






一、AnnData
1.AnnData 介绍与结构
AnnData 是用于存储数据的对象,一般作为 scanpy 的数据存储格式。
使用前事先按照scanpy库
pip install scanpyanndata 是一个 Python 软件包,用于处理内存和磁盘中的注释数据矩阵,介于 pandas 和 xarray 之间。anndata 提供了大量高效的计算功能,包括 sparse data support, lazy operations, and a PyTorch interface.
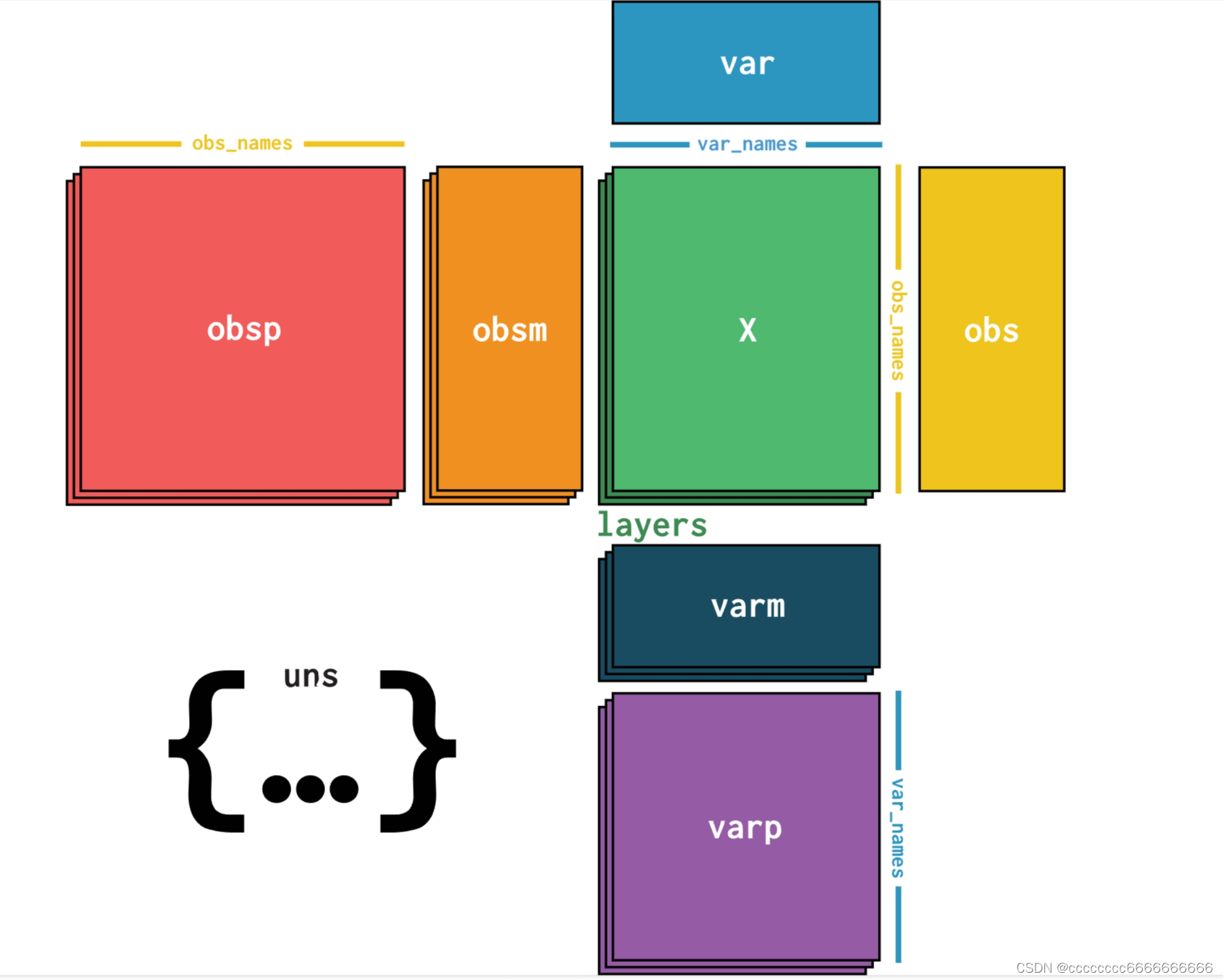
1.1 数据结构: Anndata 是一个表格式的数据结构,类似于数据帧(DataFrame),但专门用于高维生物数据。它包括以下主要组件:
- X(数据矩阵): 存储单细胞数据的核心矩阵,通常是一个二维数组,其中行表示细胞,列表示特征(基因或其他测量值)。
- obs(观测信息): 包括每个细胞的元信息,如样本名称、细胞类型、质量信息等。
obs是一个观测特征的字典。 - var(变量信息): 包括每个特征(基因)的元信息,如基因名、功能注释等。
var是一个变量特征的字典。 - layers(层): 可以存储其他数据层,如归一化后的数据或差异表达分析的结果。
- uns(未排序的数据): 用于存储其他未排序的数据和元信息
1.2 创建 Anndata 对象: 可以使用 Anndata 构造函数创建一个 Anndata 对象。
import anndata as ad
adata = ad.AnnData(X=data_matrix, obs=obs_info, var=var_info)1.3 数据操作: Anndata 允许您执行多种数据操作,包括切片、过滤、转置、连接数据、添加元信息等。
# 切片数据
subset_data = adata[:, list_of_genes]
# 过滤细胞
adata = adata[adata.obs['quality'] > 0.9]
# 转置数据
adata_T = adata.T1.4 数据可视化: Anndata 可以与 scanpy 或其他可视化工具结合使用,以可视化数据、绘制UMAP、t-SNE图等。
import scanpy as sc
sc.tl.pca(adata)
sc.pl.umap(adata, color='cell_type')1.5 数据存储: Anndata 可以将数据存储为HDF5文件,以便将数据持久化和共享。
adata.write('my_data.h5ad')1.6 高维数据处理: Anndata 不仅适用于单细胞RNA测序数据,还适用于其他高维生物数据,如蛋白质质谱数据、多组学数据等。
| 功能 | 数据类型 | |
| adata.X | 矩阵信息 | numpy,scipy scarse,matrix |
| adata.obs | 细胞信息(观测量) | pandas dataframe |
| adata.var | 基因信息(特征量) | pandaframe |
| adata.uns | 非结构信息 | dict 有序字典 |
Single Cell Visualizations — CellGenIT Docs 2023.300 documentation

















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









