






前言
上一章,我们介绍了使用XYZ的方式进行脚本层面的深度配置使用
本章,我们介绍VAE模型和CLIP 终止层数
VAE在RA/CU体系中显示的非常明显,但是在RA/SD的体系中相对用户没有太大的感知。原因也是因为这个东西变化内容少,但又是非常简单的一个组件内容。
最主要的是平时不太去修改,所以只需要大家学习了解到它的基础知识即可。CLIP同样也是一个特别细分的技术名词指标。好好学习吧。
知识点
- VAE
- CLIP
什么是VAE
这小节我们开始学习 Stable Diffusion 里面的 VAE,它的全称是变分自动编码器 (Variational Auto-Encoder),是机器学习中的一种人工神经网络结构。当然我们都不必了解的它的原理,只需要理解它是在 SD 模型的基础做微调的,类似于我们熟悉的滤镜,让生成的图片调整饱和度。
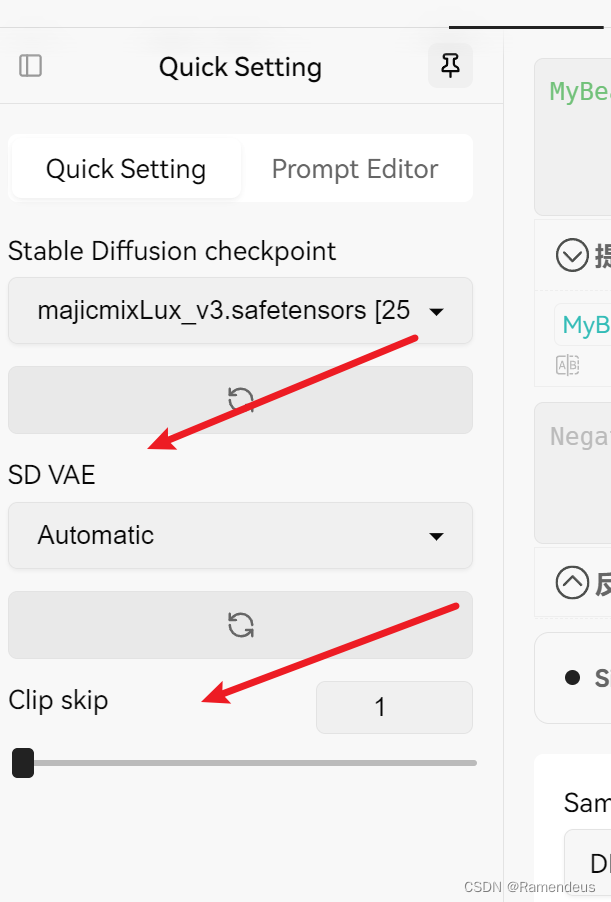
默認SD軟件上是沒有打開的。我們可以通過如下配置打開。
Settings-→User Interface 中找到QuickSettings這裡。手動添加2個。

下载 VAE 模型
目前我们还没有任何的 VAE 模型,需要下载再使用。VAE 主要是从 Huggingface 下载,而 C 站 VAE 比较少,并没有一个专门的过滤分类,只能通过搜索框输入 VAE 过滤:
所谓没有对比就没有伤害,对比明显可以感受到不加 VAE 图片优点灰蒙蒙的,不够鲜艳,另外是细节不够,而加了不同的 VAE 都有了更好的颜色效果,细节更全了 (微调)。
最后,注意不同的 VAE 适配的模型不同,也不是某个 VAE 可以用在任何模型下,否则可能会生成非常奇怪的图。
为什么 VAE 模型比较少?
我觉得主要的原因是很多软件已经实现了滤镜相关的功能,例如 PS、一些美颜 App、剪映等等。它们的效果更全更好,而且门槛很低。
什么是CLIP
CLIP(Contrastive Language-Image Pre-training)是一个核心组件,主要用于将文本和图像联系起来,使得模型能够根据文本描述生成相关的图像。
CLIP由OpenAI开发,是一个结合了图像和文本的多模态模型,能够理解并将自然语言映射到图像特征空间中,从而实现更精确和一致的图像生成。以下是CLIP在RA/SD中的详细作用和工作原理:
CLIP的基本概念
CLIP是一种双塔模型(dual-tower model),包括两个独立的神经网络:
- 文本编码器:通常是一个Transformer模型,用于将文本描述编码为文本向量(text embeddings)。
- 图像编码器:通常是一个卷积神经网络(如ResNet或Vision Transformer),用于将图像编码为图像向量(image embeddings)。
CLIP通过对比学习(contrastive learning)进行训练,使得对应的文本描述和图像在向量空间中尽可能靠近,而不相关的文本和图像尽可能远离。
CLIP在RA/SD中的作用
- 文本指导图像生成:在RA/SD中,用户提供的文本提示首先通过CLIP的文本编码器转换为文本向量。这些文本向量然后用于指导扩散模型中的图像生成过程,使生成的图像与文本描述一致。
- 多模态对齐:CLIP使得RA/SD能够在同一向量空间中对齐文本和图像特征,从而实现多模态数据之间的无缝转换。这种对齐有助于生成高质量且符合文本描述的图像。
- 条件生成:RA/SD使用CLIP的文本向量作为条件,将其与初始噪声结合,在扩散模型的逐步去噪过程中提供指导。这种条件生成机制使得模型能够生成特定风格或内容的图像,根据用户的文本提示精确控制生成结果。
工作流程
以下是CLIP在RA/SD中的典型工作流程:
- 文本编码:用户输入文本描述,例如“a beautiful sunset over the mountains”。CLIP的文本编码器将该描述编码为文本向量。
- 噪声初始化:生成过程从一个随机噪声图像开始。
- 逐步去噪:在每个扩散步骤中,模型使用文本向量作为条件,对当前的噪声图像进行调整和去噪。这种调整基于CLIP的多模态对齐,使得生成的图像逐步逼近文本描述。
- 生成图像:最终,经过多个扩散步骤,生成一个与文本描述高度一致的图像。
优势和应用
- 高质量生成:CLIP的引入使得Stable Diffusion能够生成与文本描述高度匹配的高质量图像。
- 多样性和灵活性:通过调整文本提示,用户可以生成各种风格和内容的图像,具有高度的多样性和灵活性。
- 研究和创意:在研究和创意领域,CLIP在Stable Diffusion中的应用极大地扩展了文本指导图像生成的可能性,使得艺术创作和科学研究更加便捷和高效。
作者:小R
AIGC学习网站:https://shxcj.com#ref-clip
总结
CLIP是将你的提示文本转换为数值表示。
就是把我们输入的提示词以简单的方式被数字化,然后通过各层传递。
这意味着CLIP有很多层,在第一层之后,可以得到提示词的数值表示,将其输入到第二层,继续输入到第三层,依此类推,直到到达最后一层,这就是CLIP值为1的情况。
如果CLIP值为2,就是我们提前停止,并使用倒数第二层的提示词数字化输出。
我们发现CLIP值越大,提前停止的越快,我们提示词被数字化的层数越少,提示词的相关性越小。
创作不易,觉得不错的话,可以点个赞吗?















 1655
1655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









