








 超级会员免费看
超级会员免费看

pycharm专业版--链接mysql
第一步:
专业版的最左边,左上角依次点击:Database -> +号 -> Database Source中找到MySQL
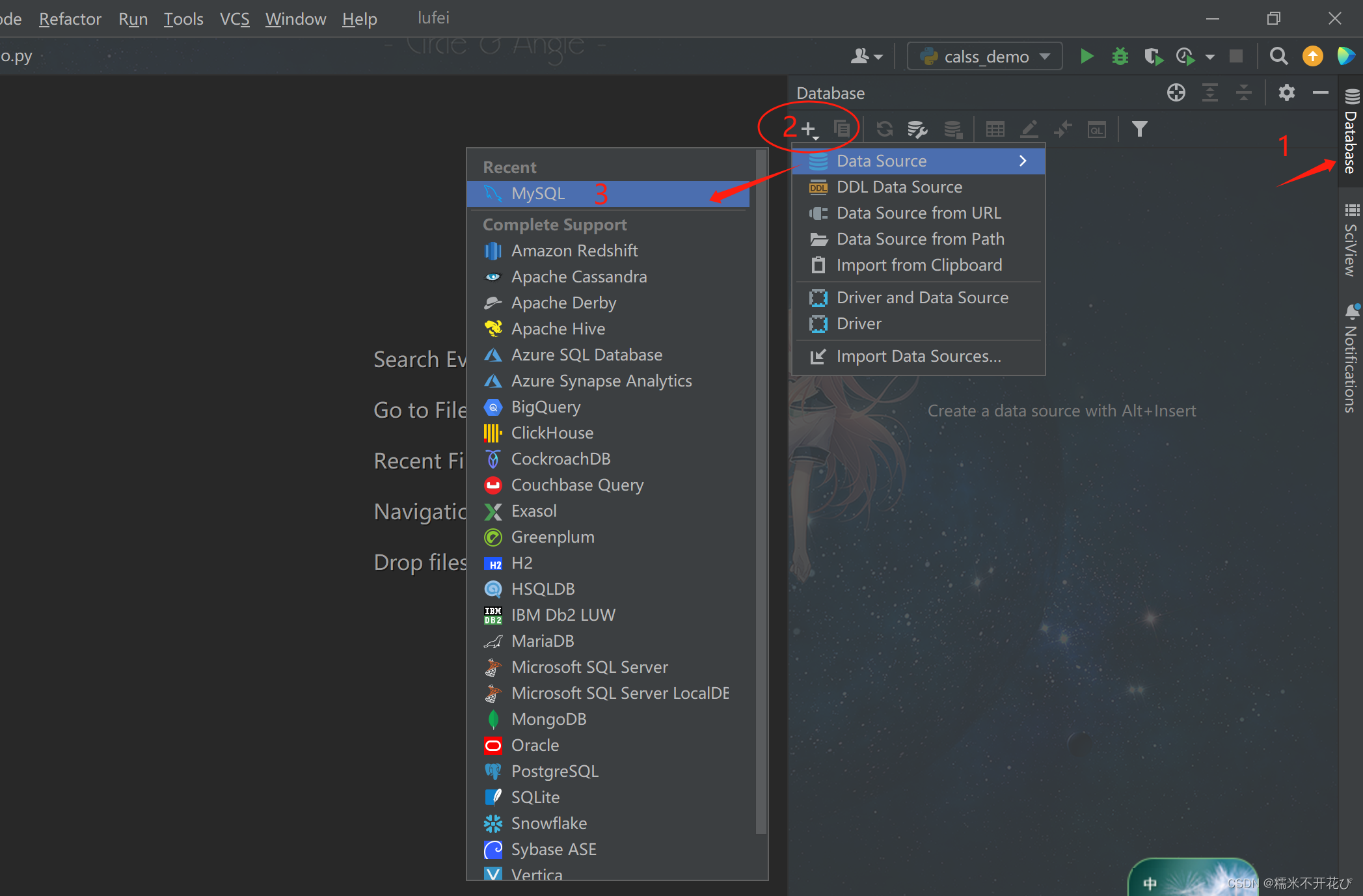
第二步:
上面点击MySQL之后,就是如下界面:
第一次链接MySQL需要点击Download下载安装 Driver Files,如下截图会显示安装进度,等待安装完成(如已下载过Driver Files,则跳过进行第三步)
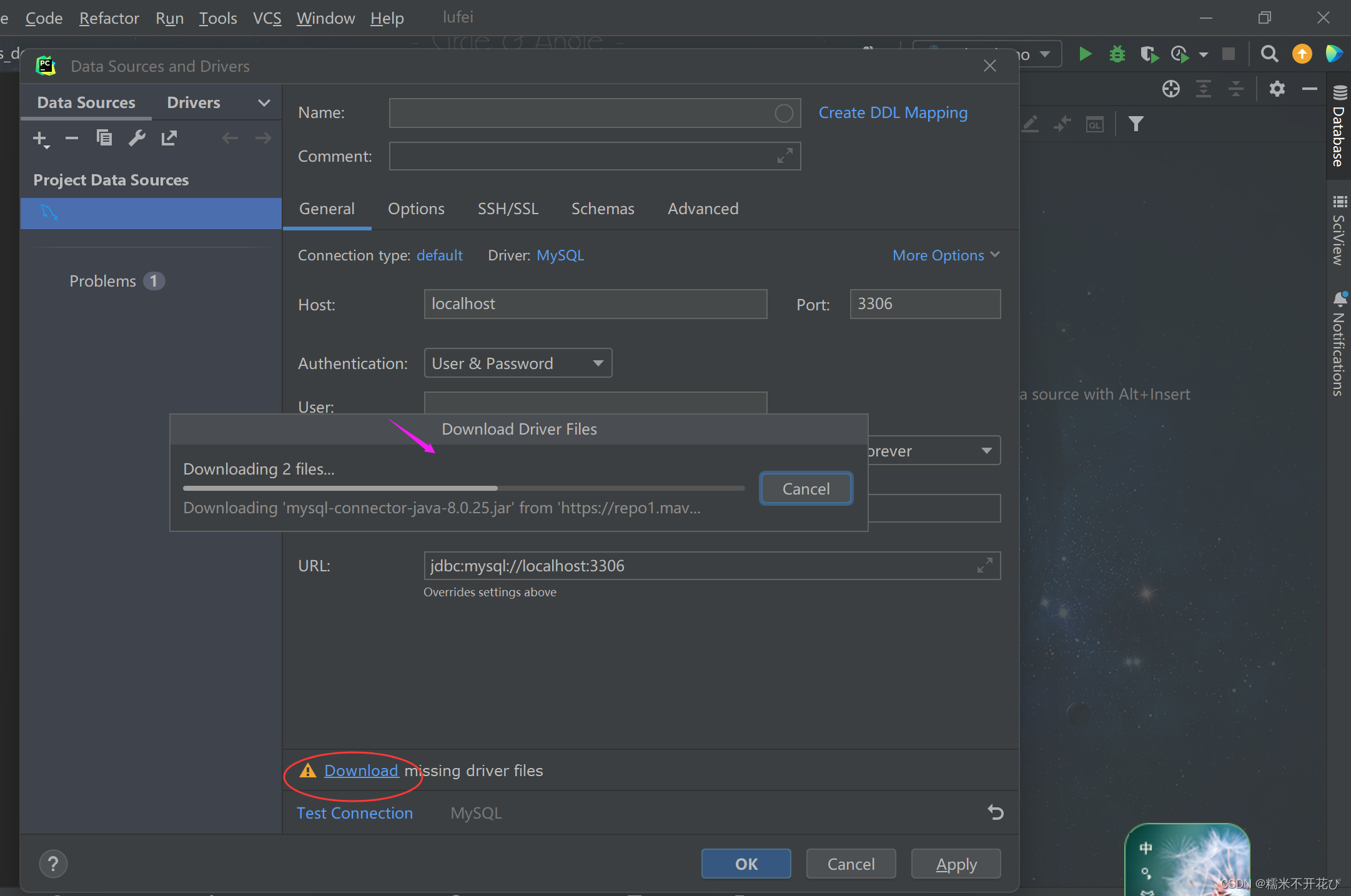
第三步:
输入链接名+账号+密码+库名 -> 点击链接测试,提示成功后,点击ok就可以了
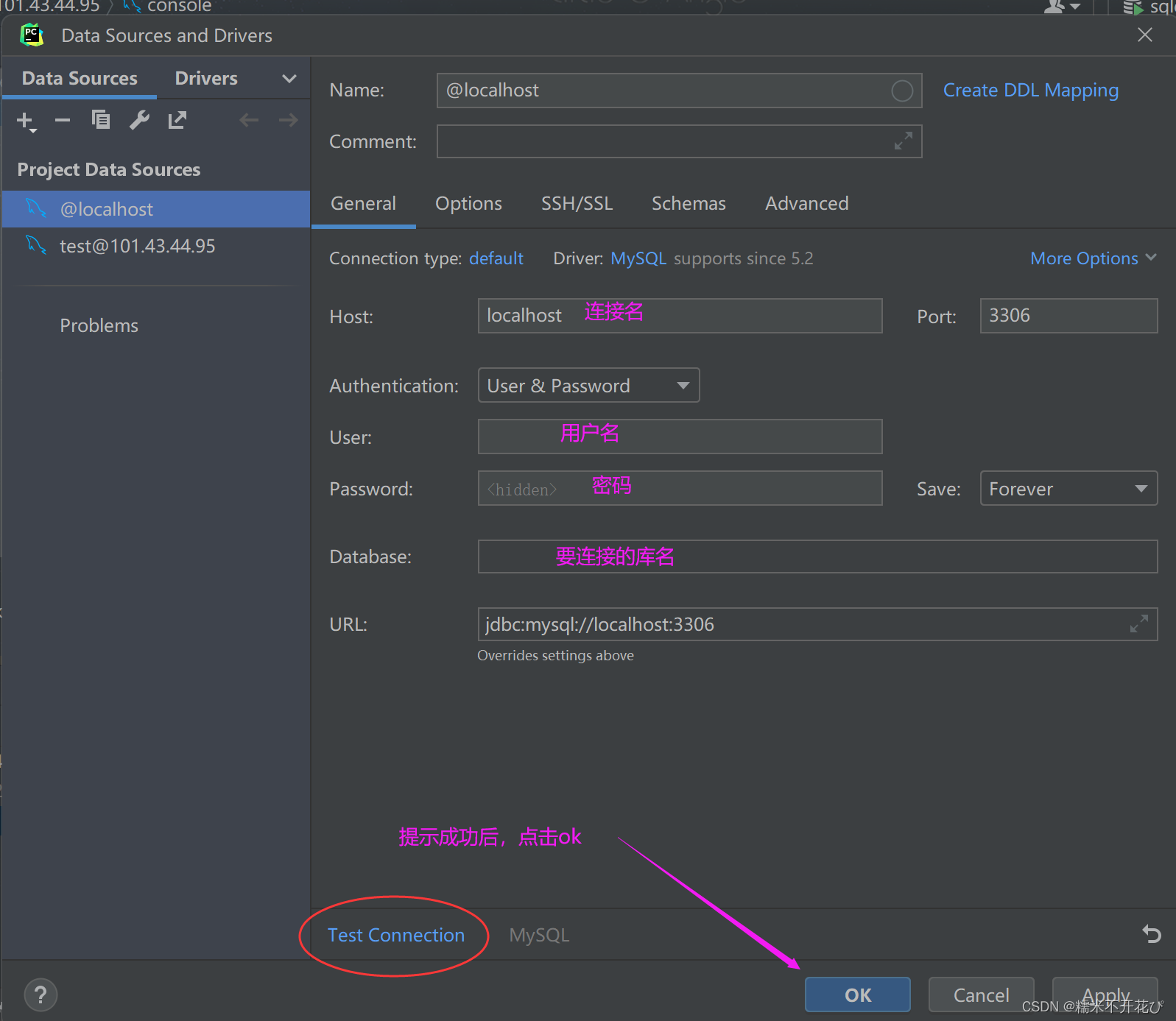
说明已经链接成功了:
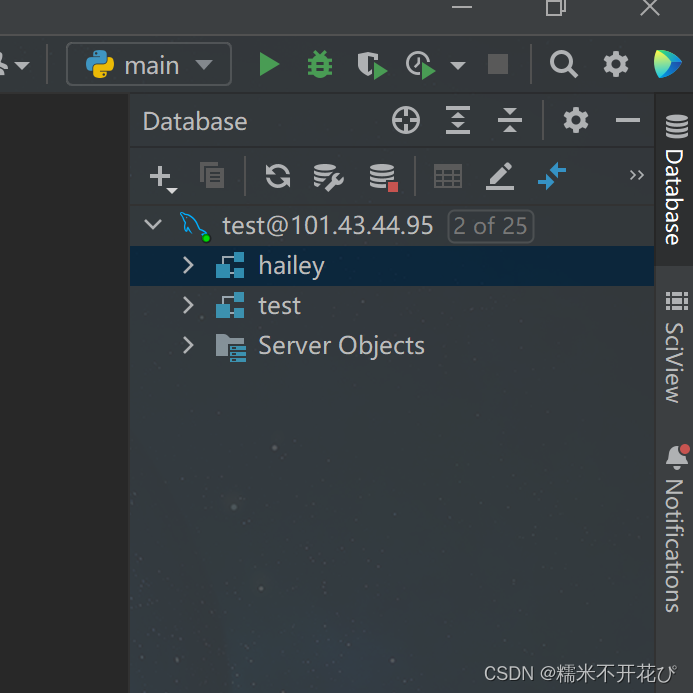
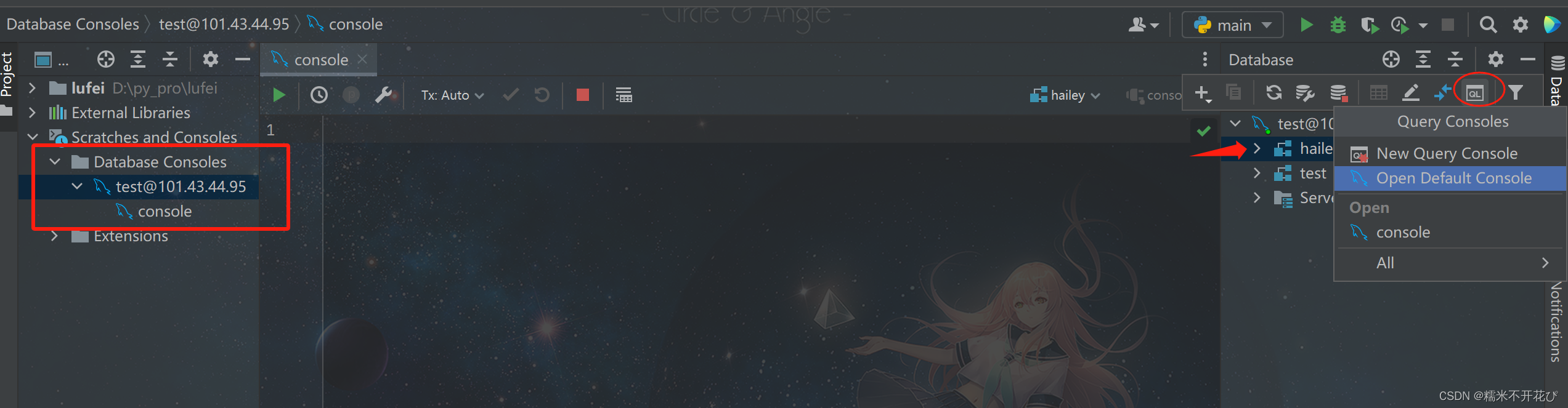
链接成功后,需要针对哪个库进行操作,就选中哪个库
点击右上角“QL”,New Query Console或者Open Default Console,就可以打开一个 Console界面
在 Console界面上就可以开始写sql语句
pymysql模块
例如社区版的pycharm不支持直接连接mysql,那么就需要编程语言链接Mysql
在python中,提供专门的第三方库来连接mysql:pymysql模块
● 安装pymysql:pip install pymysql
● 引用:import pymysql
简单的链接的和查询示例
import pymysql
#打开数据库:
db = pymysql.connect(
host="自己的链接名",user="用户名",
password="密码",
database="要访问的库名"
)
# 创建数据库的游标对象
cursor = db.cursor()
#使用execute()方法执行sql查询
cursor.execute("select * from emp")
#使用fetchone()方法获取单条数据:
data = cursor.fetchone()
print("ret:" ,data)
#获取所有:
data1 = cursor.fetchall()
print("ret1:" ,data1)
#关闭数据库
db.close()结果默认以元组形式返回:

如果想要结果以列表形式返回:
在连接参数中加上'cursorclass=pymysql.cursors.DictCursor'即可
import pymysql
#打开数据库:
db = pymysql.connect(
host="自己的链接名",user="用户名",
password="密码",
database="要访问的库名",
cursorclass = pymysql.cursors.DictCursor
)
# 创建数据库的游标对象
cursor = db.cursor()
#使用execute()方法执行sql查询
cursor.execute("select * from emp")
#使用fetchone()方法获取单条数据:
#获取所有:
data1 = cursor.fetchall()
print("ret1:" ,data1)
#关闭数据库
db.close()

增删改示例
import pymysql
#打开数据库:
db = pymysql.connect(
host="自己的链接名",user="用户名",
password="密码",
database="要访问的库名",
cursorclass = pymysql.cursors.DictCursor
)
# 创建数据库的游标对象
cursor = db.cursor()
# 向数据库插入数据:values括号里的值,需要用单引号,或者双引号
sql = "insert into emp values(10,'lily','female',25,'行政部','天津',9200)"
cursor.execute(sql)
# 执行数据库-改:
sql1 = 'update emp set gender = "female" where id = 1'
cursor.execute(sql1)
# 执行数据的-删:
sql2 = 'delete from emp where id = 2'
cursor.execute(sql2)
#提交事务;增删改都需要提交事务,否则不会生效
db.commit()
#关闭数据库
db.close()执行成功:
新增了id为10的记录
修改了id为1的gender
删除了id为2的记录

pymysql+类实现17k小说爬取
import requests
from lxml import etree
import pymysql
from pymysql.converters import escape_string
class xiaospider:
def __init__(self, user, pwd, database):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"}
self.session = requests.session()
self.initMysql(user, pwd, database)
self.initTable()
def initMysql(self, user, pwd, database):
self.conn = pymysql.connect(host=" ", port=3306, user=user, password=pwd, database=database,cursorclass=pymysql.cursors.DictCursor,charset="utf8")
self.cursor = self.conn.cursor()
def initTable(self):
sql1 = "create table if not exists book( id int primary key auto_increment,bookName varchar(32),coverImg varchar(255),authorPenName varchar(32))character set=utf8;"
self.query(sql1)
sql2 = "create table if not exists chapter( id int primary key auto_increment,chapter_name varchar(32),chapter_content text,book_id INT NOT NULL)character set=utf8;"
self.query(sql2)
def query(self, sql, args=None, one=True):
try:
with self.conn.cursor() as cursor:
cursor.execute(sql, args)
self.conn.commit()
if one:
return cursor.fetchone()
else:
return cursor.fetchall()
except Exception as e:
print(f"Error in query: {e}")
self.conn.rollback()
def login(self):
try:
res = self.session.post("https://passport.17k.com/ck/user/login",
headers=self.headers,
data={
"loginName": "用户名",
"password": "密码"
})
res.raise_for_status()
except requests.RequestException as e:
print(f"Error in login: {e}")
def get_books(self):
try:
res = self.session.get("https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919")
res.encoding = "utf8"
res.raise_for_status()
return res.json().get("data")
except requests.RequestException as e:
print(f"Error in get_books: {e}")
def get_book(self, data):
for bookDict in data:
bookId = bookDict.get("bookId")
Name = bookDict.get("bookName")
Img = bookDict.get("coverImg")
PenName = bookDict.get("authorPenName")
print(bookDict)
sql = "INSERT INTO book (bookName,coverImg,authorPenName) VALUES (%s, %s, %s);"
self.query(sql, (Name, Img, PenName))
self.get_chapter(bookId)
def get_chapter(self, bookId):
try:
res = self.session.get(f"https://www.17k.com/list/{bookId}.html")
res.encoding = "utf-8"
res.raise_for_status()
selector = etree.HTML(res.text)
lists = selector.xpath('//dl[@class="Volume"]//dd/a')
for list in lists:
href = list.xpath("./@href")[0]
chapter_title = list.xpath("./span/text()")[0].strip()
res = self.session.get("https://www.17k.com" + href)
res.encoding = "utf8"
res.raise_for_status()
seletor = etree.HTML(res.text)
chapters = seletor.xpath('//div[contains(@class, "content")]//div[@class="p"]/p[position()<last()]/text()')
chapter_content = "\n".join(chapters)
str_content = escape_string(chapter_content)
sql = "insert into chapter (chapter_name,chapter_content,book_id) values (%s, %s, %s);"
self.query(sql, (chapter_title, str_content, bookId))
except requests.RequestException as e:
print(f"Error in get_chapter: {e}")
def run(self):
self.login()
books = self.get_books()
self.get_book(books)
if __name__ == "__main__":
spider = xiaospider("mysql用户名","mysql密码","写入的库")
spider.run()执行后:写入的book表,存储书名、小说url、作者信息
 执行后,写入的chapter表:存储章节名、章节内容、书的id
执行后,写入的chapter表:存储章节名、章节内容、书的id
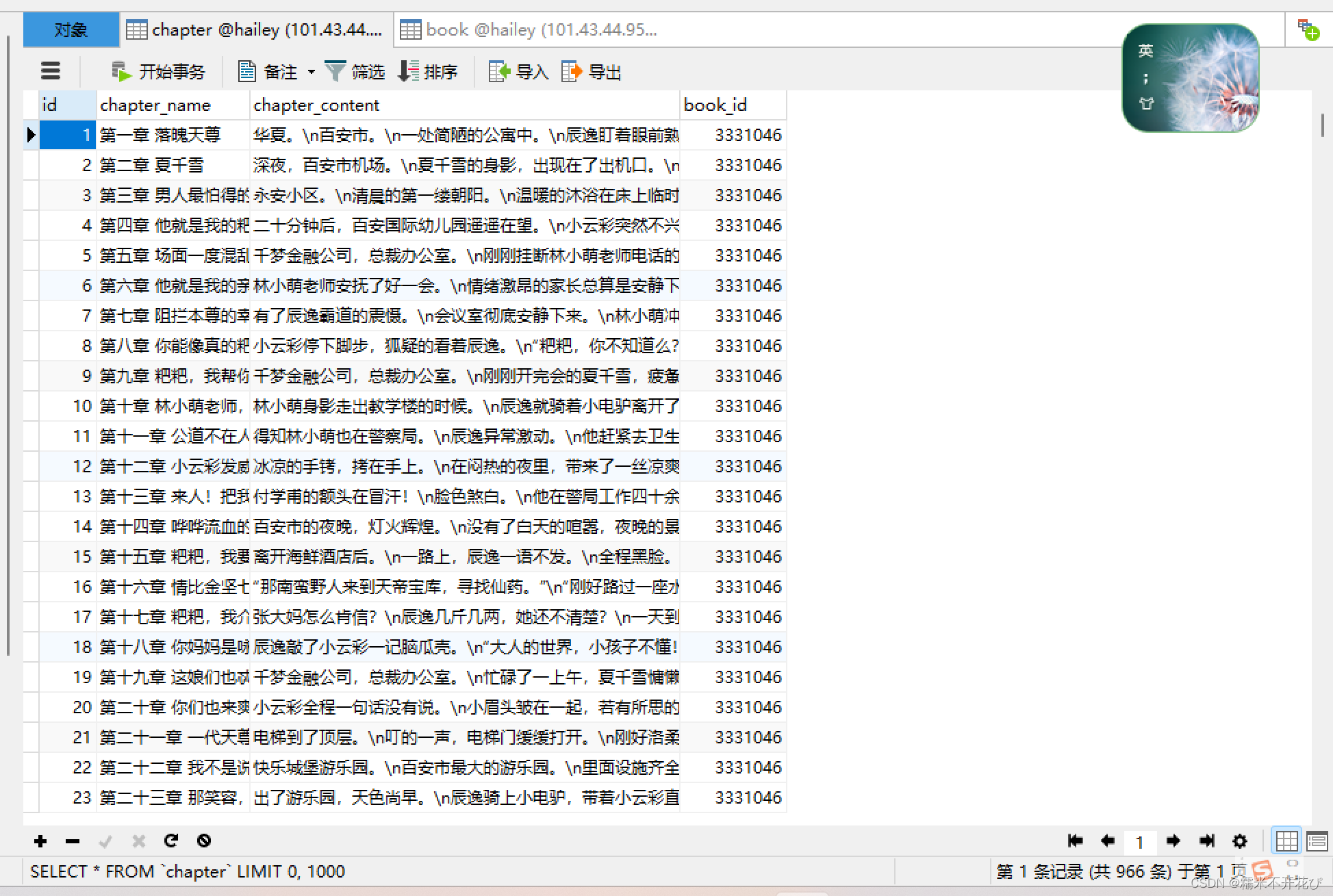
以上是一个简单的小说爬取,定义类结合mysql的封装,写入两张表
代码还有可以优化的空间,比如说换成协成版本,下载速度更快,后续有空再进行优化~














 1777
1777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









