







Graph加粗样式# 写在前面
这是一篇关于LLM和KG的论文, 主要创新点是把LLM也视作为一种KG, 从而让LLM和KG协同工作, 使用LLM补全KG中缺失的知识/事实.
该论文发表在 EMNLP 2024 上, 以下是相关链接:
背景
随着大语言模型(LLM)在自然语言处理任务中的广泛应用,其知识推理和生成能力引起了广泛关注。然而,LLM在面对知识不足和幻觉问题时表现仍然有限。为解决这些问题,许多研究尝试将LLM与知识图谱(KG)结合, 例如Graph RAG, Reasonign on graph 等
知识图谱以三元组的形式存储结构化知识,为LLM提供外部知识来源。然而,在现实场景中,知识图谱往往是不完整的(Incomplete Knowledge Graph, IKG),无法完全涵盖回答问题所需的所有信息。论文针对这一问题,提出了"Generate-on-Graph"(GoG)方法,以评估和提升LLM在不完整知识图谱场景下的问答能力。
Related Work
在不完整知识图谱问答(IKGQA)领域,前人的研究方法主要分为以下几类:
1. 语义解析方法(Semantic Parsing Methods)
- 动机:将自然语言问题转换为结构化查询(如SPARQL),直接在知识图谱上执行查询以获取答案。
- 代表性工作:
- KB-BINDER:通过生成初步逻辑形式并绑定实体和关系,以执行查询。
- ChatKBQA :提出一种"生成-检索"框架,通过LLM生成逻辑查询,并利用知识图谱检索补全信息。
- 缺陷: 该方法由于是将问题转化为结构化的逻辑查询, 灵活性较差. 并且, 由于自然语言出来语义歧义, 以及上下文关系问题, 直接使用逻辑查询可能会生成与原问题相反的答案
2. 检索增强方法(Retrieval Augmented Methods)
- 动机:通过检索知识图谱中的相关路径,为LLM推理提供上下文信息。
- 代表性工作:
- StructGPT:利用LLM生成路径,然后根据这些路径从知识图谱中提取信息。
- ToG:通过LLM逐步探索关系路径并推理答案。
- 缺陷: 该方法只是利用了知识图谱中的知识, 没有充分让LLM和KG协同工作, 同时利用LLM和KG中的知识. 此外, 基于KG Retrieval的方法在生成结果上高度依赖检索的结果, 如果检索出来的信息有冗余甚至是错误, 那么将会误导LLM生成错误的结果.
3. 知识图谱嵌入方法(Knowledge Graph Embedding Methods)
- 动机:通过知识图谱嵌入预测可能的关系和答案。
- 代表性工作:
- A knowledge inference model for question answering on an incomplete knowledge graph:提出了一种训练知识图谱嵌入的方法,在IKG环境下预测答案。
- Improving question answering over incomplete knowledge graphs with relation prediction:利用关系预测改进不完整知识图谱问答的准确性。
- 缺陷: 需要训练嵌入模型, 并且性能高度依赖于嵌入模型的性能
Proposed Method
由于现有的方法都无法解决在IKG下的QA问题, 因此论文提出了"Thinking-Searching-Generating"框架,用于处理不完整知识图谱问答任务。
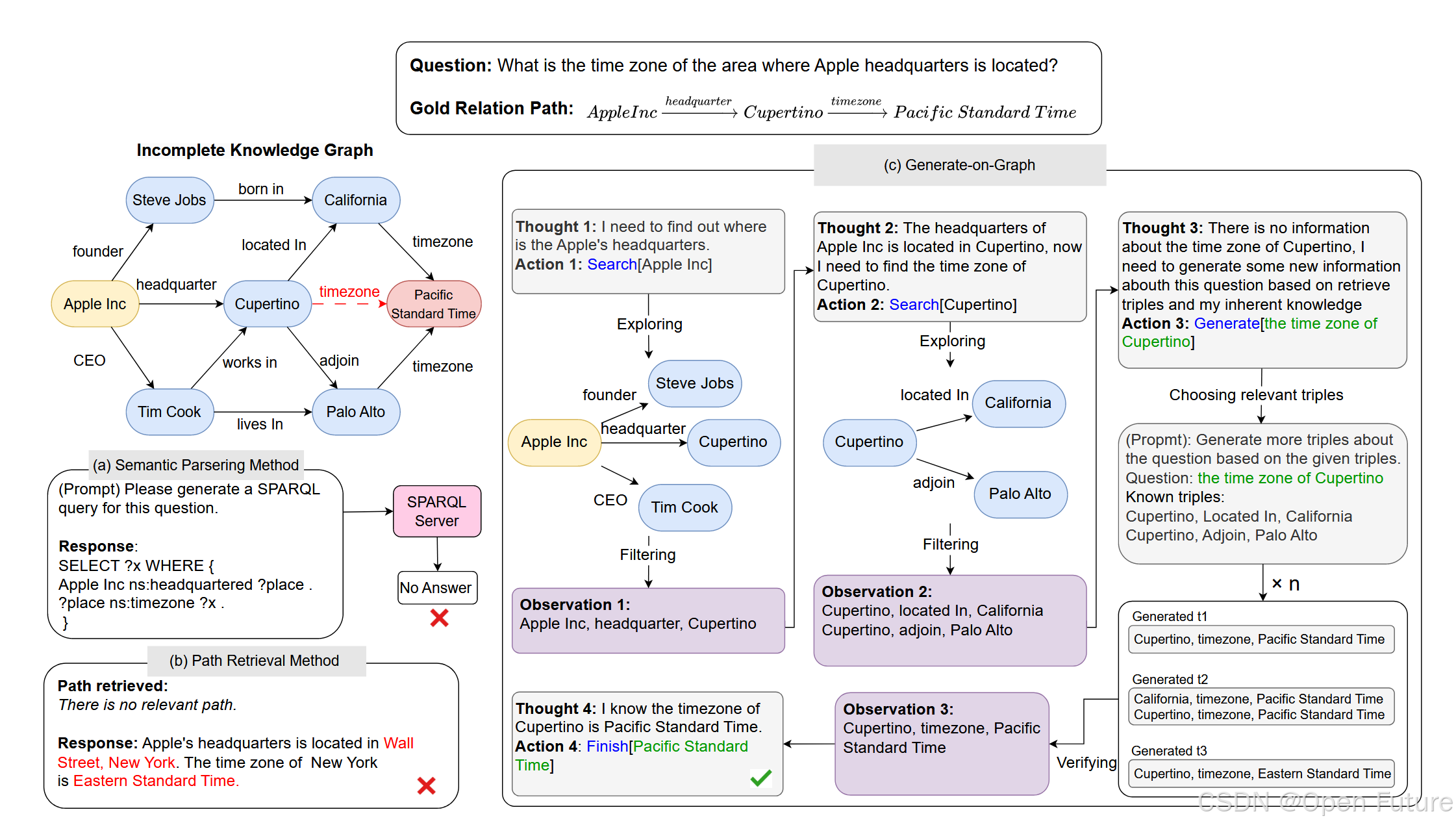
该框架主要是分为三个部分: Thinking-Searching-Generating. 其中Thinking是主要的引导点, 决定下一步的计划(可能是Searching, Generating, Answering), 而Searching是在知识图谱中查询和收集信息, Generating 是利用LLM生成三元组, 补全KG知识
1. Thinking(思考)
动机: 一般的问题都不是一次查询/思考就能解决的, 很多基于KG的问题数据集都包含了多跳问题的问答, 需要LLM进行多步思考, 检索和回答, 因此需要LLM分解问题, 具体做法是使用LLM把原问题分解为多个子问题, 然后在关于子问题进行"思考"。"思考"阶段旨在生成下一步操作的逻辑决策, 具体来说, 假设当前问题 q q q,系统状态为 S t S_t St,则思考的输出 T t T_t Tt表示为:
T t = Thinking ( q , S t ) T_t=\text{Thinking}(q, S_t) Tt=Thinking(q,St)
其中 T t T_{t} Tt 是下一步的指令, 可能结果为:
- 继续搜索知识图谱中的信息, 搜索某个实体的邻居关系.
- 生成新的知识以补全知识图谱, 利用LLM生成知识(三元组), 补全KG缺失的知识.
- 根据足够的信息可以直接回答问题, 完成问题回答。
例如, 问题是 “苹果公司总部所在区域的时区是什么” , LLM可能的思考结果为:
- 我需要找到苹果公司总部的位置(Cupertino)
- 找到 Cupertino 后,我需要进一步查找 Cupertino 的时区信息
2. Searching(搜索)
动机: 为后续推理和生成提供支持, LLM需要在知识图谱中寻找直接邻居实体及其关系, 搜索某个实体的邻居关系,扩展当前上下文信息. 具体来说, 设当前目标实体为 e t e_t e
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









