






Optuna是一个自动超参数优化软件框架,专为机器学习而设计。它具有命令式、 运行时定义的用户 API。Optuna的用户可以动态地构建超参数的搜索空间。
optuna API
使用optuna
Optuna 与几乎所有可用的机器学习框架一起使用:TensorFlow、PyTorch、LightGBM、XGBoost、CatBoost、sklearn、FastAI 等。
安装optuna
pip install optuna
- 1
每个 Optuna 超参数调整会话称为学习。我们通过调用create_study方法来实例化一个学习会话。我们可以将几个重要的参数传递给这个方法,如下所示
import optuna
study = optuna.create_study(direction="maximize", sampler=optuna.samplers.TPESampler())
- 1
- 2
direction
direction value 可以设置为maximize或minimize,具体取决于我们的超参数调整的最终目标。
- 如果目标是通过准确度、F1 分数、精确度或召回率等指标来提高性能,则将其设置为maximize.
- 如果目标是减少损失函数,例如 log-loss、MSE、RMSE 等,则将其设置为minimize.
sampler
sampler value 指示您希望 Optuna 实施的采样器方法。您可以选择多个采样器选项,例如:
GridSampler:根据定义的搜索空间中的每个组合选择一组超参数值。RandomSampler:从定义的搜索空间中随机选择一组超参数值。TPESampler:这是sampler我们使用 Optuna
时的默认设置。它基于贝叶斯超参数优化,这是一种有效的超参数调整方法。它将像随机采样器一样开始,但该采样器记录了一组超参数值的历史以及过去试验的相应目标值。然后,它将根据过去试验的有希望的目标值集为下一次试验建议一组超参数值。
接下来,我们可以调用optimize我们学习中的方法,并将我们的objective函数作为参数之一传递。
import optuna
study = optuna.create_study(direction=“maximize”, sampler=optuna.samplers.TPESampler())
study.optimize(objective, n_trials=30)
- 1
- 2
- 3
- 4
上面的n_trials参数表示您希望 Optuna 在研究中执行的试验次数。
到目前为止,我们还没有创建objective 函数。所以让我们objective首先定义搜索空间来创建我们的函数。
搜索空间定义
在每个超参数调整会话中,我们需要为采样器定义一个搜索空间。搜索空间是采样器应该从超参数中考虑的值的范围。
例如,假设我们要调整三个超参数:学习率、层的单元数和神经网络模型的优化器。然后,我们可以定义搜索空间如下:
def objective(trial):params <span class="token operator">=</span> <span class="token punctuation">{<!-- --></span> <span class="token string">'learning_rate'</span><span class="token punctuation">:</span> trial<span class="token punctuation">.</span>suggest_loguniform<span class="token punctuation">(</span><span class="token string">'learning_rate'</span><span class="token punctuation">,</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">5</span><span class="token punctuation">,</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token string">'optimizer'</span><span class="token punctuation">:</span> trial<span class="token punctuation">.</span>suggest_categorical<span class="token punctuation">(</span><span class="token string">"optimizer"</span><span class="token punctuation">,</span> <span class="token punctuation">[</span><span class="token string">"Adam"</span><span class="token punctuation">,</span> <span class="token string">"RMSprop"</span><span class="token punctuation">,</span> <span class="token string">"SGD"</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token string">'n_unit'</span><span class="token punctuation">:</span> trial<span class="token punctuation">.</span>suggest_int<span class="token punctuation">(</span><span class="token string">"n_unit"</span><span class="token punctuation">,</span> <span class="token number">4</span><span class="token punctuation">,</span> <span class="token number">18</span><span class="token punctuation">)</span> <span class="token punctuation">}</span> model <span class="token operator">=</span> build_model<span class="token punctuation">(</span>params<span class="token punctuation">)</span> accuracy <span class="token operator">=</span> train_and_evaluate<span class="token punctuation">(</span>params<span class="token punctuation">,</span> model<span class="token punctuation">)</span> <span class="token keyword">return</span> accuracy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在objective函数中,我们传递了一个名为 的参数trial,它来自TrialOptuna 的类。此类使 Optuna 能够记录一组选定的超参数值,并objective在每次试验中记录我们的函数值(在我们的例子中是准确性)
正如您在上面看到的,我们将每个超参数的搜索空间定义为一个名为 的字典params。对于每个超参数,我们用方法定义搜索空间的范围(最小值和最大值)suggest_*。
该suggest_*方法有几个扩展,具体取决于超参数的数据类型:
suggest_int:如果您的超参数接受一系列整数类型的数值。suggest_categorical:如果您的超参数接受分类值的选择。suggest_uniform:如果您的超参数接受一系列数值,并且您希望对每个值进行同样的采样。suggest_loguniform:如果您的超参数接受一系列数值,并且您希望在对数域中对每个值进行同样的采样。suggest_discrete_uniform:如果您的超参数接受特定区间内的一系列数值,并且您希望每个值都以同样的可能性进行采样。suggest_float:如果您的超参数接受一系列浮点类型的数值。这是 , 和
的suggest_uniform包装suggest_loguniform方法suggest_discrete_uniform
构建 PyTorch 模型、训练循环和评估目标函数
现在我们可以使用保存在params字典中的选定超参数值来构建 PyTorch 模型。接下来,我们将训练模型并评估我们的目标函数,在我们的例子中是准确度。
import optuna
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# Build neural network model
def build_model(params):
in_features <span class="token operator">=</span> <span class="token number">20</span>
<span class="token keyword">return</span> nn<span class="token punctuation">.</span>Sequential<span class="token punctuation">(</span>
nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>in_features<span class="token punctuation">,</span> params<span class="token punctuation">[</span><span class="token string">'n_unit'</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">,</span>
nn<span class="token punctuation">.</span>LeakyReLU<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span>
nn<span class="token punctuation">.</span>Linear<span class="token punctuation">(</span>params<span class="token punctuation">[</span><span class="token string">'n_unit'</span><span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token number">2</span><span class="token punctuation">)</span><span class="token punctuation">,</span>
nn<span class="token punctuation">.</span>LeakyReLU<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token punctuation">)</span>
# Train and evaluate the accuarcy of neural network model
def train_and_evaluate(param, model):
df <span class="token operator">=</span> pd<span class="token punctuation">.</span>read_csv<span class="token punctuation">(</span><span class="token string">'heart.csv'</span><span class="token punctuation">)</span>
df <span class="token operator">=</span> pd<span class="token punctuation">.</span>get_dummies<span class="token punctuation">(</span>df<span class="token punctuation">)</span>
train_data<span class="token punctuation">,</span> val_data <span class="token operator">=</span> train_test_split<span class="token punctuation">(</span>df<span class="token punctuation">,</span> test_size <span class="token operator">=</span> <span class="token number">0.2</span><span class="token punctuation">,</span> random_state <span class="token operator">=</span> <span class="token number">42</span><span class="token punctuation">)</span>
train<span class="token punctuation">,</span> val <span class="token operator">=</span> Dataset<span class="token punctuation">(</span>train_data<span class="token punctuation">)</span><span class="token punctuation">,</span> Dataset<span class="token punctuation">(</span>val_data<span class="token punctuation">)</span>
train_dataloader <span class="token operator">=</span> torch<span class="token punctuation">.</span>utils<span class="token punctuation">.</span>data<span class="token punctuation">.</span>DataLoader<span class="token punctuation">(</span>train<span class="token punctuation">,</span> batch_size<span class="token operator">=</span><span class="token number">2</span><span class="token punctuation">,</span> shuffle<span class="token operator">=</span><span class="token boolean">True</span><span class="token punctuation">)</span>
val_dataloader <span class="token operator">=</span> torch<span class="token punctuation">.</span>utils<span class="token punctuation">.</span>data<span class="token punctuation">.</span>DataLoader<span class="token punctuation">(</span>val<span class="token punctuation">,</span> batch_size<span class="token operator">=</span><span class="token number">2</span><span class="token punctuation">)</span>
use_cuda <span class="token operator">=</span> torch<span class="token punctuation">.</span>cuda<span class="token punctuation">.</span>is_available<span class="token punctuation">(</span><span class="token punctuation">)</span>
device <span class="token operator">=</span> torch<span class="token punctuation">.</span>device<span class="token punctuation">(</span><span class="token string">"cuda"</span> <span class="token keyword">if</span> use_cuda <span class="token keyword">else</span> <span class="token string">"cpu"</span><span class="token punctuation">)</span>
criterion <span class="token operator">=</span> nn<span class="token punctuation">.</span>CrossEntropyLoss<span class="token punctuation">(</span><span class="token punctuation">)</span>
optimizer <span class="token operator">=</span> <span class="token builtin">getattr</span><span class="token punctuation">(</span>optim<span class="token punctuation">,</span> param<span class="token punctuation">[</span><span class="token string">'optimizer'</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">(</span>model<span class="token punctuation">.</span>parameters<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> lr<span class="token operator">=</span> param<span class="token punctuation">[</span><span class="token string">'learning_rate'</span><span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> use_cuda<span class="token punctuation">:</span>
model <span class="token operator">=</span> model<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span>
criterion <span class="token operator">=</span> criterion<span class="token punctuation">.</span>cuda<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">for</span> epoch_num <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span>EPOCHS<span class="token punctuation">)</span><span class="token punctuation">:</span>
total_acc_train <span class="token operator">=</span> <span class="token number">0</span>
total_loss_train <span class="token operator">=</span> <span class="token number">0</span>
<span class="token keyword">for</span> train_input<span class="token punctuation">,</span> train_label <span class="token keyword">in</span> train_dataloader<span class="token punctuation">:</span>
train_label <span class="token operator">=</span> train_label<span class="token punctuation">.</span>to<span class="token punctuation">(</span>device<span class="token punctuation">)</span>
train_input <span class="token operator">=</span> train_input<span class="token punctuation">.</span>to<span class="token punctuation">(</span>device<span class="token punctuation">)</span>
output <span class="token operator">=</span> model<span class="token punctuation">(</span>train_input<span class="token punctuation">.</span><span class="token builtin">float</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
batch_loss <span class="token operator">=</span> criterion<span class="token punctuation">(</span>output<span class="token punctuation">,</span> train_label<span class="token punctuation">.</span><span class="token builtin">long</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
total_loss_train <span class="token operator">+=</span> batch_loss<span class="token punctuation">.</span>item<span class="token punctuation">(</span><span class="token punctuation">)</span>
acc <span class="token operator">=</span> <span class="token punctuation">(</span>output<span class="token punctuation">.</span>argmax<span class="token punctuation">(</span>dim<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">)</span> <span class="token operator">==</span> train_label<span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span>item<span class="token punctuation">(</span><span class="token punctuation">)</span>
total_acc_train <span class="token operator">+=</span> acc
model<span class="token punctuation">.</span>zero_grad<span class="token punctuation">(</span><span class="token punctuation">)</span>
batch_loss<span class="token punctuation">.</span>backward<span class="token punctuation">(</span><span class="token punctuation">)</span>
optimizer<span class="token punctuation">.</span>step<span class="token punctuation">(</span><span class="token punctuation">)</span>
total_acc_val <span class="token operator">=</span> <span class="token number">0</span>
total_loss_val <span class="token operator">=</span> <span class="token number">0</span>
<span class="token keyword">with</span> torch<span class="token punctuation">.</span>no_grad<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">for</span> val_input<span class="token punctuation">,</span> val_label <span class="token keyword">in</span> val_dataloader<span class="token punctuation">:</span>
val_label <span class="token operator">=</span> val_label<span class="token punctuation">.</span>to<span class="token punctuation">(</span>device<span class="token punctuation">)</span>
val_input <span class="token operator">=</span> val_input<span class="token punctuation">.</span>to<span class="token punctuation">(</span>device<span class="token punctuation">)</span>
output <span class="token operator">=</span> model<span class="token punctuation">(</span>val_input<span class="token punctuation">.</span><span class="token builtin">float</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
batch_loss <span class="token operator">=</span> criterion<span class="token punctuation">(</span>output<span class="token punctuation">,</span> val_label<span class="token punctuation">.</span><span class="token builtin">long</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
total_loss_val <span class="token operator">+=</span> batch_loss<span class="token punctuation">.</span>item<span class="token punctuation">(</span><span class="token punctuation">)</span>
acc <span class="token operator">=</span> <span class="token punctuation">(</span>output<span class="token punctuation">.</span>argmax<span class="token punctuation">(</span>dim<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">)</span> <span class="token operator">==</span> val_label<span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span>item<span class="token punctuation">(</span><span class="token punctuation">)</span>
total_acc_val <span class="token operator">+=</span> acc
accuracy <span class="token operator">=</span> total_acc_val<span class="token operator">/</span><span class="token builtin">len</span><span class="token punctuation">(</span>val_data<span class="token punctuation">)</span>
<span class="token keyword">return</span> accuracy
# Define a set of hyperparameter values, build the model, train the model, and evaluate the accuracy
def objective(trial):
params <span class="token operator">=</span> <span class="token punctuation">{<!-- --></span>
<span class="token string">'learning_rate'</span><span class="token punctuation">:</span> trial<span class="token punctuation">.</span>suggest_loguniform<span class="token punctuation">(</span><span class="token string">'learning_rate'</span><span class="token punctuation">,</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">5</span><span class="token punctuation">,</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">,</span>
<span class="token string">'optimizer'</span><span class="token punctuation">:</span> trial<span class="token punctuation">.</span>suggest_categorical<span class="token punctuation">(</span><span class="token string">"optimizer"</span><span class="token punctuation">,</span> <span class="token punctuation">[</span><span class="token string">"Adam"</span><span class="token punctuation">,</span> <span class="token string">"RMSprop"</span><span class="token punctuation">,</span> <span class="token string">"SGD"</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">,</span>
<span class="token string">'n_unit'</span><span class="token punctuation">:</span> trial<span class="token punctuation">.</span>suggest_int<span class="token punctuation">(</span><span class="token string">"n_unit"</span><span class="token punctuation">,</span> <span class="token number">4</span><span class="token punctuation">,</span> <span class="token number">18</span><span class="token punctuation">)</span>
<span class="token punctuation">}</span>
model <span class="token operator">=</span> build_model<span class="token punctuation">(</span>params<span class="token punctuation">)</span>
accuracy <span class="token operator">=</span> train_and_evaluate<span class="token punctuation">(</span>params<span class="token punctuation">,</span> model<span class="token punctuation">)</span>
<span class="token keyword">return</span> accuracy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
运行超参数调优
我们已经创建了目标函数,我们已经定义了搜索空间,我们已经构建了模型和训练循环,现在我们准备好使用 Optuna 运行超参数调整。
要运行超参数调整,我们需要实例化一个study会话,调用optimize方法,并将我们的objective函数作为参数传递。
超参数调整过程完成后,我们可以通过访问best_trial方法来获取超参数的最佳组合,如下所示:
EPOCHS = 100
study = optuna.create_study(direction=“maximize”, sampler=optuna.samplers.TPESampler())
study.optimize(objective, n_trials=100)
- 1
- 2
- 3
- 4
best_trial = study.best_trial
for key, value in best_trial.params.items():
print(“{}: {}”.format(key, value))
# learning_rate: 0.0018518678521842887
# optimizer: Adam
# n_unit: 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
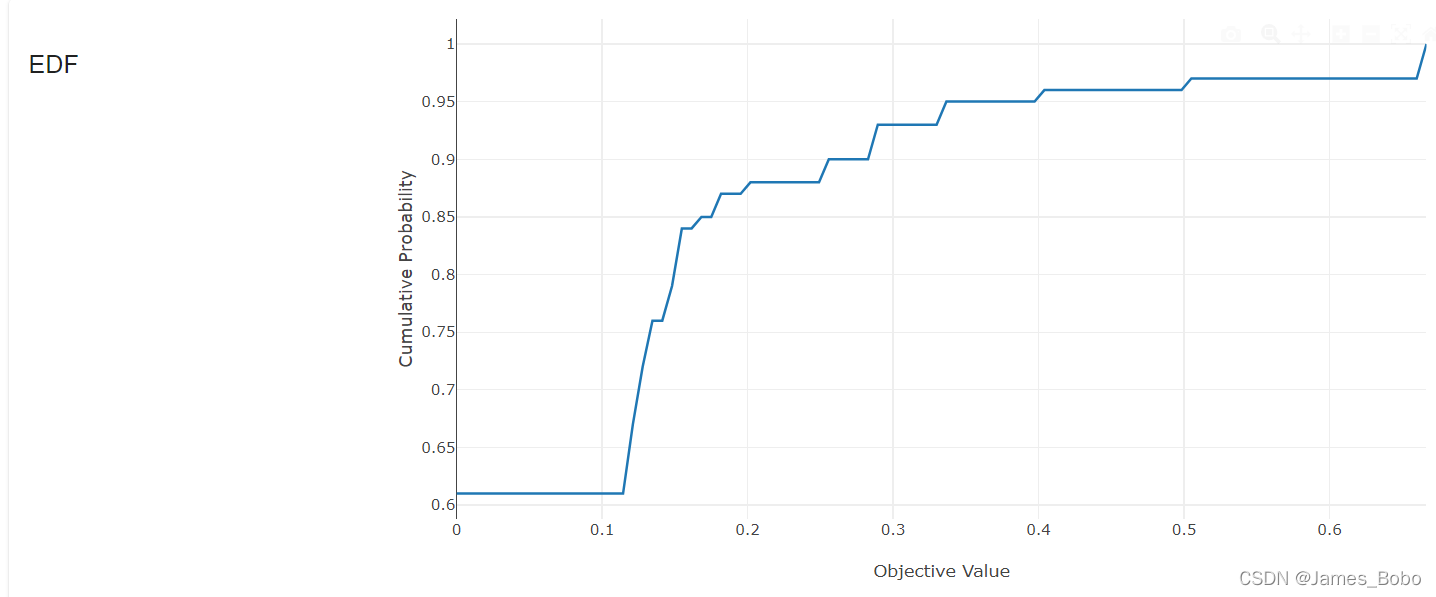
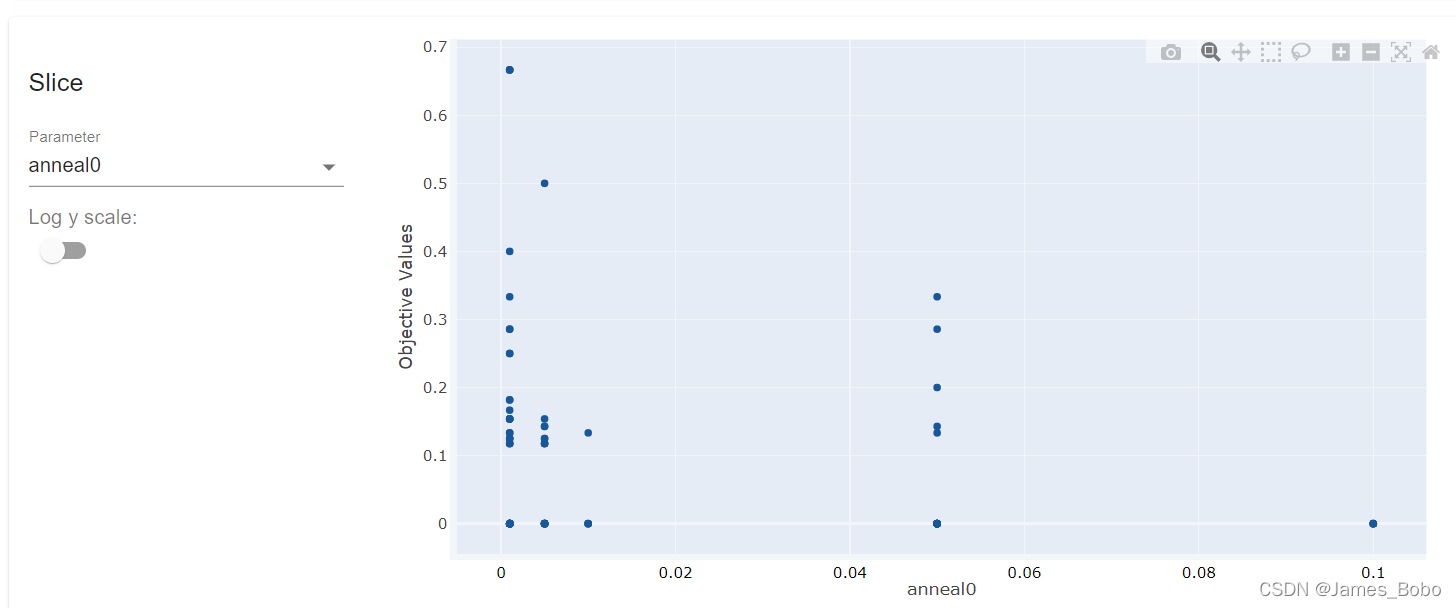
以下是某项目的调参案例展示
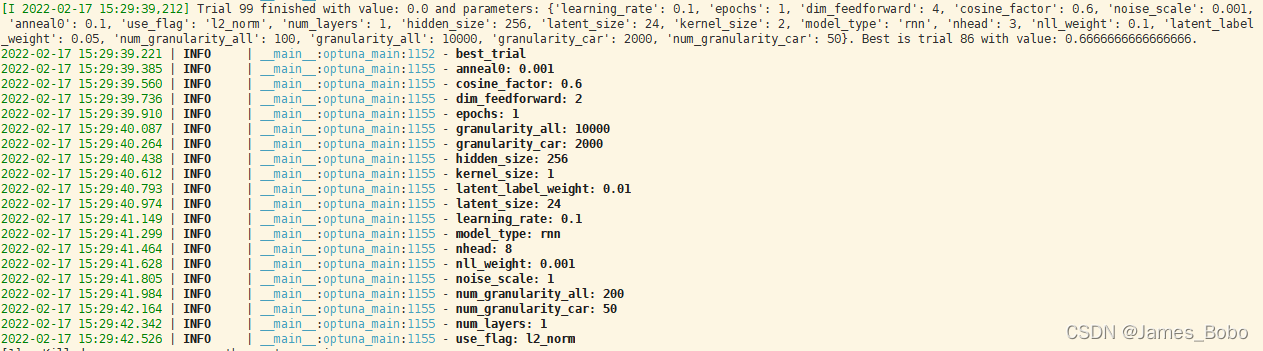
optuna可视化
Optuna 提供了一项功能,使我们能够在完成后可视化调整过程的历史。我们现在将介绍其中的一些。
第一个可视化是每个训练步骤中每个试验的目标函数图(在我们的例子中是准确性)。
optuna.visualization.plot_intermediate_values(study)
- 1
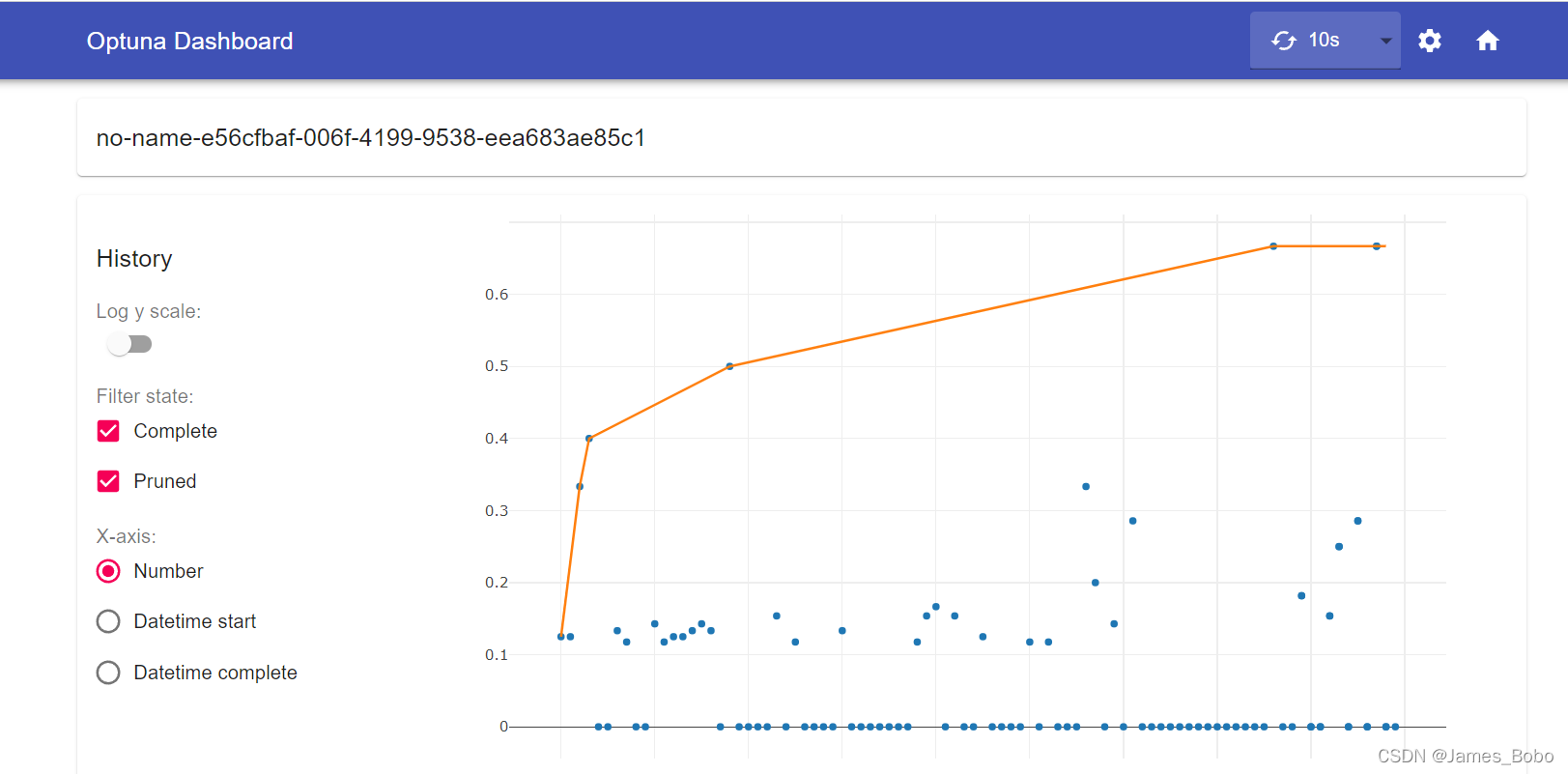
还可以将优化历史可视化:这种可视化有助于查看哪个试验是最佳试验,以及其他试验的客观价值与最佳试验相比如何。由于修剪机制,在特定试验中缺少几个数据点。
optuna.visualization.plot_optimization_history(study)
- 1
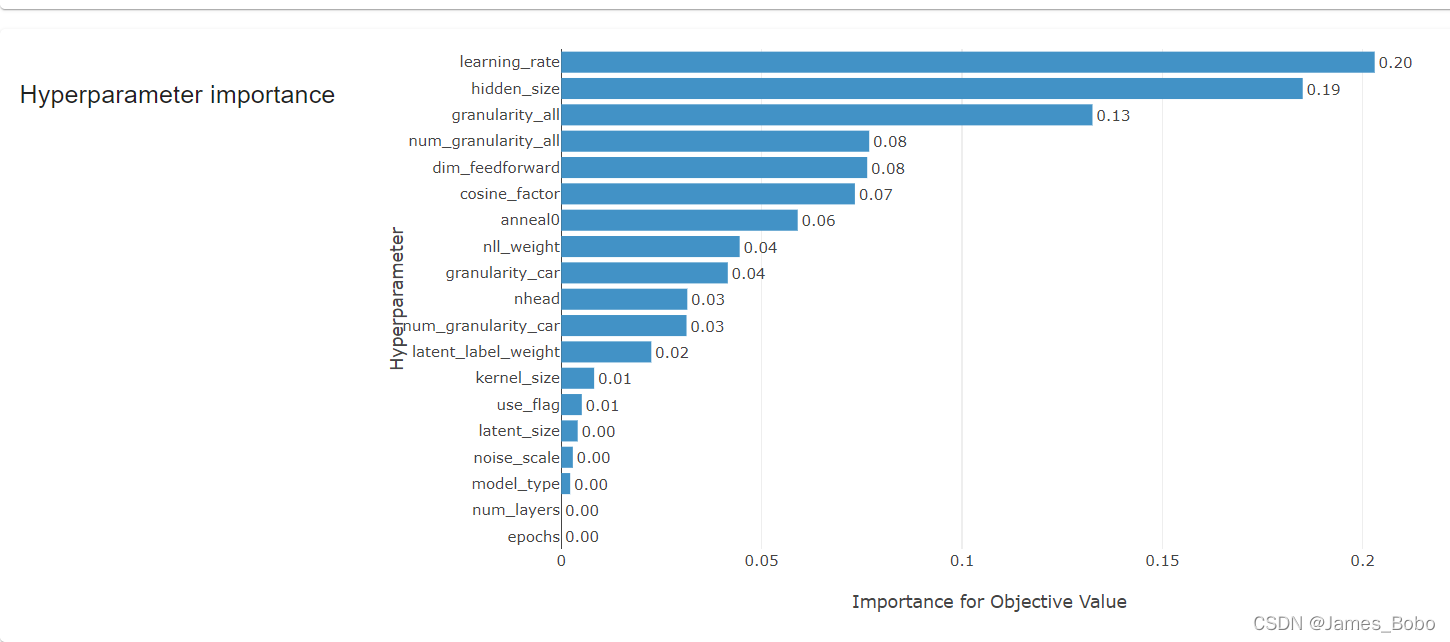
Optuna 还使我们能够绘制超参数的重要性,如下所示:
optuna.visualization.plot_param_importances(study)
- 1
optuna dashboard可视化
conda install -c conda-forge optuna-dashboard
pip install optuna-dashboard
- 1
- 2
study = optuna.create_study(study_name='test',direction="maximize",storage='sqlite:///db.sqlite3')
- 1
定义完后创建会话时,study_name指定了你的会话名称,direction为maximize或者minimize,最大或者最小,默认是最小,这里我们要让精确度最大,所以用maximize,storage定义了你的存储方式,这里我们用sqlite3,也可以用mysql等。
以上日志默认的保存位置在你当前的工作目录,会生成一个db.sqlite3的文件

再打开命令行或者anaconda-prompt,输入以下命令启动dashboard:
optuna-dashboard sqlite:///db.sqlite3
- 1
- 2
复制127.0.0.1:8080到你的浏览器里打开,就可以看到你的dashboard和study了:
如果指定服务器IP地址可使用
optuna-dashboard sqlite:///db.sqlite3 --host 0.0.0.0
- 1
复制IP:8080到你的浏览器里打开,同样可以看到你的dashboard和study
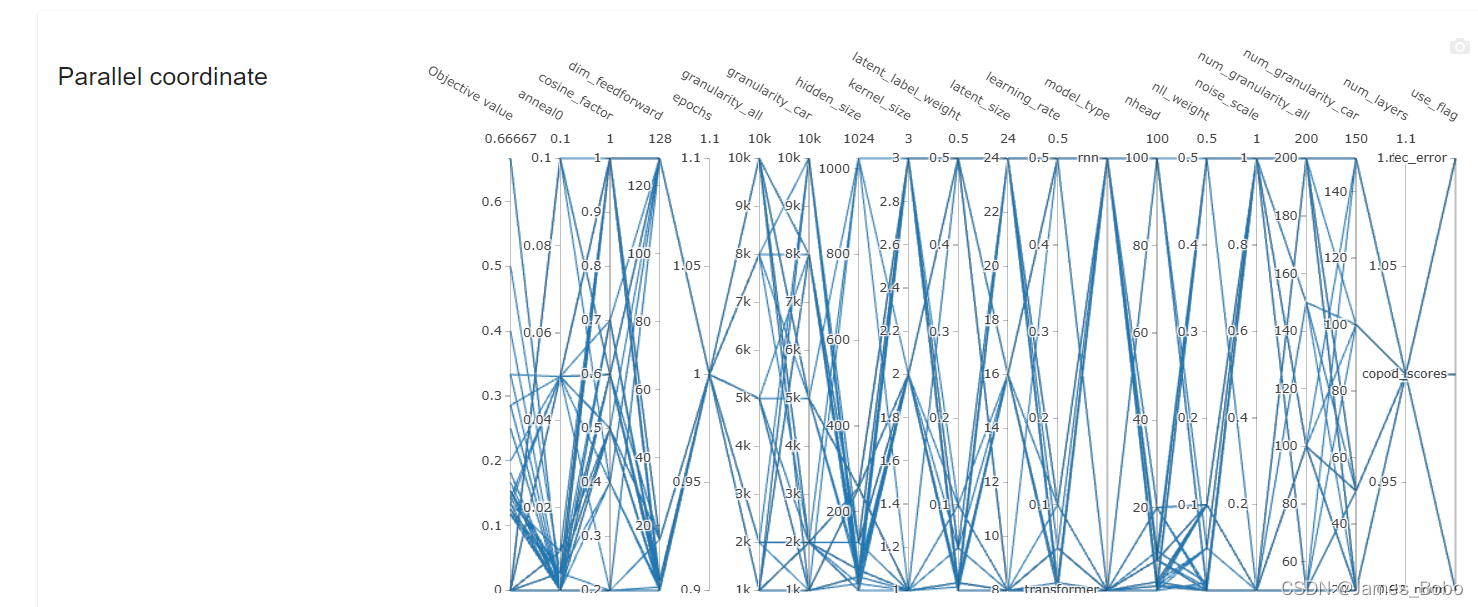


















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









