(self, x):
h1 = torch.relu(self.fc1(x.view(-1, 28*28)))
z_mean = self.fc21(h1)
z_log_var = self.fc22(h1)
return z_mean, z_log_var
# 定义解码器(Decoder)
class Decoder(nn.Module):
def __init__(self, latent_dim):
super(Decoder, self).__init__()
self.fc3 = nn.Linear(latent_dim, 400)
self.fc4 = nn.Linear(400, 28*28)
def forward(self, z):
h3 = torch.relu(self.fc3(z))
reconstruction = torch.sigmoid(self.fc4(h3))
return reconstruction
# 定义VAE(包括编码器、解码器及重参数化)
class VAE(nn.Module):
def __init__(self, latent_dim):
super(VAE, self).__init__()
self.encoder = Encoder(latent_dim)
self.decoder = Decoder(latent_dim)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
z_mean, z_log_var = self.encoder(x)
z = self.reparameterize(z_mean, z_log_var)
reconstruction = self.decoder(z)
return reconstruction, z_mean, z_log_var
# 定义损失函数
def loss_function(reconstruction, x, z_mean, z_log_var):
BCE = nn.functional.binary_cross_entropy(reconstruction, x.view(-1, 28*28), reduction='sum')
# KL散度
# p(z) ~ N(0, I), q(z|x) ~ N(mu, sigma^2)
# D_KL(q(z|x) || p(z)) = 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
# 其中,mu和sigma是从编码器获得的
# z_mean是mu,z_log_var是log(sigma^2)
# 因此,KL散度是:
# KL = -0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KL = -0.5 * torch.sum(1 + z_log_var - z_mean.pow(2) - torch.exp(z_log_var))
return BCE + KL
# 初始化模型和优化器
model = VAE(latent_dim)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练过程
def train(epoch):
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.to(device)
optimizer.zero_grad()
reconstruction, z_mean, z_log_var = model(data)
loss = loss_function(reconstruction, data, z_mean, z_log_var)
loss.backward()
train_loss += loss.item()
optimizer.step()
if batch_idx % 100 == 0:
print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item() / len(data):.6f}")
print(f"====> Epoch: {epoch} Average loss: {train_loss / len(train_loader.dataset):.4f}")
# 生成图像
def generate_images(epoch, num_images=10):
model.eval()
with torch.no_grad():
# 随机生成潜在变量
z = torch.randn(num_images, latent_dim).to(device)
sample = model.decoder(z).cpu()
sample = sample.view(num_images, 28, 28)
# 显示生成的图像
fig, axes = plt.subplots(1, num_images, figsize=(15, 15))
for i in range(num_images):
axes[i].imshow(sample[i], cmap='gray')
axes[i].axis('off')
plt.savefig(f"generated_images_epoch_{epoch}.png")
plt.close()
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 训练VAE
for epoch in range(1, epochs + 1):
train(epoch)
generate_images(epoch)
生成效果

总结
VAE提出以来,它成为了生成模型领域的基石,并引发了一系列的研究工作。VAE的创新点在于变分推断过程和“重参数化”技巧使得采样过程可微分。VAE的优雅设计使其成为深度生成模型的一个重要类别,且广泛应用于无监督学习、图像生成、数据生成、数据增强等任务。但是VAE在生成任务方面还是太过于基础了,所以之后出现了条件VAE(CVAE),beta-VAE等等模型结构。而之后我将探索VAE在无监督聚类方面的研究。

















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









