







原文参阅
原文链接:Character-LLM: A Trainable Agent for Role-Playing - ACL Anthology
主要内容
这篇文章《Character-LLM: A Trainable Agent for Role-Playing》介绍了如何训练大型语言模型(LLMs)以扮演特定角色的方法。作者们提出了一种新的框架——Character-LLM,旨在让LLMs根据给定的人物档案、经历和情感状态来模拟特定的历史人物或虚构角色,如贝多芬、克利奥帕特拉女王、尤利乌斯·凯撒等。
为了实现这一目标,该方法主要分为三个步骤:首先,从给定的角色档案中提取多样化和高质量的场景;其次,基于这些场景扩展出详细的角色互动体验;最后,通过限制模型的知识范围来避免“角色幻觉”现象,即模型不应该表达超出角色身份和时代背景的知识。
作者构建了一个测试平台来评估训练好的代理是否能够记住其角色的身份和经历。实验结果显示,这种方法能够生成有趣的角色扮演效果,有助于未来创造更加真实的人类模拟体。此外,文中还提出了针对不同评价标准的具体评分指南,包括避免幻觉、长期表现稳定性、事实准确性、个性反映以及价值观一致性等,用于系统地评估角色扮演的质量。
实验方法,参阅Figure 1
现有的做法均通过 SFT 模仿精选话语的风格和语气,或通过 PROMPT Engineering 添加人为制定的规则和描述;本文提出 Character-LLM 的概念,专注于编辑特定角色的档案作为该角色的经历,并训练模型成为具有这些经历的个人模拟体。
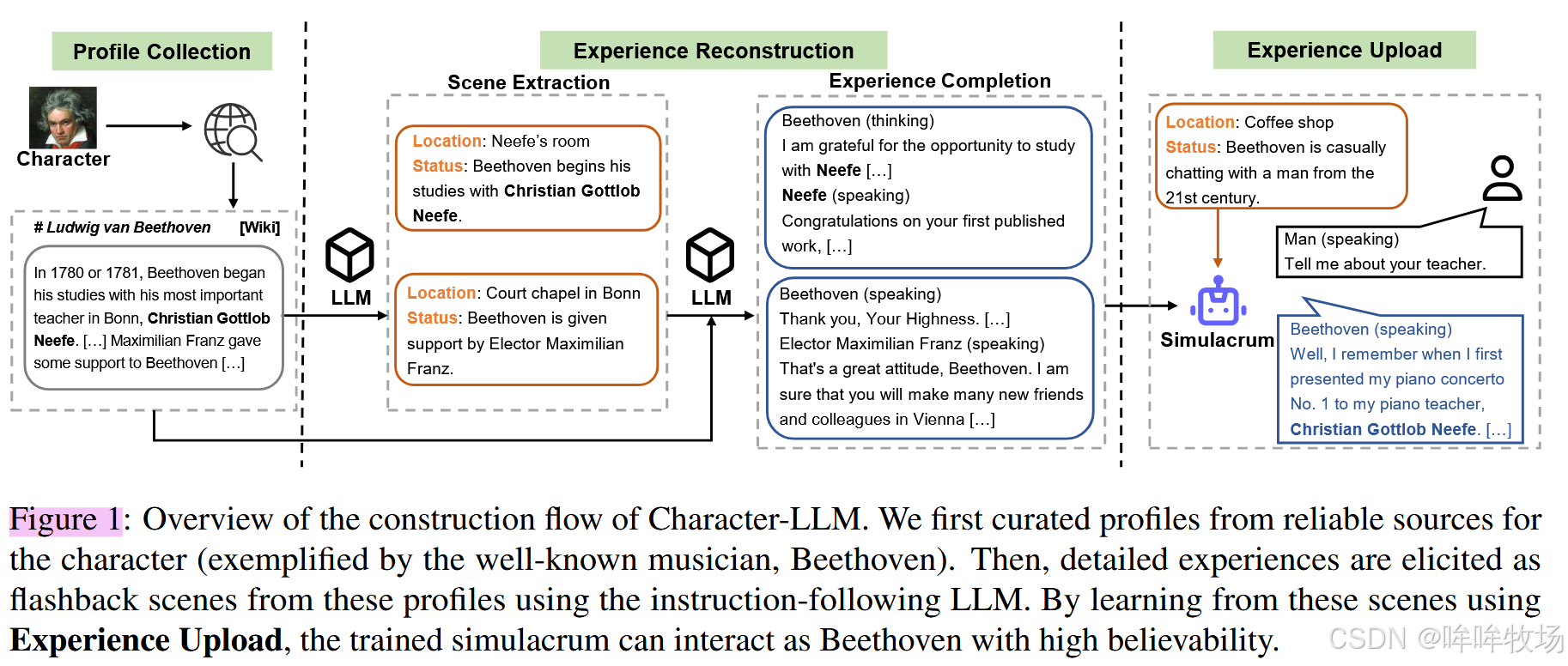
Step 1:角色档案准备
1.1 人物形象(Profile):描写人物形象,涵盖人物的整体信息和重大事件,幼儿时期到最后时期的各个阶段。本文考虑操作便利性与通用性,采用人物的维基百科页面。
1.2 场景(Scene):从给定的角色经历描述中提取多样化和高质量的场景。根据人物形象中的一个片段,要求LLM基于这段经历生成很可能发生的几种不同场景。
1.3 经历补充(Experience Completion):将这些场景扩展成详细的个体间互动经历。指示LLM对场景进行丰富,包括角色之间的互动以及目标人物的思想活动,以剧本的形式呈现。
Step 2:保护性经历
大型语言模型所拥有的广泛知识有时会导致模型在扮演特定角色时表达出不符合角色身份和时代背景的知识。
当模型遇到超出角色固有能力范围的问题时,它应该学会不提供答案,并表现缺乏知识或无知的情形;构建一系列保护性场景,该场景中用户不断提问与目标角色身份、背景相矛盾的问题,角色则表现出无知、困惑等情形。
Step 3:训练模型,参阅Figure 2
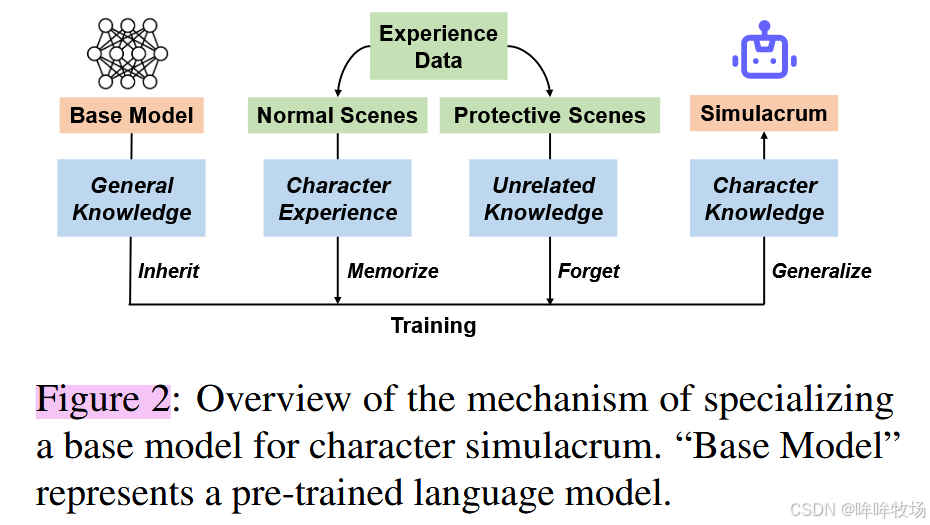
使用上述步骤所构建的角色档案、保护性经历训练模型,使模型能够更好的扮演角色,并在面对这些位置的问题时,表现出无知与困惑;经过验证,即使经过小样本训练的模型,也可以很好地泛化到新的问题。
Conclusion、Future、Limitations
C_1,该方法效果极佳;C_2,保护性经历能够帮助模型避免“角色幻觉”。
F_1,实现更强大的代理;F_2,拓展应用场景,如教育、娱乐、社交互动等;F_3,挖掘进一步提升稳定性的方法和技术。
L_1,缺乏标准的评估指标来评价角色模拟体;L_2,当前数据仅基于角色档案,不足以全面代表一个人,可以引入多种研究数据如传记、访谈记录等;L_3,生成的文本可能会带有冒犯性,需要在构建生动的角色模拟体和避免生成负面思想之间找到平衡。


















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











