






今天分享的是AIGC专题系列深度研究报告:《AIGC专题:多模态大模型与应用快速迭代》。
(报告出品方:国信证券)
报告共计:51页
来源:人工智能学派
海外Chatbot访问量稳中有升,国内Chatbot访问量增长迅猛
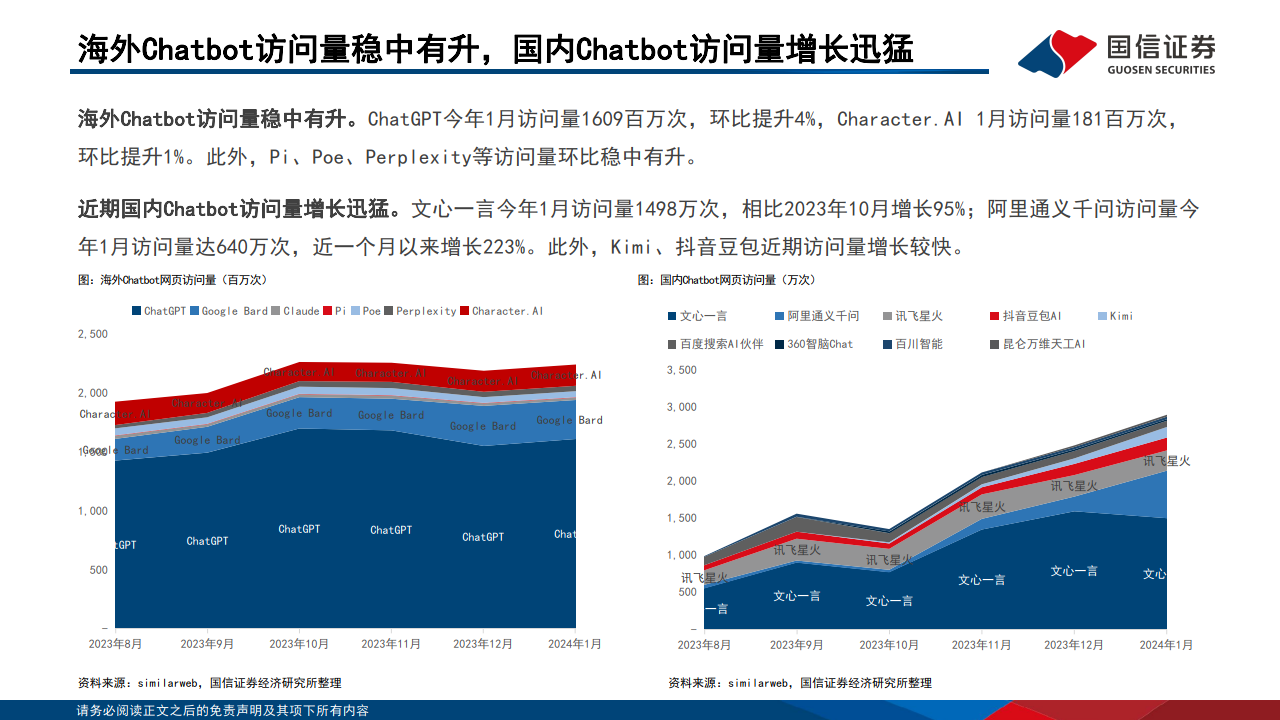
海外Chatbot访问量稳中有升。ChatGPT今年1月访问量1609百万次,环比提升4%,Character.AI 1月访问量181百万次, 环比提升1%。此外,Pi、Poe、Perplexity等访问量环比稳中有升。 近期国内Chatbot访问量增长迅猛。文心一言今年1月访问量1498万次,相比2023年10月增长95%;阿里通义千问访问量今 年1月访问量达640万次,近一个月以来增长223%。此外,Kimi、抖音豆包近期访问量增长较快

海内外AI进展迅速,带动国内人工智能板块反弹
近期海内外科技进展迅速,带动国内人工智能反弹。Wind人工智能指数年初至今涨幅12.1%,主要由于春节期间OpenAI发 布Sora、谷歌发布Gemini1.5,大模型特别是文生视频进展超出预期;同时伴随股价上涨、交易量也大幅回升。

海外:OpenAI发布Sora、谷歌发布Gemini1.5
OpenAI发布文生视频模型Sora,可以根据文本生成复杂场景下1分钟的视频 2月15日,OpenAI发布Sora模型,可以根据用户输入的文本描述,生成一段视频内容,视频时长可达1分钟且视觉质量较高。对于任何需要 制作视频的艺术家、电影制片人或学生来说,这都带来了无限可能。Sora 可以创建包含多人、特定运动类型和详细背景的复杂场景。它能 生成准确反映用户提示的视频。例如,Sora 可以制作时尚女性走在霓虹闪烁的东京街头的视频、雪地里的巨型长毛象视频,甚至是太空人 冒险的电影预告片。(OpenAI官网)
谷歌Gemini1.5上线,大模型“视野”被史诗级地拓宽 2月15日,谷歌DeepMind首席科学家Jeff Dean,以及联创兼CEO的Demis Hassabis激动地宣布了最新一代多模态大模型——Gemini 1.5系列 的诞生。其中,最高可支持10,000K token超长上下文的Gemini 1.5 Pro,也是谷歌最强的MoE大模型。1.5 Pro能够一次性处理海量信息— —比如1小时的视频、11小时的音频、超过30,000行的代码库,或是超过700,000个单词。这意味着大模型的“视野”被史诗级地拓宽,新 大模型可以深入理解海量信息、横跨不同的媒介、高效处理更长的代码、分析和掌握复杂的代码库、长篇复杂文档的推理。(新智元)
海外:Meta AI 视频模型密集更新
Meta GenAI 团队推出 FlowVid,支持快速合成、修改视频并保持一致性 来自得克萨斯大学奥斯汀分校的 Meta GenAI 团队成员,提出了一个能够保持一致性的V2V(视频到视频)合成框架——FlowVid。仅需 1.5分钟,就能生成一段4秒,每秒30帧、分辨率为512x512的视频。同时,FlowVid 能够无缝与现有 I2I 模型配合,支持多种修改方式, 包括风格化、物体替换和局部编辑。(新智元)
Meta GenAI 团队推出 Fairy,可轻松替换视频人物、改变风格 1月8日报道,Meta 的 GenAI 团队推出了视频到视频综合模型“Fairy”,该模型比现有模型更快,时间上更一致。研究团队展示了 Fairy 在几个应用中的表现,包括角色/物体替换,风格化和长形式视频生成。Fairy 使用交叉帧关注机制,确保时间上的一致性和高保 真度合成。该模型可以在仅 14 秒内生成大小为 512 x384 像素、120 帧(30 fps 下的 4 秒)的视频,比以前的模型至少快44 倍。但 该模型目前在处理如雨、火灾或闪电等动态环境效果方面存在问题,这些效果要么无法很好地融入整个场景,要么会产生视觉错误。(站 长之家)
海外:AI 视频合成技术取得新突破
谷歌发布视频生成模型 Lumiere,运动幅度和一致性表现良好 1 月 24 日报道,谷歌发布视频生成模型 Lumiere,专门用于将文本转换为视频。Lumiere 通过在空间和关键的时间维度进行上下采样, 并利用预先训练好的文本到图像扩散模型,使得该模型能够直接生成全帧率、低分辨率的视频,并且在多个空间 - 时间尺度上进行处理。 据介绍,该模型演示视频质量非常高,运动幅度和一致性表现也很好。(站长之家)
Adobe 发布 AI 视频模型 ActAnywhere Adobe 发布 AI 视频模型 ActAnywhere,可根据动作生成背景:1 月 22 日报道,HuggingFace 页面显示,Adobe 发布全新视频模型 ActAnywhere,它可以根据前景主体的运动和外观,为电影和视觉特效社区生成视频背景。ActAnywhere 模型通过引入跨帧注意力进行时 间推理,将用户的创意想法快速地融入到动态的虚拟场景中。模型的训练数据集包含 240 万个包含人类与场景交互的视频,并通过自监 督的方式进行训练。评估结果表明,ActAnywhere 能够生成具有高度真实感的前景与背景互动、相机运动、光影效果的视频,并能够推广 到分布于训练数据之外的样本,包括非人类主体。(品玩)













报告共计:51页
来源:人工智能学派















 2075
2075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









