







补充:调参大法
1 训练调参打榜技巧
调参控制变量,每次调一个值。
1.初始化方式:FC/CNN用kaiming uniform或normalize,Emendding选截断normalize
2.activation function:sigmoid(淘汰)、tanh(淘汰)、relu(推荐)、leakey-relu
3.优化器:SGD+动量(对lr敏感,可以调很好 但很难)、Adma(对lr不敏感,容易上手 有上限)
4.lr:nlp在1e-5,cv在1e-3,最好多手动调。
5.Batch size:一般越大越好,GPU不行 使用累计梯度,太小不收敛。
6.Dropout:注意dropout rate,不一定默认值最好。
7.input序列用LN,input非序列用BN
8.使用大数据集的预训练权重,基于backbone的层次化neck(如FPN/PAN) 优于 直接在最后输出的网络
9.reduce function中,attention 优于 简单的pooling
10.数据增强要根据任务具体设计。
11.模型规模大小要与数据量匹配。
12.使用半监督学习策略,自动化从测试集中获取补充数据。
13.自监督学习。
14.添加能够提升泛化性能的模块,靠积累
15.难样本挖掘降低噪声标签(错误标签)的影响
16.直接在损失函数上考虑噪声的影响,靠数学功底
17.对数据集进行重采样(补充量少样本)/难样本挖掘,缓解样本类别不均衡
18.在损失函数上解决数据类别不均衡
19.模型训练时,多尝试不同的感受野(卷积核大小),解决大尺存图像(如1024x1024)处理问题。
20.如有必要,在训练集增加多尺度数据增强。
21.测试时,设置合理的预测尺度,避免训练与测试产生偏差
22.测试时数据增强TTA,一张图像变换成多种图像进行预测,多张图像的预测结果联合判断。
23.集成学习Ensemble Learning,多个模型预测的结果联合判断。
2 正确的调参之路
先过拟合,再尝试减小模型复杂度,加正则化
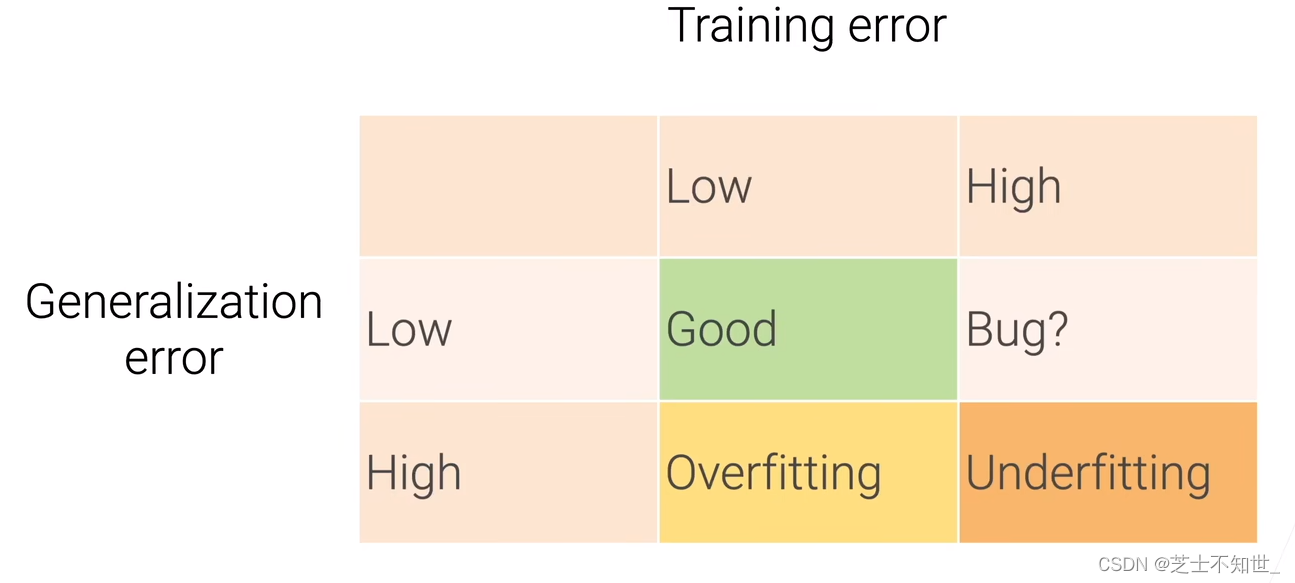
防止过拟合
1.减小模型复杂度
2.relu
3.pooling
4.dropout
5.L2正则:深度学习在softmax处的loss函数中加。
6.BN

















 3701
3701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











