






使用正则表达式爬取微博热搜数据!
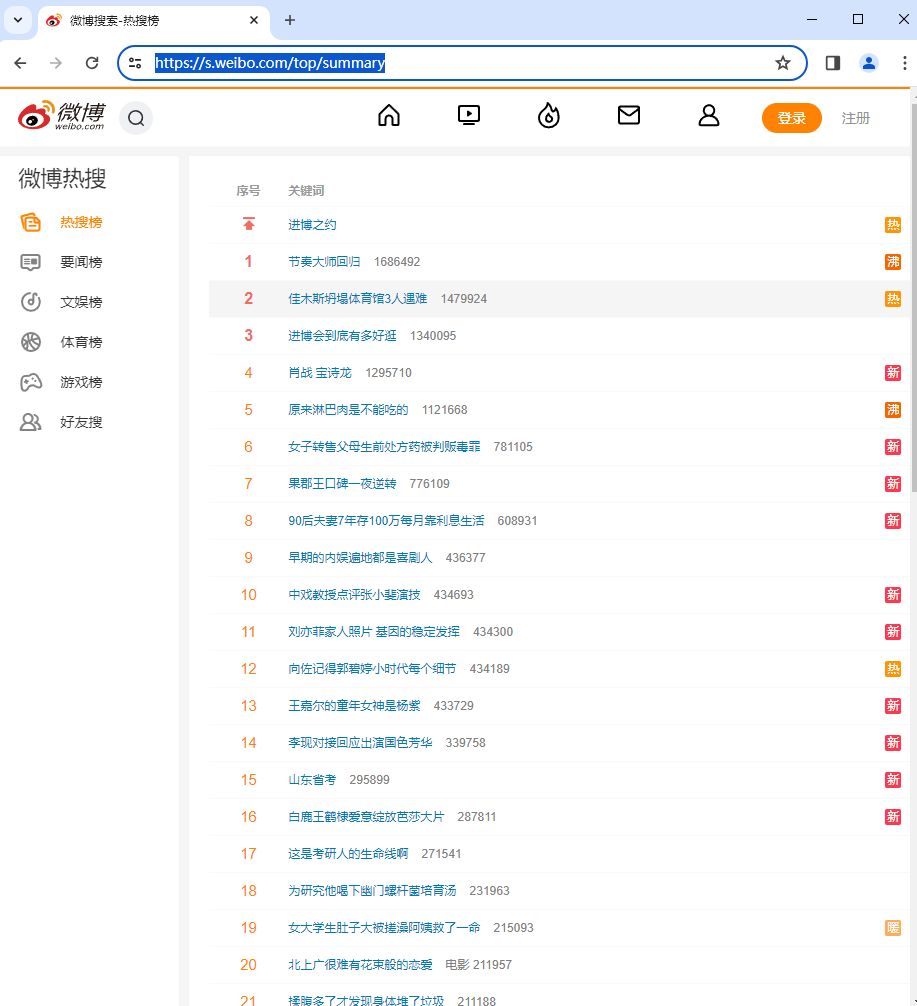
1、进入热搜界面
微博热搜榜
url = https://s.weibo.com/top/summary
2、正则表达式提取数据

3、代码
#导入库
import requests
import re
#定义url
url = "https://s.weibo.com/top/summary"
#定义请求头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Cookie":"SUB=_2AkMSFSgff8NxqwFRmfoUz2zqaY5xzAzEieKkSdnEJRMxHRl-yT9kqhQFtRB6OZUG8DOhkAQ8j_qHBaGKAku_zP90cjic; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWCfjAfiRIOXvA0B54X0yID; _s_tentry=-; Apache=1853274244289.8064.1699325762700; SINAGLOBAL=1853274244289.8064.1699325762700; ULV=1699325762707:1:1:1:1853274244289.8064.1699325762700:",
}
#发送请求,获取响应
response = requests.get(url,headers=headers)
#解码
content = response.content.decode('utf8') #content已经是html字符串了
#正则表达式提取数据
contents = re.findall('<td class="td-02".*?<a.*?>(.*?)</a>',content,re.DOTALL)[1:]# [1:]切片第一个没有数据的数据
#print(contents)
hots = re.findall('<td class="td-02".*?<span>(.*?)</span>',content,re.DOTALL)
#print(hots)
#存储数据
sinas=[]
for cont,hot in zip(contents,hots):
sina ={
"content":cont,
"hot":hot
}
sinas.append(sina)
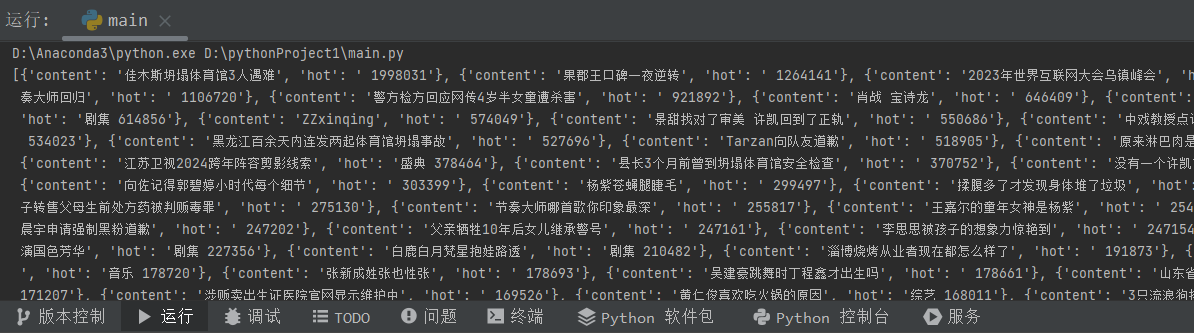
print(sinas)
- 结果:


















 1850
1850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









