









前言
学过ComfyUI的人都知道,ComfyUI是一个入门相对简单,但是深入全面掌握并不简单,其中一个原因是插件太多,节点参数太多,节点和节点之间连接错综复杂,今天我们从最简文生图工作流开始,剥笋式逐步对核心节点以及参数如何使用展开研究。
搭建文生图最简工作流
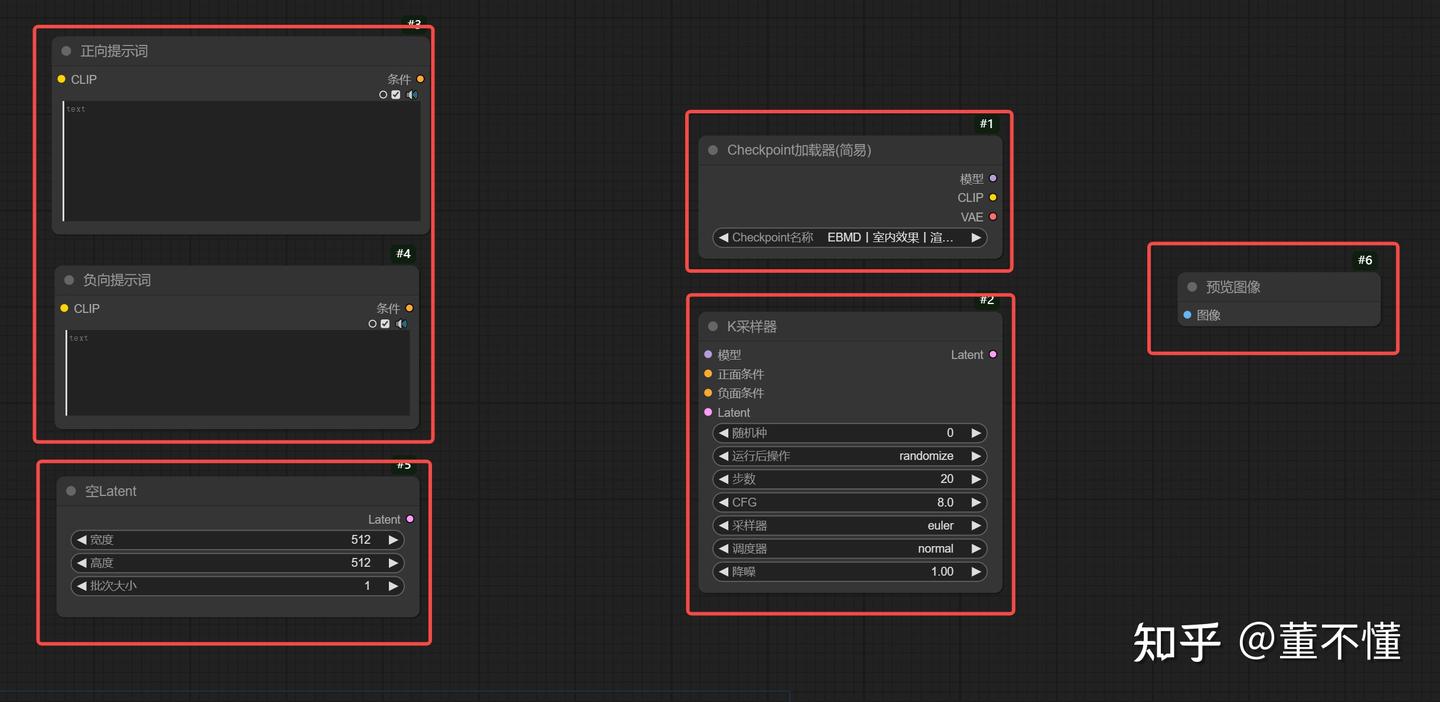
以上就是我们最简工作流的核心节点
- CLIP文本编码器
- 空Latent
- Checkpoint加载器
- K采样器
- 预览图像
我们通过连线,将他们连接起来,构成我们的最简工作流,我们在正向提示词输入我们描绘的图像,并输入负面提示词,然后执行队列
正面提示词:1 girl and two cute cats
负面提示词:nsfw, (low quality, normal quality, worst quality, jpeg artifacts), cropped, monochrome, lowres, low saturation, bad anatomy, deformed, disfigured, poorly drawn face, extra limb, missing limb, floating limbs, disconnected limbs, out of focus, long neck, long body, extra fingers, fewer fingers, (multi nipples), bad hands, signature, username, bad feet, blurry, bad body, skin spots, acnes, skin blemishes, age spot, mutated hands, mutated fingers, ugly, poorly drawn hands, bad proportions, (bad透视:1.2), (bad lighting:1.2), (bad shadow:1.2), (overexposed:1.2), (underexposed:1.2), (color cast:1.2), (banding:1.2), (noise:1.2), (artifacts:1.2), (blurry:1.2), (ghosting:1.2), (macro blocking:1.2), (ringing:1.2), (aliasing:1.2), (moire:1.2)
checkpoint:儿童绘本MIX_V1.safetensors
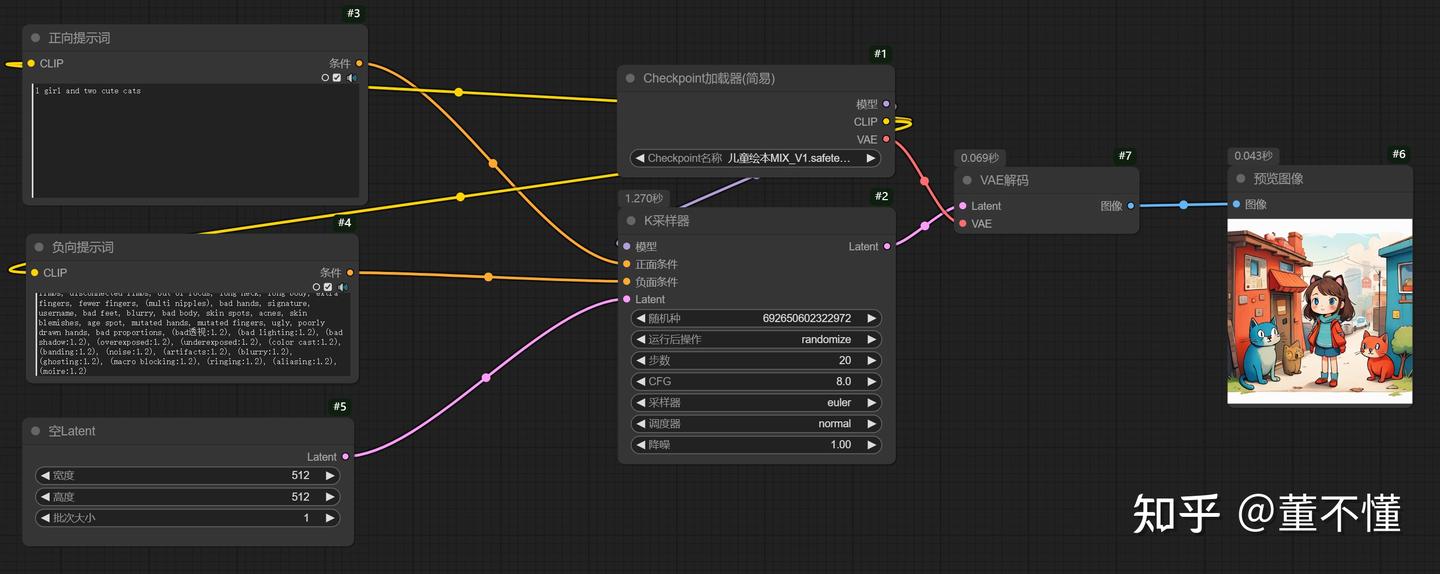
接下来我们看看这些线是如何连接的
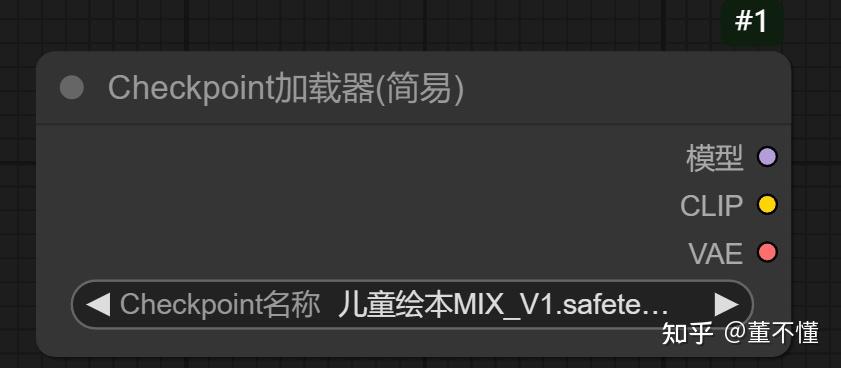
首先出场的就是这个Checkpoint加载器(简易),它就是我们常说的大模型,一般大模型内嵌CLIP和VAE。
有3个输出:
模型:控制图像画风,一般和K采样器连接,在K采样器里控制图像的风格特征。
CLIP:用于提供文本编码,一般和CLIP文本编码器连接,这里有2个CLIP文本编码器,一个用于控制正向提示词(即我要什么),一个用于控制反向提示词(即我不要什么)。
VAE:用于提供像素空间和潜空间转换,和VAE编码器和VAE解码器相连,VAE编码器用于将像素空间转换到潜空间,VAE解码器用于将潜空间转换到像素空间。
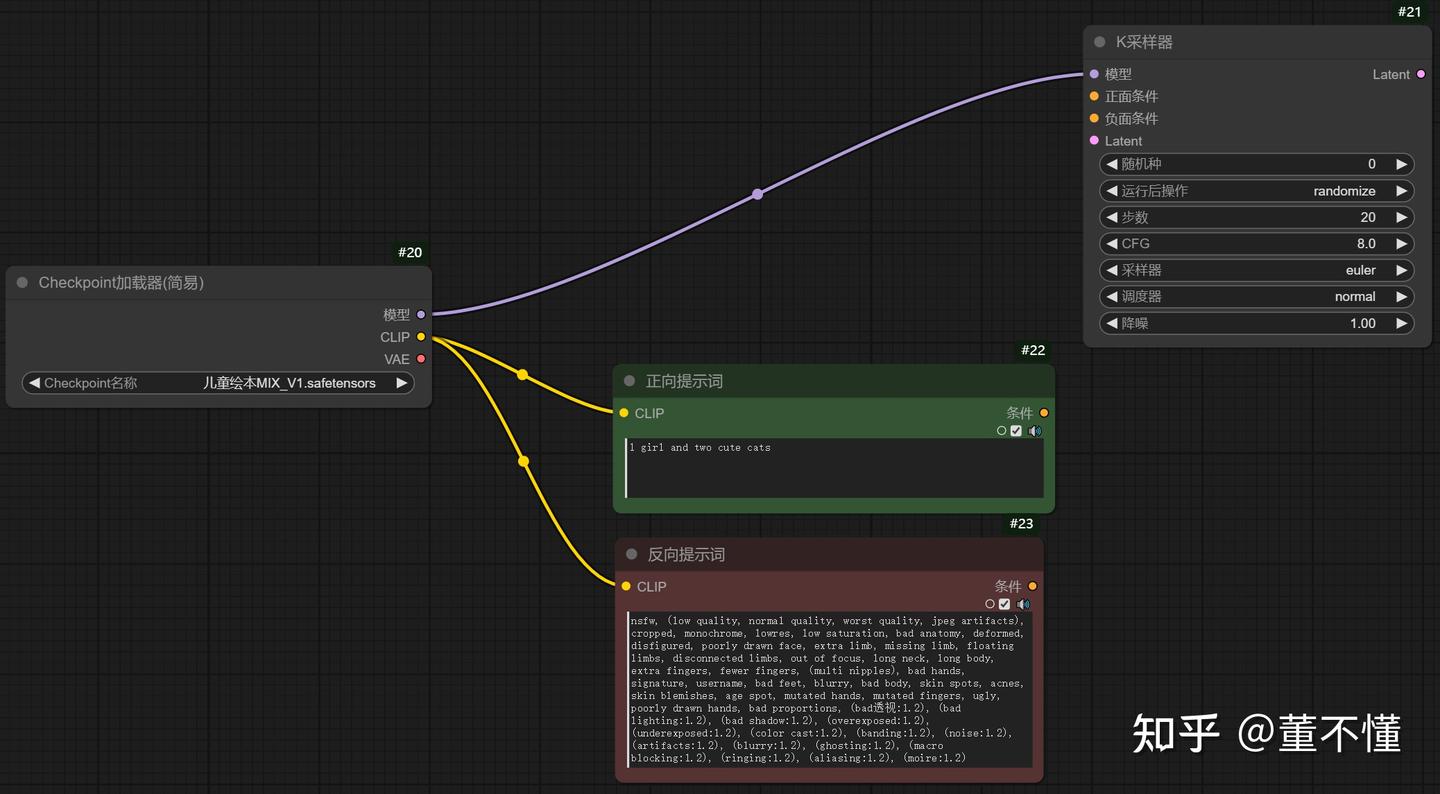
你会发现CLIP编码器有一个输出:条件,这个条件需要作用于K采样器,分别和正面条件和负面条件相连。此外,K采样器的输入Latent和输出Latent,输入Latent可以理解为控制图像画布的尺寸,输出Latent是在K采样器里处理好的图像潜在空间,我们需要用VAE解码器将Latent转为像素,进而得到我们绘制的图像。
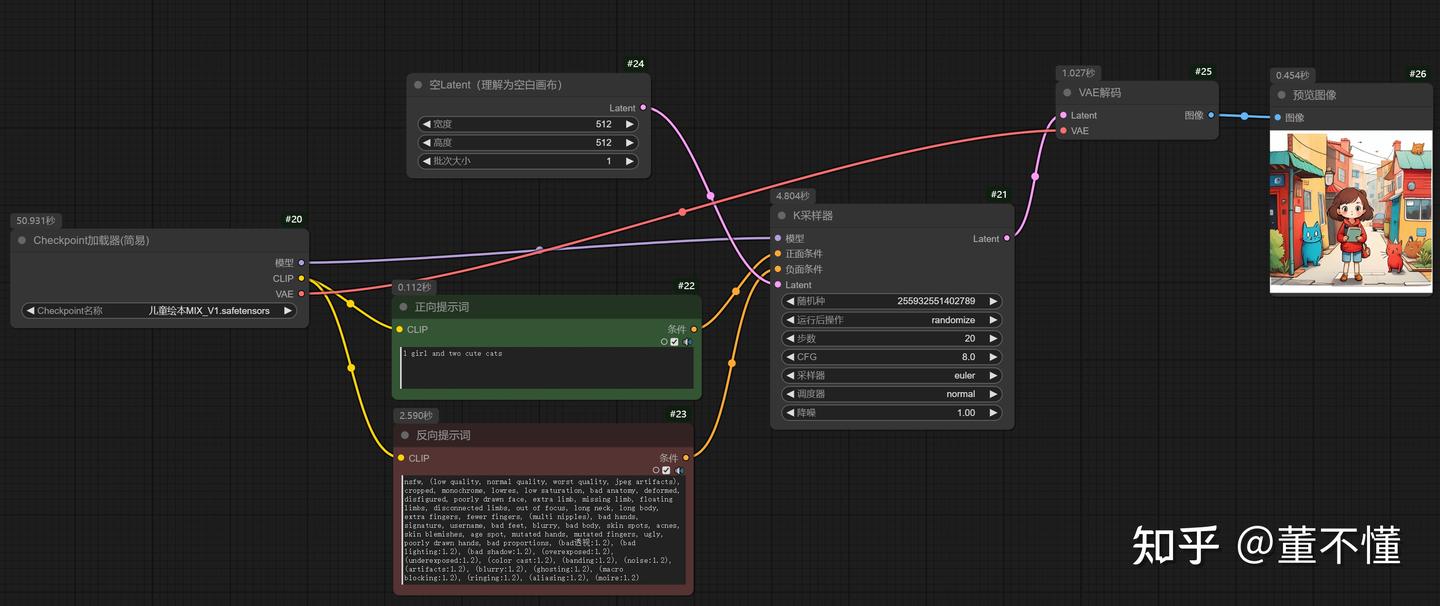
以上就是我们最近工作流的搭建,麻雀虽小五脏俱全,涵盖了AI绘画的基本的核心的工作原理,以后你会见到复杂的多变的工作流,其核心思想都离不开这个最简工作流,它们都是从这个最简工作流扩展出来的,只有在掌握了核心原理之后,你才能知道如何拓展工作流,所以掌握最简工作流的工作原理是很有必要的。
你可以把K采样器看做整个工作流的核心,即你可以首先调出K采样器,然后完善K采样器的输入和输出以及参数部分,不同的参数会影响出图质量和出图样式。
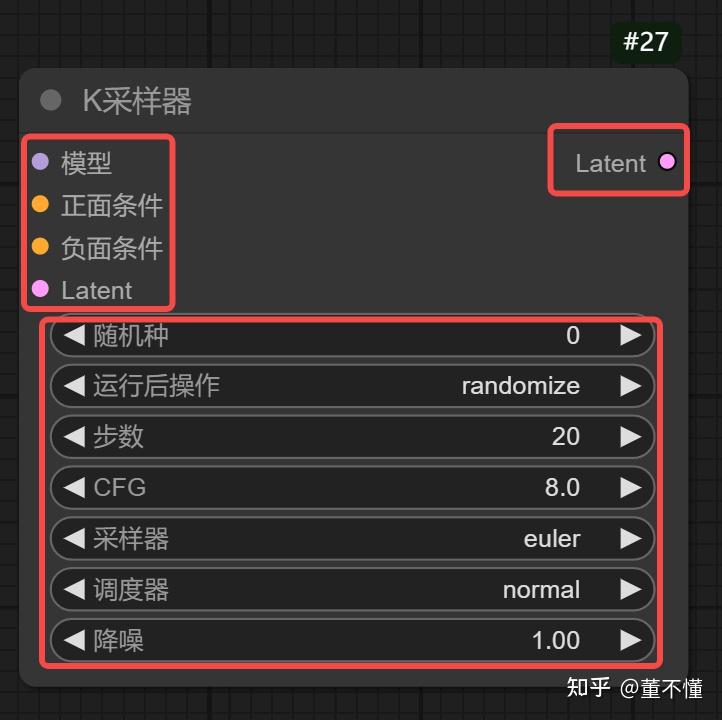
核心节点K采样器
参数:步数
下图可以简单说明一次采样的过程:K采样器使用噪声预测期对每一步的噪声进行预测,用当前图像噪声减去预测噪声,生成一张新图。
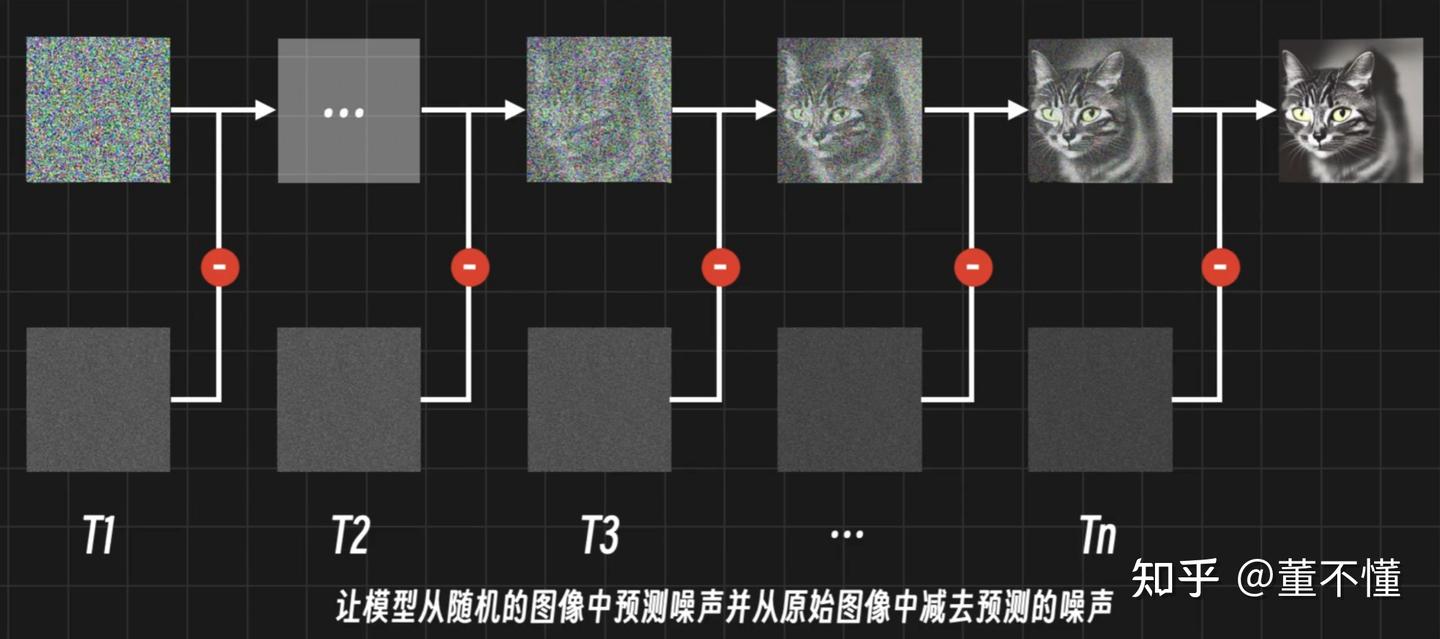
从这张图我们可以看出,采样分步骤完成,每一步都是去除噪声的过程。
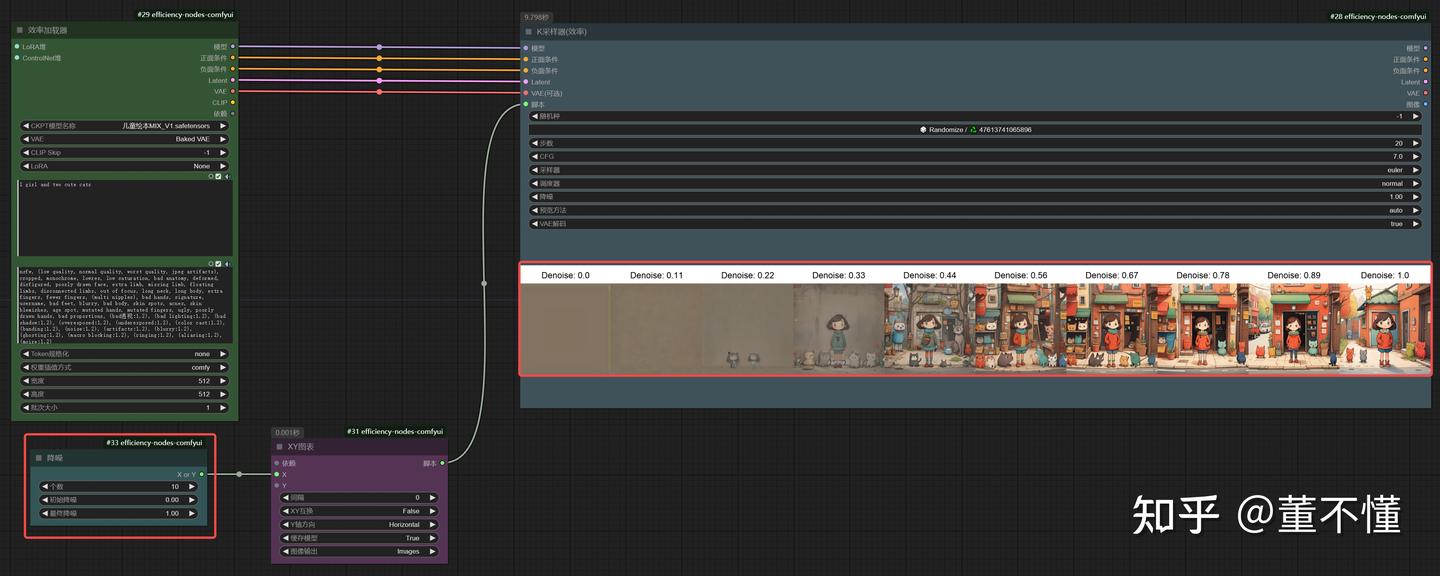
我们使用**效率节点(常用来测试参数效果)**来还原一下整个的采样过程:
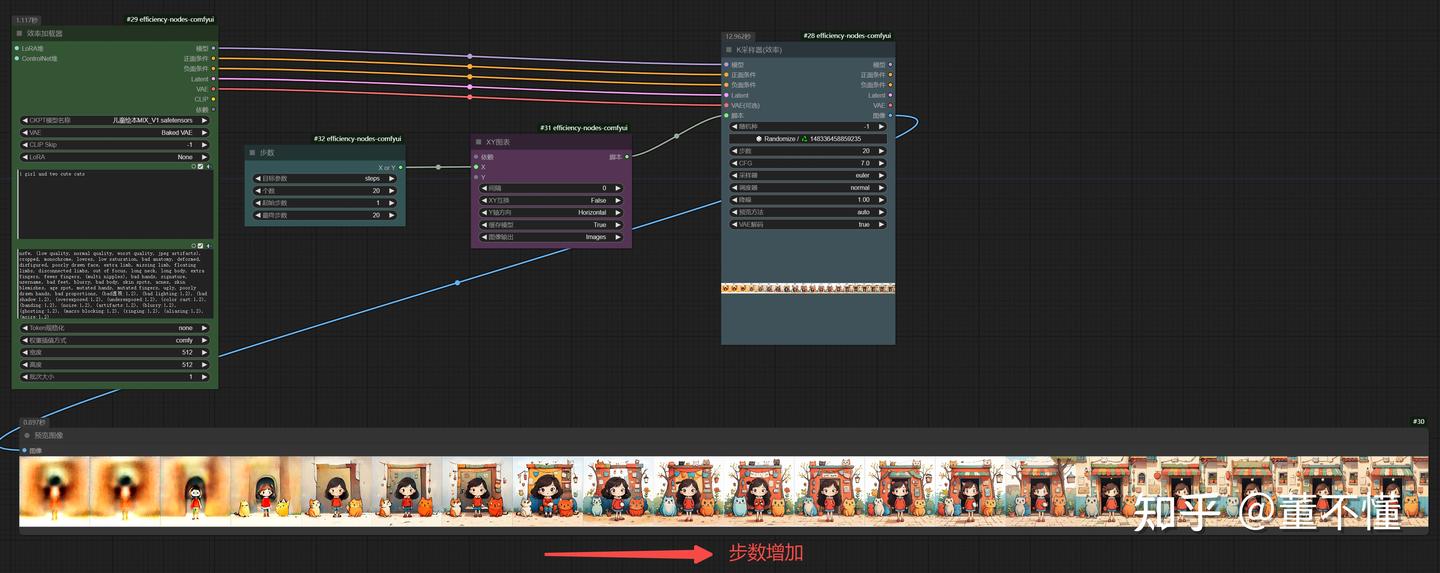
这里设置的总步数为20步,采样从第1步开始,到20步结束。从生成的图片来看,图片越来越清晰,直到20步采样结束。同时我们也发现,大概到15步左右,图像变化较少。
【结论】:步数越大,采样越多,图像越清晰;步数越小,采样越小,图像越模糊。根据经验一般我们设置步数为20-30之间,可以获得一个不错的效果。采样步数不能太大,太大的采样步数对图像生成影响不大,比如到15步的时候采样已经饱和了,从16步到20步的采样基本没有什么作用,而且还增加了生图时间。
参数:降噪
在文生图场景:它决定了在采样步骤之前的基础噪声量,降噪强度的取值范围为0到1,其中0表示基础噪声量为0,即不添加噪声,也就不会采样,出来的图像就是一片色块。而1表示基于最大噪声量进行采样,得到的图像色彩丰富,画质清晰。一般文生图场景,降噪这个参数都设置为1。
验证文生图不同降噪值对生图影响:
文生图降噪值效果验证
在图生图场景:它决定了在采样步骤之前向图像添加多少噪声。降噪强度的取值范围为0到1,其中0表示输入图像中不添加噪声,那么原图的变化就很小,而1表示输入图像完全被噪声替换,这样采样之后得到的图像和原图完全不一样,通过调整降噪强度,可以控制图像的变化程度,从而在保留原始图像和创建全新图像之间找到平衡。
验证图生图不同降噪值对生图影响:

图生图降噪值效果验证
【结论】:
在文生图场景,降噪值保持1不变即可,让AI自己发挥想象空间。
在图生图场景,降噪值越大,和原图差异越大,降噪值越小,和原图差异越小。
参数:CFG
CFG:提示词引导系数。用于控制生成过程中遵循文本提示严格程度的参数。通过调整CFG比例,可以平衡生成图像与输入文本提示的一致性与创造性的自由度。
我们还是通过效率节点,直观的感受一下CFG对生图变化的影响:
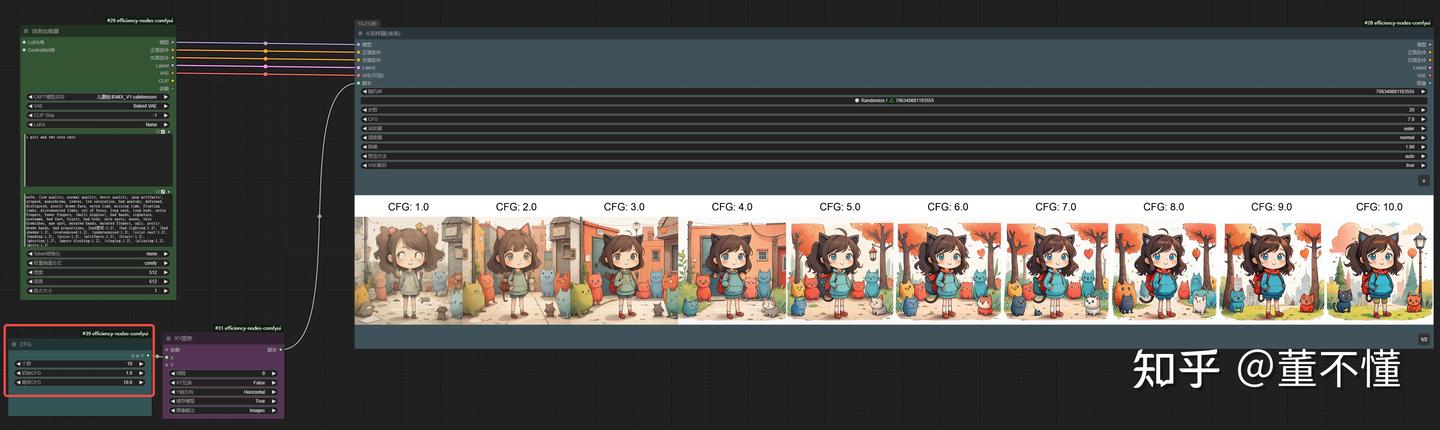
这里我给定CFG个数为10,从1开始,每次递增1,10结束。通过观察上图,我们大致可以得出结论:
1、随着CFG的增加,图像画质越来越好,颜色饱和度和对比度越来越强
2、随着CFG的增加,图像细节越来越少
3、随着CFG的增加,图像表达和提示词越来越接近
【参数应用】
1、这个参数默认为7,这个值可以很好的平衡创意自由度和遵循提示词
2、如果默认值不佳,可以通过效率节点调试最佳CFG
3、复杂提示词可以适当增加CFG值来实现更具细节化的效果
4、CFG最好不要过低(比如低于7),过低会导致图像画质不佳且和提示词无关
5、CFG最好不要过高(比如高于15),过高会丢失图像细节,且图像过度饱和,图像出现伪影
参数:随机种
"随机种"通常指的是随机噪声的种子(seed),它在图像生成过程中起到了重要的作用。随机种子是生成图像时的起始点,它决定了随机噪声的初始状态。通过改变随机种子,即使使用相同的文本提示,也可以生成不同的图像结果。
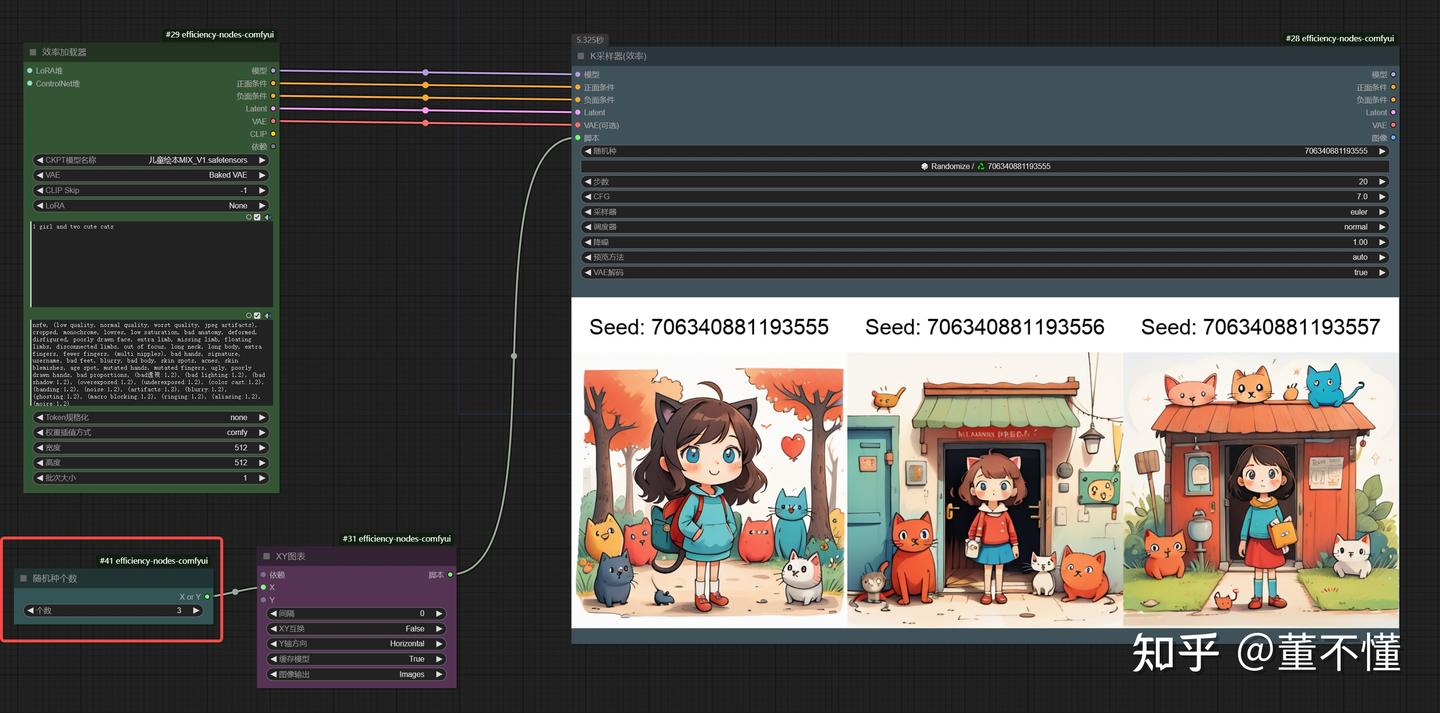
我们随机了3个随机种,可以看到,相同的提示词不同的种子,得到的图像是不同的。也就是说这3个随机种不一样,初始噪声也就不一样,经过相同的采样过程,得到的图像自然也就不一样。
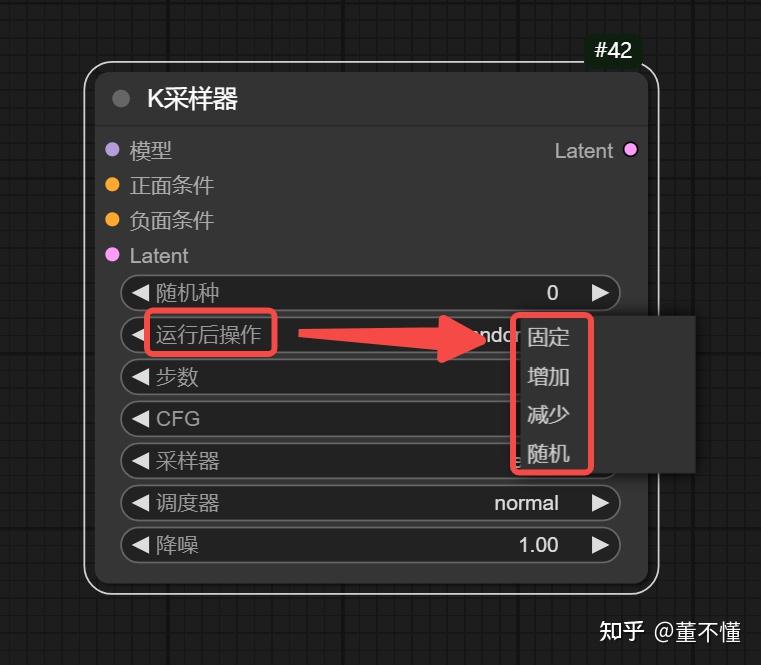
在K采样器中,随机种的下面还有一个参数:运行后操作,它有4个选项:固定、增加、减少、随机。
**固定:**固定种子之后,生图将不会发生变化
增加:执行队列后,种子值加1
减少:执行队列后,种子值减1
随机:执行队列后,种子随机发生变化
【结论】
1、随机种是随机噪声的初始状态,不同的随机噪声会直接影响最终生图
2、固定随机种,可以保持随机种不变,调整其他参数,查看生图效果
参数:采样器
从这个列表来看,采样器的种类非常多,但大体可以分为以下4类
1、euler(欧拉采样)
euler
euler_cfg_pp
euler_ancestral
euler_ancestral_cfg_pp
heun
heunpp2
欧拉采样的最显著的特色就是不会引入随机性,会按照预定的噪声进行降噪逐步的将噪声引导到最终图像,适用于稳定性和可预测场景。
欧拉采样分两类: euler:最基础采样器,一次采样。heun:euler的改进版,采用两次采样方式提升图像质量,由于是两次采样,所以生图时间也是euler的两倍。heunpp2是heun的改进版, 用于生成更加复杂的图像。cfg_pp的意思是适用于较低CFG值场景,但需要更大的采样步数,通常是50步左右,比如CFG=1, 步数=50。
有ancestral字样的采样器,在采样过程中,会添加随机噪声,这样一来每一步生成的图形都不一样,也称为:画面不收敛,适用于自由创意场景,以下是使用euler和euler_a采样器生成图像的对比:我们发现使用euler采样器生图比较固定,euler_a采样器每一张图变化较大且都不一样。
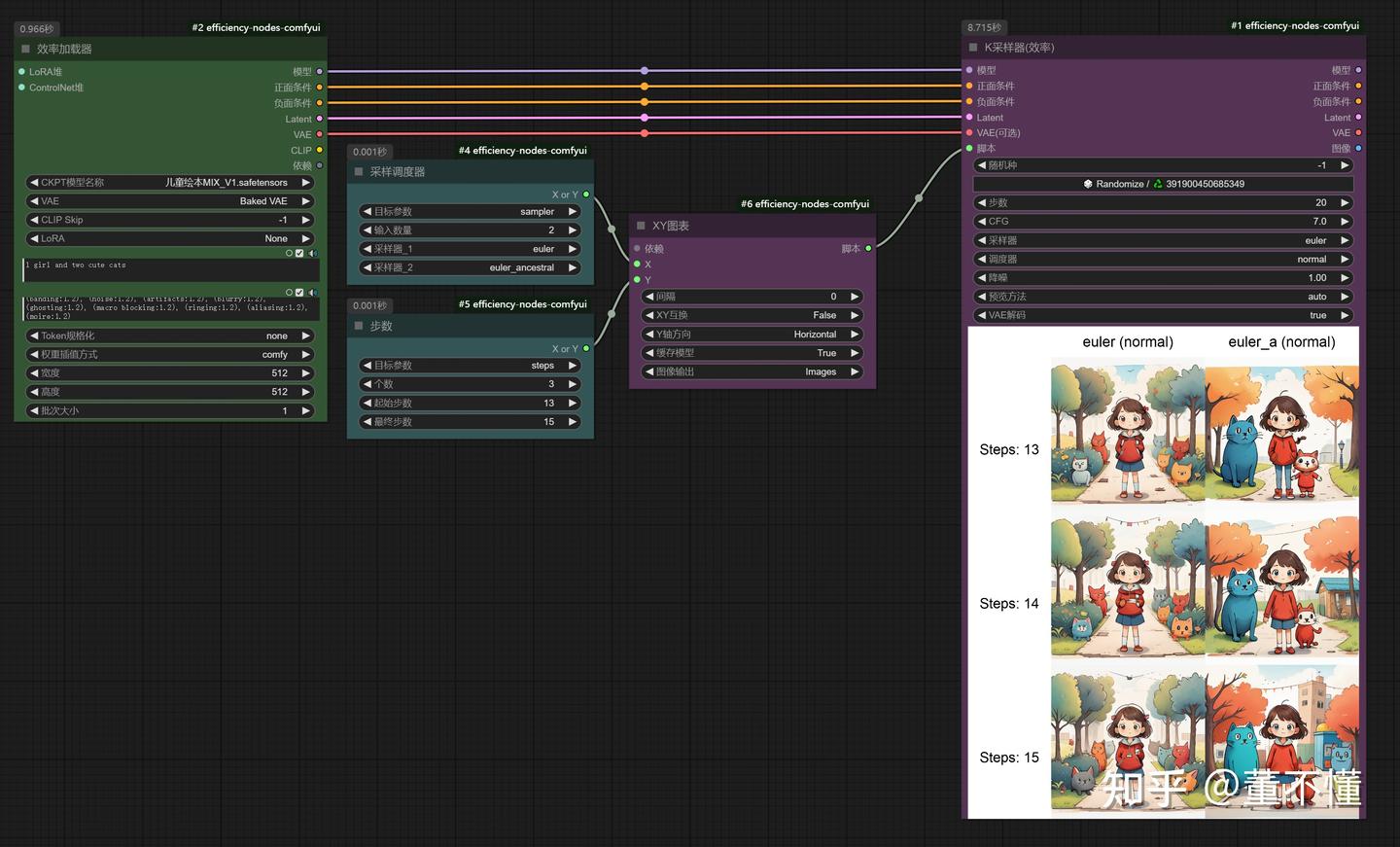
euler采样器:画面收敛
euler-a采样器:画面不收敛
2、dpm采样器
DPM的主要优点是生成质量高,但是由于DPM会自适应调整步长,不能保证在约定的采样步骤内完成任务,整体速度可能会比较慢。
dpm_fast
dpm_adaptive
dpm_2
dpm_2_ancestral
dpmpp_2s_ancestral
dpmpp_2s_ancestral_cfg_pp
dpmpp_sde
dpmpp_sde_gpu
dpmpp_2m
dpmpp_2m_cfg_pp
dpmpp_2m_sde
dpmpp_2m_sde_gpu
dpmpp_3m_sde
dpmpp_3m_sde_gpu
版本顺序:dpm -> dpm2 -> dpmpp
dpm一代包括:dpm_fast是一个实验采样器,我们基本不用。dpm_adaptive不管采样步数是多少,都会生成相同的图像,所以步数没什么意义,并且非常耗时。
dpm二代:dpm一代的迭代版本,有2个:dpm_2(稳定版)和dpm_2_ancestral(发散版),耗时是一代的2倍,生图质量较一代更好。
dpmpp:dpm二代的迭代版本,有更出色的出图质量。其中后缀中含有sde的是随机采样器,和euler很相似。后缀中含有2m表示采样过程中采用二阶采样,即使用预测期和校正器进行采样,后缀中含有3m的表示在采样过程中除了使用预测期和校正器,还有修正器。
3、uni_pc采样器
uni_pc
uni_pc_bh2
UniPC(统一预测校正器),这种采样器可以在5-10步内生成收敛图像,uni_pc_bh2是uni_pc的优化版本,10步以上生成高质量图像。
5、其他采样器
ims
ddpm
LCM
ipndm
ipndm_v
deis
ddim
这几个采样器不常用,这里就步介绍了。以下我们选择几个采样器的对比图:

采样器那么多,我们如何选择采样器呢?基于上述采样器的对比,我们得出以下结论:
1、如果你考虑的是稳定性,大前提是不要选择带后缀为_ancestral和_sde的采样器
2、如果你考虑的是随机性,可以考虑带后缀为_ancestral和_sde的采样器
3、这些采样器可以不考虑:dpm_fast、dpm_adaptive、dpmpp_3m_sde、dpmpp_3m_sde_gpu、ipndm
4、优先考虑的采样器:euler,dpmpp_2m,uni_pc(这三个是代表采样器)
从采样时间维度,各个采样器的耗时对比:
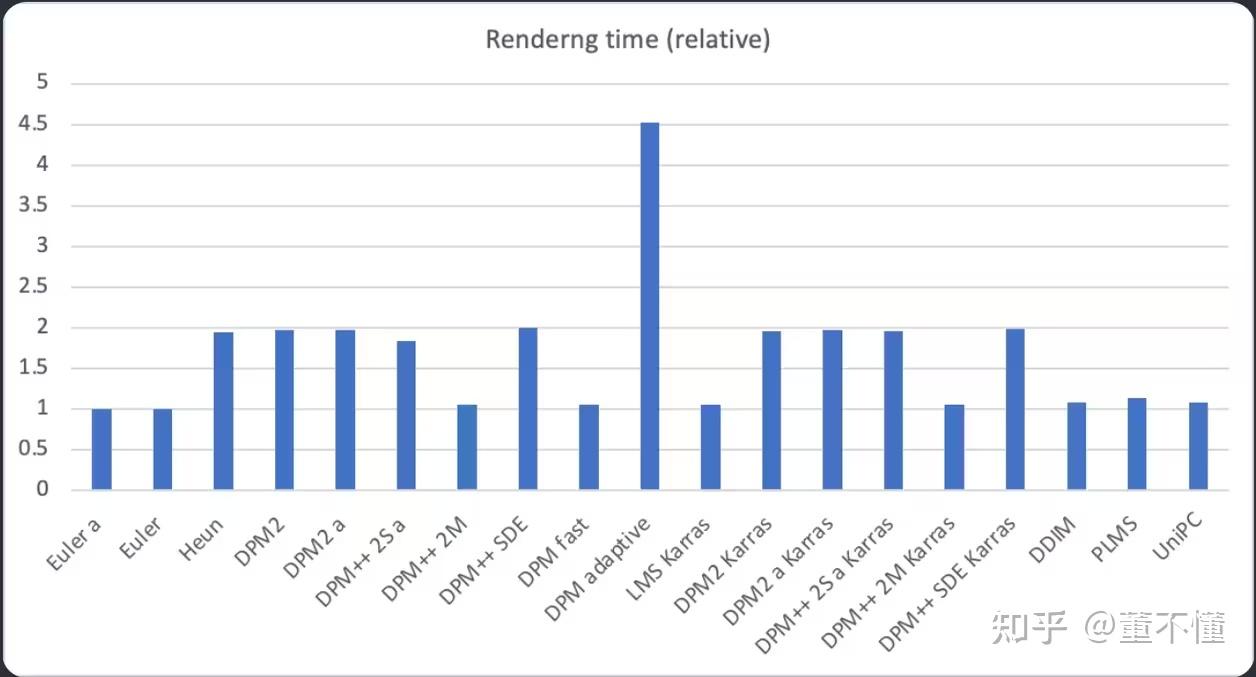
综合来看,euler采样器在出图时间和出图质量的一个最佳权衡,出图较快且稳定收敛。dpmpp_2m也是一个很好的选择,出图速度快,并且出图质量优于euler,也可以考虑uni_pc采样器。
参数:调度器
调度器(Scheduler)负责控制生成过程中每一步的噪声减少水平,也就是所谓的噪声计划(Noise Schedule)。不同的调度器有不同的噪声减少策略。
normal
这是最基础的调度器,它是基于正态分布的调度器,适用于非常平滑和连续变化的场景。
karras:
Karras调度器基于Karras等人的研究,通过在生成过程中使用特定的噪声减少路径来生成图像。它在图像生成的最后阶段减小噪声减少的步长,有助于提高图像质量。
exponential
Exponential调度器生成一系列按照指数时间表的sigma值。它允许在扩散过程的早期阶段快速去除大部分噪声,然后在后期阶段进行细致调整,如果采样步数较大,它会发挥较好的性能。通常与deis采样器配搭使用。
sgm_uniform:
Sgm Uniform调度器是为SDXL-Lightning模型设计的,它在模型的扩散过程中提供了更均匀的噪声减少策略。
它适用于lightning类型的模型,并且在少量采样步数下能够生成质量较好的图像 。
simple
Simple调度器提供了一种简单的噪声减少策略,适合于机器性能不高的场景。
ddim_uniform
DDIM Uniform调度器是DDIM(Denoising Diffusion Implicit Models)的一种变体,它在生成过程中提供了更均匀的噪声减少。这种调度器可能在生成图像时提供更多的多样性和随机性 。
Beta:
Beta调度器指的是一种基于Beta分布的噪声减少策略,它在生成过程中根据Beta分布的特性来调整噪声水平。
normal调度器是默认调度器,一般和euler配搭,karras调度器和dpm采样器配搭,beta调度器一般和uni_pc采样器配搭。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1358
1358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









