






Q1:为什么每个网格有固定的B个bounding box?(即B=2)
在训练的时候会在线地计算每个predictor预测的bounding box和ground truth的IOU,计算出来的IOU大的那个predictor,就会负责预测这个物体,另外一个则不预测。这么做有什么好处?我的理解是,这样做的话,实际上有两个predictor来一起进行预测,然后网络会在线选择预测得好的那个predictor(也就是IOU大)来进行预测。
Q2:每个网格预测的两个bounding box是怎么得到的?
YOLO中两个bounding box是人为选定的(2个不同 长宽比)的box,在训练开始时作为超参数输入bounding box的信息,随着训练次数增加,loss降低,bounding box越来越准确。Faster RCNN也是人为选定的(9个 不同长宽比和scale),YOLOv2是统计分析ground true box的特点得到的(5个)。
在刚开始训练的时候他肯定不会怎么智能马上预测出我们想要的bbox,肯定是经过多次训练,使预测bbox越来越理想。训练时,输出的数据里面有bbox的x,y,w,h,然后将预测出来的x,y,w,h和真实值比较,通过反向传播修改前面神经网路的参数,经过多次迭代,就能得到理想的bbox。
在测试时训练好的神经网络看到当前网格(grid cell)的一些信息,就能推测出应该用怎么的bbox。比如神经网络看见这只图像中狗的眼睛比较小,他给出的bbox的尺度就会小一点,然后依据嘴巴,脚,尾巴等信息,可以推测出bbox的中心。
________________________________________________________________________



_______________________________________________________________
在训练的时候,每个样本的ground truth的box是知道的,对应于相当于下采样后的的feature map,也能找到在feature map中对应的格子的位置。如果一个grid cell是该物体的中心位置,则这个grid cell负责预测这个物体;每个grid cell都预测了若干个box,其中会有一个box具有与ground truth的某个box有最大的iou,则由这个box负责调整box的位置(另外的预测的box就忽略了)。
可以想象,一开始的时候,权重是随机的,面对抽象出来的图像的feature信息,其预测的box的信息、confidence的信息、物体类别的条件概率都是随机的,经过了loss函数进行惩罚与优化,使得预测行为越来越好。取极端情况为例子加深理解:总是用同一张图片做训练,每次得到的图像的feature map都是一样的。一开始的时候,权重随机,权重与某个grid cell的运算的结果是随机,即每个grid cell对应的5*b+C的数据是随机的。网络对此情况进行优化,指导权重向某个方向优化。第二次看到还是一样的feature map,新的权重与某个grid cell对应的数据进行计算,就会得到更好的box位置和confidence,物体类别的信息。如此反复进行,直到权重参数调整到这样的情况,面对同样的grid cell,其计算出来的box的信息完全与ground box的位置符合,confidence=1,正确类别的条件概率为1。
______________________________________________________________
但YOLO每个格子(grid cell)的2个bounding box事先并不知道会在什么位置,只有经过前向计算,网络会输出2个bounding box,这两个bounding box与样本中对象实际的bounding box计算IOU。这时才能确定,IOU值大的那个bounding box,作为负责预测该对象的bounding box。

候选框bounding box怎么生成?
上面提到7x7的每个网格都要预测两个bounding box的坐标和置信度,如下图,以红色网格为例,生成两个大小形状不同的蓝色box,box的位置坐标为(x,y,w,h),其中x和y表示box中心点与该格子边界的相对值,也就是说x和y的大小被限制在[0,1]之间,假如候选框的中心刚好与网格的中心重合,那么x=0.5,y=0.5。 w和h表示预测box的宽度和高度相对于整幅图片的宽度和高度的比例,比如图中的框住狗的蓝色网格的宽度w大致为1/3,高度h大致为1/2。这样(x,y,w,h)就都被限制在[0,1]之间,与训练数据集上标定的物体的真实坐标(Gx,Gy,Gw,Gh)进行对比训练,每个网格负责预测中心点落在该格子的物体的概率。

YOLO-V1候选框生成
每个box预测的置信度只是为了表达box内有无物体的概率(类似于Faster R-CNN中RPN层的softmax预测anchor是前景还是背景的概率),并不预测box内物体属于哪一类。那么这个置信度有什么用呢?
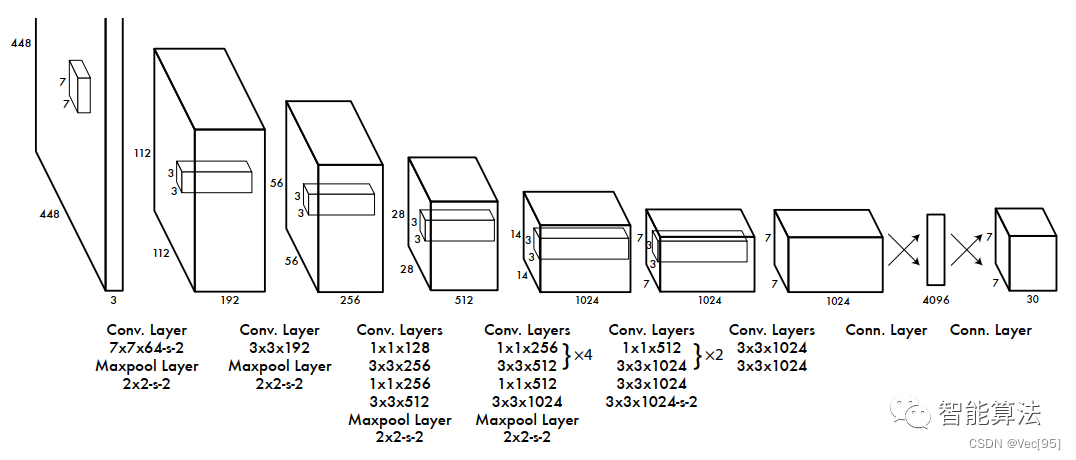
从上图中可以看到,YOLO-V1网络的主要步骤如下:
- 输入图片是
448x448x3,经过一个7x7x64,stride为2的卷积层和一个2x2,stride为2的最大化池化层后得到112x112x192尺寸的特征图。 - 经过一个
3x3x192的卷积层和一个2x2,stride为2的最大化池化层后得到56x56x256尺寸的特征图。这里留一个讨论题,这两步的尺寸变化有没有问题?欢迎大家评论区讨论。 - 经过一个
1x1x128,3x3x256,1x1x256,3x3x512的卷积层和2x2,stride为2的最大化池化层后得到28x28x512的特征图。 - 经过四组
1x1x256,3x3x512的卷积层后再经过1x1x512,3x3x1024的卷积层和一个2x2-s-2的池化层后得到14x14x1024的特征图。 - 经过两组
1x1x512,3x3x1024的卷积层后再经过一个3x3x1024和stride为2的3x3x1024的卷积层后得到7x7x1024的特征图。 - 经过两个
3x3x1024的卷积层后得到7x7x1024的特征图。 - 经过节点为
4096的全连接层后最终得到7x7x30(其实是一个一维向量的三维化)的检测结果。
整个算法的大致流程就是这样,接下来我们看下为什么最终会得到7x7x30的结果?
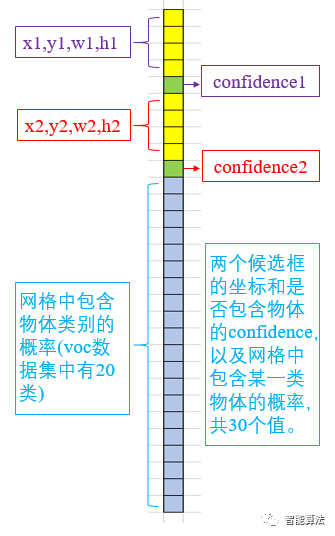
为什么是7x7x30的输出?
YOLO-V1将一副448x448的原图分割成了7x7=49个网格,每个网格要预测两个bounding box的坐标(x,y,w,h)和box内是否包含物体的置信度confidence(每个bounding box有一个confidence),以及该网格包含的物体属于20类别中每一类的概率(YOLO的训练数据为voc2012,它是一个20分类的数据集)。所以一个网格对应一个(4x2+2+20)=30维度的向量。如下图:















 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









