







一、背景意义
生菜作为一种广泛种植的绿叶蔬菜,因其营养丰富和生长周期短而受到广大消费者的青睐。在农业生产中,准确判断生菜的成熟度对于提高收成质量和减少资源浪费至关重要。通过准确识别生菜的成熟度,农民可以及时收获,从而提高产量和品质,减少损失。结合深度学习技术,建立成熟度自动识别系统,能够实现农业生产的智能化,降低人力成本,提高管理效率。生菜成熟度数据集不仅具有重要的学术价值,还有助于推动农业生产的智能化和可持续化发展,为农民和研究人员提供了可靠的支持。
二、数据集
2.1数据采集
首先,需要大量的生菜生长图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示生菜生长特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
构建生菜成熟度检测分类数据集是一项繁重而复杂的任务,涉及多个生菜成熟度分类的标注,包括 Ready(成熟)、empty_pod(空壳)、germination(发芽)、pod(豆荚) 和 young(幼苗)。这些生菜状态之间可能存在微小差别,增加了标注工作的复杂度和工作量。标注人员需要投入大量时间和精力,精确标注每个生菜的成熟度状态和类别,以捕捉生菜状态的特征和准确位置。通过使用 LabelImg 逐一标注图像,确保每个生菜状态都被准确标注,以保证数据集的准确性和完整性,为生菜成熟度检测算法的训练和改进奠定基础。

包含1518张生菜图片,数据集中包含以下几种类别
- 成熟的生菜,适合采摘和食用。
- 空荚,表示生菜已经过熟或未发育完全。
- 发芽,用于识别萌发的生菜种子。
- 豆荚:可能指生菜的果荚或果实,代表生菜的生长阶段。
- 即将成熟的生菜,还未完全成熟,通常具有特定的外观和特征。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 图像整理:将标注后的图像整理到相应的文件夹中,以便于后续使用和模型训练。
- 图像增强:应用数据增强技术(如旋转、缩放、翻转)以增加样本量,提高模型的泛化能力。
- 图像格式转换:确保所有图像处于统一的格式和尺寸,以便于模型训练。
- 数据划分:将数据集划分为训练集、验证集和测试集。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
在深度学习中,卷积神经网络(CNN)是最适合生菜成熟度检测的算法。CNN在处理图像数据方面表现出色,能够自动提取和学习图像中的特征,非常适合用于分类和检测任务。卷积神经网络通常由以下几个主要层组成:
-
卷积层:这是CNN的核心部分,使用多个卷积滤波器对输入图像进行卷积操作。每个滤波器能够学习到不同的特征,如边缘、角点、纹理等。通过多层卷积,网络可以提取出越来越复杂的特征。
-
激活层:通常使用ReLU(修正线性单元)作为激活函数,引入非线性因素,帮助网络更好地拟合复杂的函数。
-
池化层:池化层通常跟随卷积层,用于下采样特征图,减少特征的维度和计算量,同时保持重要特征。常用的池化方法是最大池化和平均池化。
-
全连接层:在网络的最后部分,通常会有一个或多个全连接层,将提取到的特征映射到具体的类别上,输出每个类别的概率。
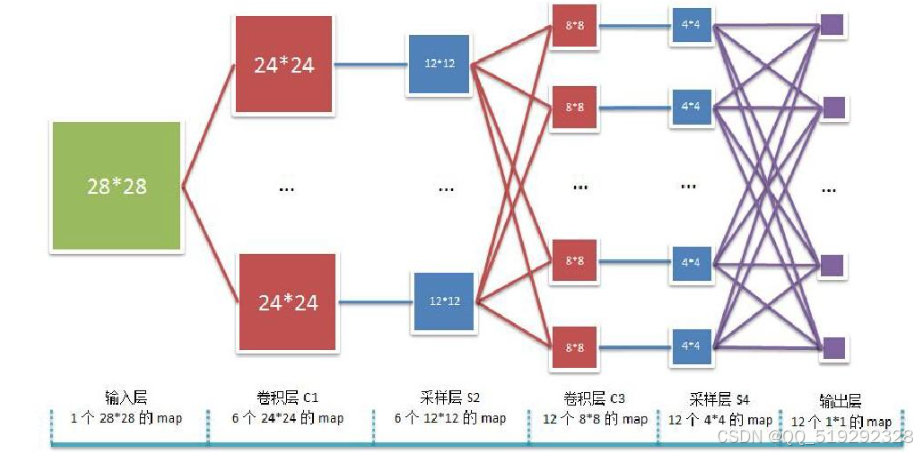
卷积神经网络的工作过程如下:一是特征提取,卷积层用卷积核在输入数据上滑动获取不同层次特征,初始卷积层捕捉边缘、纹理等低级特征,后续卷积层在此基础上组合出物体形状、部分结构等高级特征;二是数据降维与抽象化,池化层对特征图降维,在减少数据量时保留重要特征,经多次卷积和池化,原始像素信息转化为利于分类和识别的高度抽象特征;三是分类或回归任务执行,全连接层利用前面提取和抽象后的特征,依据预定义任务计算并输出结果,训练中通过反向传播算法调整网络权重,使输出结果与真实值误差最小化。
3.2模型训练
在完成生菜成熟度数据集的划分和准备后,开发一个基于 YOLO模型的项目还需要进行以下步骤:模型配置、训练模型、评估模型和部署模型。
配置 YOLO 模型的参数,包括网络结构、类别数量和路径设置。通常使用 YOLOv5。
# yolov5/data/custom.yaml
train: ../path/to/yolo/images/train # 训练集路径
val: ../path/to/yolo/images/val # 验证集路径
nc: 5 # 类别数量
names: ['Ready', 'empty_pod', 'germination', 'pod', 'young'] # 类别名称
使用准备好的数据集和配置文件来训练 YOLO 模型。这一步通常在命令行中执行,指定数据集和配置文件等参数。
# 在终端中运行以下命令
!python train.py --img 640 --batch 16 --epochs 100 --data custom.yaml --weights yolov5s.pt --save-period 5
在这段代码中:
--img 640指定输入图像的大小。--batch 16设置每批次的图像数量。--epochs 100指定训练的轮数。--data custom.yaml指定数据集配置文件。--weights yolov5s.pt指定预训练模型的权重文件。--save-period 5每5个epoch保存一次模型。
在训练完成后,需要使用测试集对模型进行评估,以查看模型的性能指标,例如准确率和损失等。
import torch
# 加载训练好的模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt', force_reload=True)
# 进行评估
results = model.val()
# 输出评估结果
print("模型评估结果:")
print(f"损失: {results.loss}, mAP@0.5: {results.maps[0]}")
将训练好的模型部署到实际应用中,可以使用 Flask、FastAPI 或其他框架创建一个简单的 API。
from flask import Flask, request, jsonify
import torch
from PIL import Image
import io
app = Flask(__name__)
# 加载训练好的模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt')
@app.route('/predict', methods=['POST'])
def predict():
# 获取上传的图片
file = request.files['file']
img = Image.open(io.BytesIO(file.read()))
# 进行预测
results = model(img)
# 获取预测结果
predictions = results.pred[0].numpy().tolist()
# 提取预测信息
response = []
for pred in predictions:
response.append({
'class': int(pred[5]), # 类别索引
'confidence': float(pred[4]), # 置信度
'bbox': pred[:4].tolist() # 边界框坐标
})
return jsonify(response)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
在这段代码中:
- Flask框架用于创建一个简单的Web服务。
/predict路由处理 POST 请求,接收上传的图片并进行预测。- 返回的预测结果包括类别索引、置信度和边界框坐标。
目标检测项目的主要流程,包括模型配置、训练、评估和部署。每个步骤都有相应的示例代码,帮助你更好地理解和实施项目。这些步骤将帮助你建立一个高效的深度学习模型,实现生菜成熟度的自动检测与分类。
四、总结
生菜成熟度数据集是一个专为研究生菜不同生长阶段而设计的重要资源,包含五个主要分类:成熟、空荚、发芽、荚果、幼苗。这一数据集的构建旨在为深度学习和计算机视觉研究提供高质量的训练和测试样本,帮助农业生产者更准确地判断生菜的成熟状态。通过对生菜在各个阶段的特征进行详细标注,该数据集为智能农业应用提供了坚实的基础。利用现代深度学习算法,尤其是卷积神经网络(CNN),研究人员可以自动识别和分类不同的生菜成熟度。这不仅提高了农业生产的效率,还能够减少资源浪费,推动可持续发展。

















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









