






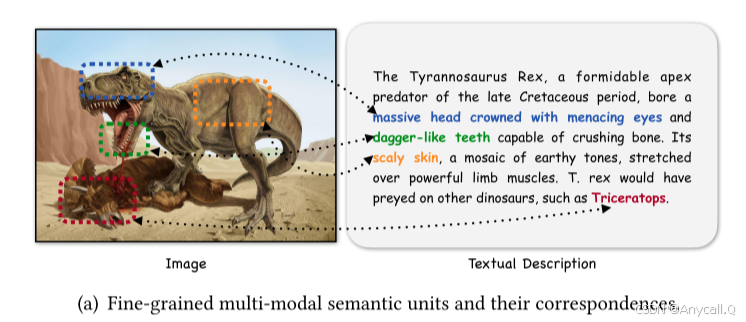
在图 1(a) 中展示了一个简单的案例,以显示实体 T-Rex 的图像和文本中的这些细粒度语义单元,即图像片段和文本短语。 这些细粒度的语义特征不仅描述了实体,而且体现了复杂的跨模态关系。 我们提倡更细粒度的框架,允许 MMKGC 模型通过详细的交互捕获数据中嵌入的微妙的共享信息。 这种方法有望显着增强实体表示。
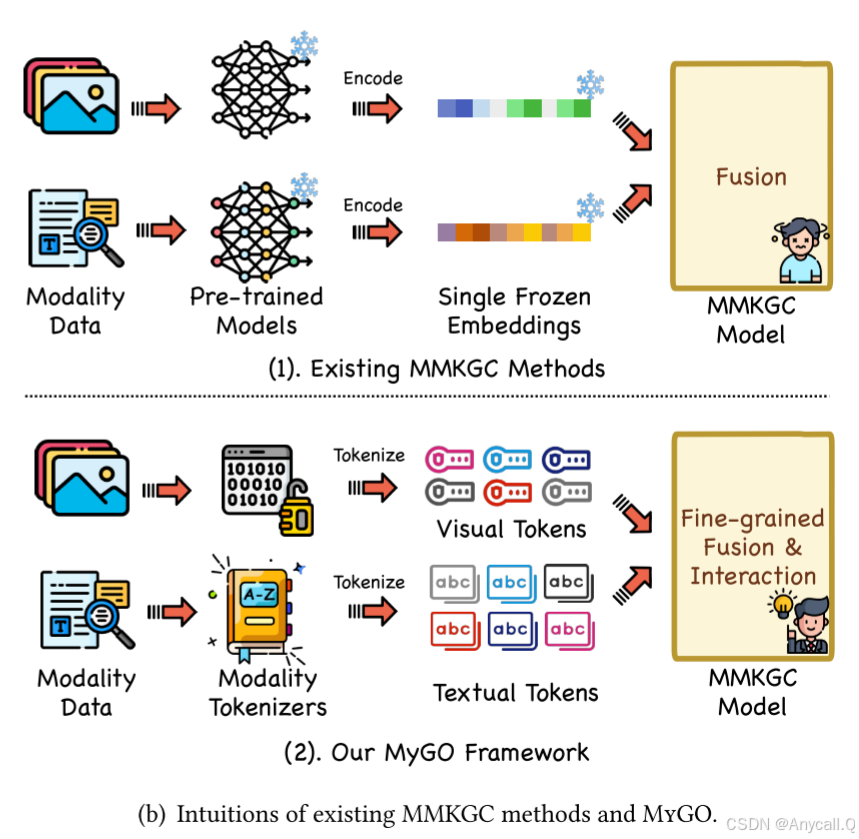
图 1(b) 给出了现有 MMKGC 方法和我们的 MyGO 之间的清晰对比。 MyGO 首先采用模态标记化 (MT) 模块,使用现有的预训练标记器 [9, 24] 将 MMKG 中的实体模态信息标记为细粒度离散标记序列,然后通过分层三重建模 (HTM) 架构学习 MMKGC 任务 。 HTM 由跨模态实体编码器、上下文三重编码器和关系解码器组成,用于对细粒度实体表示进行编码并测量三重似然性。 为了进一步增强和细化实体表示,我们提出了细粒度对比损失(FGCL)来生成各种对比样本并提高模型性能。
MyGO主要由三个模块组成:模态标记化模块、层次三元组建模模块和细粒度对比学习,分别旨在处理、融合和增强MMKG中的细粒度信息。
1、模态标记化模块(Modality Tokenization)
为了捕获细粒度的多模态信息,我们提出了一种模态标记化(MT)模块,将实体的原始多模态数据处理为细粒度的离散语义标记,作为学习细粒度实体表示的语义单元。
我们分别使用图像和文本模态的标记器(表示为 Q𝑖𝑚𝑔、Q𝑡𝑥𝑡)来为实体 𝑒 生成视觉标记 𝑣𝑒、𝑖 和文本标记 𝑤𝑒、𝑖:
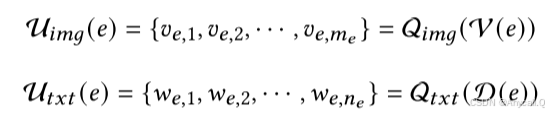
其中𝑚𝑒,𝑛𝑒是每种模式的 tokens 数量,我们表示U(𝑒)表示实体 𝑒 的集体 tokens 集。 文本标记来自语言模型的词汇表,而视觉标记来自预训练的视觉标记器的码本。 值得注意的是,V(𝑒)可能由多个图像组成,我们对每个图像进行处理以在U i𝑚𝑔(𝑒)中累积 tokens。
在标记化过程中,经常会遇到重复的标记,因为某些子词可能在一个句子中出现多次,并且类似的语义元素可能在实体图像中反复出现。 因此,我们计算每个标记的出现频率,为每个模态保留预定数量的最常见标记。 此外,我们删除了文本描述中的停止词,因为它们对实体语义的贡献很小。 经过这样的细化后,我们为MMKG中的每个实体保留 𝑚 视觉标记和 𝑛 文本标记。 对于那些tokens不足或缺少模态数据的实体,我们添加一个特殊的填充 token 来填补空白。 经过MT和精化处理后,我们可以为每个实体 𝑒 获得经过处理的标记集![]() 和
和![]() ,其特征是一组细粒度标记,这些标记体现了从原始多模态数据中派生出来的重要特征。 随后,我们分别为
,其特征是一组细粒度标记,这些标记体现了从原始多模态数据中派生出来的重要特征。 随后,我们分别为![]() 和
和![]() 中的每个 token 分配一个单独的嵌入。 这种方法是针对不同实体可能共享 token 这一事实量身定制的,token 的个性化嵌入允许对不同实体之间的相似特征进行更细粒度的表示,从而使用详细的多模态语义单元丰富实体的配置文件。
中的每个 token 分配一个单独的嵌入。 这种方法是针对不同实体可能共享 token 这一事实量身定制的,token 的个性化嵌入允许对不同实体之间的相似特征进行更细粒度的表示,从而使用详细的多模态语义单元丰富实体的配置文件。
与现有的MMKGC方法不同,MT技术将模态信息转换为更细粒度的离散标记。 当面对一种模态的多个信息(例如一个实体的多个图像)时,传统的 MMKGC 会在之前对它们进行聚合(例如平均)。 然而,MT 保留了一系列代表来自各种原始数据源的最普遍特征的标记,这可以更加稳定和可扩展地增加模态信息。
2、分层三重建模(Hierarchical Triple Modeling)
在 MT 过程之后,设计了一个分层三重建模(HTM)模块。 HTM利用分层转换器体系结构来捕获多模态实体表示,并以逐步的方式对三重合理性建模,它由三个组件组成:跨模态实体编码器、上下文三重编码器和关系解码器
(1)跨模态实体编码器(Cross-modal Entity Encoder)
跨模态实体编码器(CMEE)旨在通过利用实体的细粒度多模态token来捕获实体的多模态表示。 与现有方法不同,现有方法使用单个嵌入表示每种模态,然后设计融合策略将它们合并,MyGO对不同模态进行细粒度标记化,并获得每种模态的标记序列。 因此,我们设计了一种更细粒度的特征交互方法,允许所有不同模态消息之间的完全交互。 在MyGO中,我们使用 transformer 层作为CMEE。 我们首先将多模态标记线性化为序列X:
![]()
其中[ENT]是一个特殊的序列,𝑠𝑒是一个表示实体结构信息的可学习嵌入。 [ENT]类似于BERT[9]中的[CLS]token,用于捕获下游预测的序列特征。 𝑠𝑒是一个可学习的嵌入,用来表示从现有的三元组结构中学习到的结构信息,在训练过程中对其进行优化。 此外,对于来自![]() 和
和![]() 的多模态标记,我们冻结了它们由标记器派生的初始表示,并定义了线性投影层
的多模态标记,我们冻结了它们由标记器派生的初始表示,并定义了线性投影层![]() ,将它们投影到与以下相同的表示空间中:
,将它们投影到与以下相同的表示空间中:
![]()
其中𝑏-𝑚𝑔,𝑏𝑡-𝑡是定义的模态偏差,以增强来自不同模态的信息标记。 我们的目标不是调整基本序列特征,而是通过训练投影层来提高它们的集成(有效地整合信息),以获得更好的泛化。 这样,最终进入CMEE的序列为:
![]()
跨模态实体表示可以通过以下方式捕获:
![]()
其中Transformer()表示具有自关注层和前馈层的传统变压器编码器层,Pooling是池化操作,获得特殊token[ENT]的最终隐藏表示。 它允许CMEE动态突出显示输入序列中的每个标记,以便交互并最终学习具有表现力的实体表示。
(2)上下文三重编码器(Contextual Triple Encoder)
为了在关系上下文中实现足够的模态交互,我们应用另一个转换器层 sd 上下文三重编码器(CTE)来对给定查询的上下文嵌入进行编码。 以头查询 (ℎ, 𝑟, ?) (尾部预测)为例,我们可以获得上下文嵌入 h~ 为:
![]()
其中[CXT]是输入序列中捕获实体上下文嵌入的特殊标记,h是来自CMEE的<s:1>的输出表示,r是每个𝑟∈r的关系嵌入。查询(h,𝑟,?)的上下文嵌入然后由关系解码器处理以进行实体预测。
(3)关系解码器(Relational Decoder)
此外,采用得分函数 S(ℎ, 𝑟, 𝑡) 通过生成标量得分来测量三元组似然性,该标量得分充当查询预测的关系解码器。 在 MyGO 中,采用 Tucker 作为我们的评分函数,表示为:
![]()
其中×𝑖表示沿第i个模式的张量积,W是训练期间学习到的核心张量。 我们用每个三元组的交叉熵损失来训练我们的模型。 我们将𝑡视为针对整个实体集E的黄金标签,这与头部预测相同。 因此,训练目标是交叉熵损失:
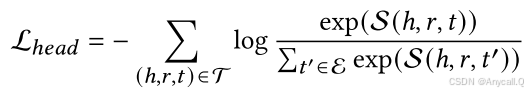
请注意,我们使用ℎ的上下文嵌入〜eℎ和𝑡的多模态嵌入e𝑡来计算分数,这可以加快计算速度。 否则,我们需要提取不同关系下所有候选实体的上下文嵌入,这需要上下文转换器中的𝑂(|E| × |R|)级前向传递,并且会大大增加模型的计算量。 此外,MyGO 中同时考虑了头预测和尾预测,并且在给出尾查询 (?, 𝑟, 𝑡) 时,目标 L𝑡𝑎𝑖𝑙 类似:
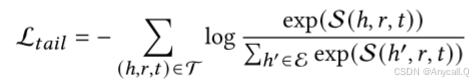
总体 MMKGC 任务目标可以表示为:
![]()
3、细粒度对比学习
为了进一步增强细粒度和鲁棒的多模态实体表示,在 MyGO 中引入了细粒度对比学习(FGCL)模块,通过对实体表示进行多尺度对比学习来实现这一目标。 如前所述,CMEE 旨在捕获基于多模态token序列的实体表示。 受到 SimCSE 思想的启发,我们通过对比学习增强这些实体表示。 具体来说,给定一个实体 𝑒,可以通过两次前向传递从 CMEE 获得两个表示 e, e𝑠𝑒𝑐。 由transformer编码器中的 dropout 层引起的这两个嵌入之间的变化允许稍微停用多模态token特征,有效地充当简单数据的形式增强。 通过对实体集合进行批量对比学习,MyGO 被训练为从标记序列中提取真正重要的信息,从而增强每个实体表示的独特性。 为了加深这个过程的粒度,我们进一步从transformer输出中提取三个额外的表示,它们可以从他们的角度表示实体特征。 我们可以将输入序列 X𝑖𝑛𝑝𝑢𝑡 (𝑒) 中多模态标记的输出表示定义为:
![]()
然后我们引入三个嵌入 s(𝑒)、v(𝑒)、w(𝑒) 来表示实体 𝑒 的全局、视觉和文本信息。 s(𝑒) 源自 X𝑜𝑢𝑡𝑝𝑢𝑡 (𝑒) 中所有输出表示的平均值。 类似地,v(𝑒) 和 w(𝑒) 是相应视觉和文本标记的平均值。 它们可以表示为:
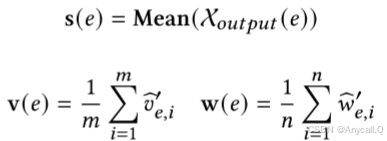
在这些嵌入中,e𝑠𝑒𝑐,s(𝑒)封装了𝑒的全局信息,v(𝑒),w(𝑒)包含了局部模态信息。 对于每个实体𝑒,我们可以收集其用于对比学习的候选对象为 C(𝑒) = {𝑒𝑠𝑒𝑐, s(𝑒), v(𝑒), w(𝑒)},它由其全局和局部特征组成。 (e, e′) 其中 e′ ∈ C(𝑒) 被视为正样本。 然后我们采用批量负采样来构建负对,并使用 InfoNCE [32] 作为对比主干。 最终的 FBCL 目标可以表示为:
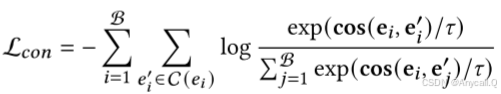
其中 B 是批量大小,cos(·,·) 是两个嵌入的余弦相似度,𝜏 是温度超参数。 通过这样的 FGCL 过程,MyGO 显着提高了识别各种实体的详细多模态属性的能力,从而提高了 MMKGC 任务中的模型性能。 最后,我们框架的总体训练目标可以表示为:
![]()
其中 𝜆 是控制对比损失 L𝑐𝑜𝑛 权重的超参数。

















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









