







一、背景意义
随着全球人口的增长和农业需求的增加,农作物的高效种植和管理变得愈加重要。然而,杂草的生长对农作物的产量和质量造成了显著影响,影响了农业生产的经济效益。传统的杂草管理方法主要依赖人工识别和手动除草,效率低下且容易出现误判,导致资源浪费和环境污染。因此,利用深度学习技术进行农作物与杂草的自动识别和分类,成为提高农业生产效率的迫切需求。农作物杂草数据集包含清晰标注的农作物和杂草图像,以便为深度学习模型的训练和评估提供必要的数据支持。通过深度学习算法,尤其是卷积神经网络(CNN),可以实现对农作物和杂草的高效、准确识别,从而为现代农业管理提供智能化解决方案。
二、数据集
2.1数据采集
首先,需要大量的农作物与杂草图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示农作物与杂草特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
数据标注是为每张图像分配相应的类别标签,以便于后续的模型训练。具体步骤包括:
- 选择标注工具:使用图像标注工具(如LabelImg、VGG Image Annotator等)对收集的图片进行标注。
- 标记类别:对每张图像进行分类,标注为“crop”(农作物)或“weed”(杂草),确保标注准确。
- 边界框标注:如果需要进行目标检测,可以为每个物体添加边界框,记录其在图像中的位置。
- 格式统一:确保所有标注数据保存为统一的格式,如YOLO或Pascal VOC,以便于后续处理和模型训练。
在使用LabelImg标注作物杂草分类数据集时,面临着一定的复杂性和繁重的工作量。该数据集涵盖两个主要类别:作物(crop)和杂草(weed)。标注作物和杂草需要准确识别和标记图像中的不同植物,考虑到不同植物种类、生长阶段和环境条件,这一过程具有挑战性。
对于作物,标注可能需要考虑作物的不同生长阶段、品种和特征,以及受到疾病或虫害影响的情况。而在标注杂草时,需要准确辨识各种杂草种类,包括常见的草本杂草和多年生杂草,这可能需要对植物的形态和特征有深入的了解。

包含1176张农作物杂草图片,数据集中包含以下几种类别
- 作物:种植在田地或农场中用于生产的植物,如小麦、玉米、水稻等。
- 杂草:农田中生长的不受欢迎的植物,会与作物竞争土壤中的养分、水分和阳光资源。通常需要进行除草处理以保护作物的生长。
2.3数据预处理
数据预处理是为模型训练准备数据的关键步骤,主要包括:
- 图像调整:对所有图像进行统一大小调整(如640x640像素),确保输入尺寸一致。
- 数据增强:应用数据增强技术(如旋转、翻转、裁剪、调整亮度等),增加数据的多样性,提升模型的泛化能力。
- 归一化处理:将图像数据归一化,通常将像素值缩放到[0, 1]之间,以加速模型收敛。
- 分割数据集:将数据集划分为训练集、验证集和测试集,常见的比例为70%用于训练,20%用于验证,10%用于测试。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络基本结构包括:
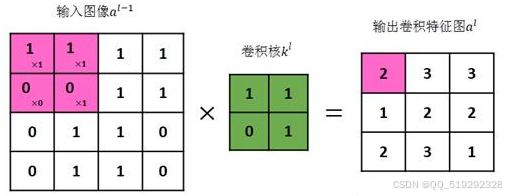
卷积层是CNN的核心部分,其主要功能是通过卷积核(或滤波器)提取输入图像的局部特征。卷积核是一个小的权重矩阵,通过在图像上滑动,与局部区域进行点积运算,从而检测出边缘、线条和纹理等特征。卷积层的输出称为特征图,其大小受步长和填充方式的影响。步长决定了卷积核在图像上滑动的距离,较大的步长会导致输出特征图的维度减小。填充方式分为“same”和“valid”。“same”填充在输入图像的周围添加零,以使输出特征图与输入图像的尺寸相同,而“valid”则不添加任何填充,可能导致输出特征图的尺寸缩小。这种局部连接和共享权重的特性使得CNN能够高效地学习到图像中的重要模式和结构。
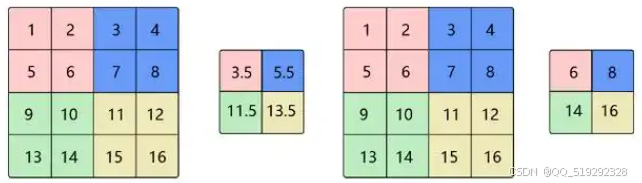
池化层通常紧随卷积层之后,主要用于降维和特征精简。常见的池化方法有最大池化和平均池化。最大池化在池化窗口内选择最大值作为输出,这一过程不仅能有效降维,还能保留图像中的显著特征,减少计算量,从而降低过拟合的风险。平均池化则计算池化窗口内所有值的平均值,考虑了窗口内的所有信息,适用于需要保留更多细节的场景。通过这一层的处理,网络在保持重要特征的同时,减少了数据的复杂性,有助于后续层的高效处理。
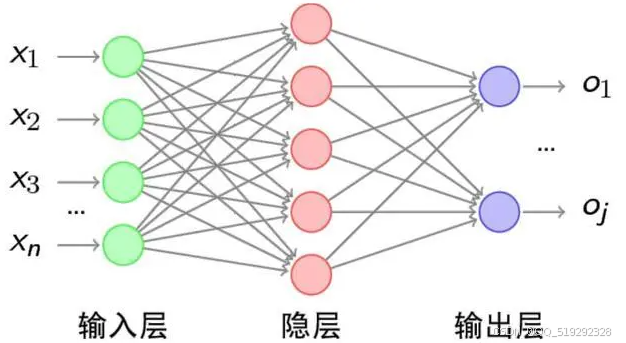
全连接层位于CNN的末端,主要负责将经过卷积层和池化层提取的特征进行整合。该层将特征图展开为一维向量,并通过多个神经元进行连接,从而实现分类或回归任务。每个神经元与前一层的所有输出相连,能够根据提取的特征判断图像的类别或进行其他决策。全连接层通常使用激活函数(如ReLU或Softmax)来引入非线性特性,使得模型能够学习到更复杂的函数映射。通过这一层,CNN能够将抽象的特征转化为具体的类别输出,为图像识别和物体检测等任务提供最终结果。
3.2模型训练
模型配置:
在开始开发YOLO项目之前,首先需要选择并配置合适的YOLO模型版本。对于农作物杂草检测,YOLOv5通常是一个理想的选择,因为它在准确性和速度上都表现良好。配置模型时,需要设定一些超参数,包括输入图像的尺寸、类别数和其他训练参数。假设我们有两个类别:农作物(crop)和杂草(weed),因此类别数应设置为2。在配置过程中,还可以选择使用预训练的权重文件,这样可以加快训练速度并提高模型的初始性能。以下是模型配置的代码示例:
import torch
# 从Ultralytics的GitHub库加载YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 修改模型的类别数
model.nc = 2 # 类别数:crop 和 weed
通过以上代码,模型已加载并准备好进行后续的配置和训练。确保在模型配置时,考虑项目的具体需求和数据集的特性,以便后续训练和评估时能够达到最佳效果。
数据准备:
数据准备是YOLO项目中至关重要的步骤,这一过程确保数据集的结构符合YOLO的要求。首先,需要创建适当的目录结构,通常包括两个主要文件夹:一个用于存放图像(如JPEG或PNG格式),另一个用于存放相应的标注文件(TXT格式)。每个标注文件应与图像文件同名,且包含该图像中目标的类别和边界框坐标。接下来,创建数据集配置文件,通常为一个以 .yaml 为后缀的文件,描述训练集和验证集的路径、类别数及类别名称。以下是一个示例的 .yaml 文件:
训练模型:
模型训练是YOLO项目中的核心部分,通常涉及多个步骤以确保模型的有效学习。首先,通过运行YOLO提供的训练脚本来启动训练过程,并传入相应的参数。训练过程中,模型会根据输入的图像和标注,学习如何识别不同类别的农作物和杂草。可以使用以下命令开始训练:
# 使用YOLOv5进行训练的命令
!python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5s.pt
在训练过程中,可以使用以下代码段进行数据增强,确保模型能够适应各种变化:
from torchvision import transforms
# 定义数据增强过程
data_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.Resize((640, 640)),
transforms.ToTensor(),
])
# 应用数据增强
# 这里假设有一个DataLoader
# for images, labels in dataloader:
# augmented_images = data_transforms(images)
评估模型:
模型训练完成后,必须对其进行评估,以验证模型性能和准确性。评估过程通常使用验证集,计算模型在该数据集上的表现,常用的评价指标是mAP(mean Average Precision)。通过运行YOLO提供的评估脚本,可以快速计算模型的性能指标。以下是评估模型的命令示例:
# 使用YOLOv5进行评估的命令
!python val.py --weights runs/train/exp/weights/best.pt --data data.yaml --img 640
评估结果将显示模型在验证集上的准确率、召回率和mAP等指标。通过这些指标,可以分析模型的效果,判断其在不同类别上的识别能力。如果模型性能不佳,可能需要返回去调整数据集、超参数,或是进行更长时间的训练,以达到更好的效果。可以使用以下代码段提取评估结果:
# 提取评估结果
import json
with open('runs/val/exp/results.json') as f:
results = json.load(f)
print(f"mAP: {results['metrics']['mAP']}")
print(f"Precision: {results['metrics']['precision']}")
print(f"Recall: {results['metrics']['recall']}")
部署模型:
完成训练和评估后,最后一步是将训练好的模型部署到实际应用中。这包括将模型导出为适合不同平台的格式,例如ONNX、TensorRT或TorchScript,以便在边缘设备或云服务器上进行推理。可以使用如下代码导出模型为ONNX格式:
# 导出模型为ONNX格式
torch.onnx.export(model, torch.randn(1, 3, 640, 640), "model.onnx", opset_version=11)
在模型成功导出后,可以进行实时推断,将模型集成到监控系统中,通过摄像头捕捉图像并进行实时分析。以下是使用OpenCV进行实时推断的示例代码:
# 使用OpenCV进行实时推断
import cv2
cap = cv2.VideoCapture(0) # 打开摄像头
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = model(frame) # 进行推断
results.show() # 显示结果
cap.release()
cv2.destroyAllWindows()
通过这种方式,可以实现对农作物和杂草的实时监控和管理,帮助农民在适当的时间进行收割或其他管理措施。以上步骤为YOLO项目的完整流程,确保从模型配置到应用部署的每个环节都能顺利进行。
四、总结
通过支持农业科学研究,该数据集为研究人员提供了分析作物与杂草生长情况的重要数据基础,有助于制定更有效的农业策略和农田管理方案。其次,在植物保护方面,通过训练基于该数据集的模型,可以帮助农民及时发现和处理田间的杂草问题,从而减少杂草对作物的竞争和危害,提高农田产量和质量。最后,该数据集还有助于促进农田管理的现代化和智能化发展,通过对作物和杂草的准确分类识别,支持农田作物种植布局规划,提升农业生产效率和质量,推动农业向可持续发展方向迈进。这些应用展示了该数据集在农业领域中的重要性和潜在影响,为农业生产的改进和可持续发展提供了关键支持。

















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









