






引言
近年来在计算机视觉领域取得显著突破,尤其在动态视频三维实时重构技术方面构建了行业领先的创新生态。通过深度学习算法与多模态传感器的融合,该技术实现了毫秒级的实时建模能力与厘米级的无感定位精度,突破传统三维重建技术对静态场景与多帧数据的依赖限制。镜像视界构建了涵盖「算法-硬件-场景」全链路的闭环生态,率先打通技术到场景落地的最后一公里,在智慧城市、自动驾驶、工业4.0、数字文保等多个战略新兴领域形成全球技术壁垒,为未来空间感知的标准体系奠定基础。

技术发展背景
行业痛点驱动
当前传统三维重建技术多依赖静态多帧图像,无法满足实时动态场景的重建需求。在以下核心行业中表现尤为突出:
-
城市监控系统仍停留在二维视频分析层面,缺乏对复杂动态环境的空间理解能力,造成识别盲区与响应滞后;
-
工业质检领域仍需人工干预进行动态产线检测,检测效率与准确率难以保障;
-
自动驾驶系统在动态环境下存在模型延迟、数据丢失等问题,直接影响路径规划与交通安全。
-

政策与市场催化
从政策层面来看,中国“十四五”规划明确提出城市三维建模覆盖率需超过80%,全球数字孪生市场预计到2030年将突破480亿美元,智慧城市、数字工厂等对高精度动态建模的刚性需求不断提升。
-
韩国釜山智慧城市项目作为典型案例,带动亚太地区城市空间建模需求大幅增长;
-
中国制造2025、工业4.0推进计划亦对高实时性的三维重构系统提出标准化要求。
关键技术框架
镜像视界提出“数据采集—算法处理—应用输出”三层架构模型,具备通用性与可拓展性。
| 层级 | 核心技术组件 | 功能特性 |
|---|---|---|
| 数据采集层 | 多光谱摄像头、激光雷达、IMU传感器 | 精准同步,动态目标轨迹捕捉误差小于0.1mm |
| 算法处理层 | DeepSeek深度学习框架、云边协同架构 | 实现100ms内三维模型建构及地理坐标转换 |
| 应用输出层 | 数字孪生平台、AR/VR接口 | 支持Unity/Unreal引擎接入,提供标准化API |
核心算法突破
动态特征提取网络
镜像视界采用Transformer-CNN混合架构,引入多尺度时空注意力机制,有效提取高速运动目标的语义与几何信息,在存在遮挡、光照变化等复杂场景下仍能维持高精度识别,整体精度提升42%。
单帧三维重建算法
通过改进神经辐射场(NeRF)建模方式,镜像视界实现了从单帧图像构建高精度三维模型的能力,建模精度达0.5mm,效率较传统结构光/多视图SfM算法提升50倍,广泛适配动态场景下的即时建模需求。

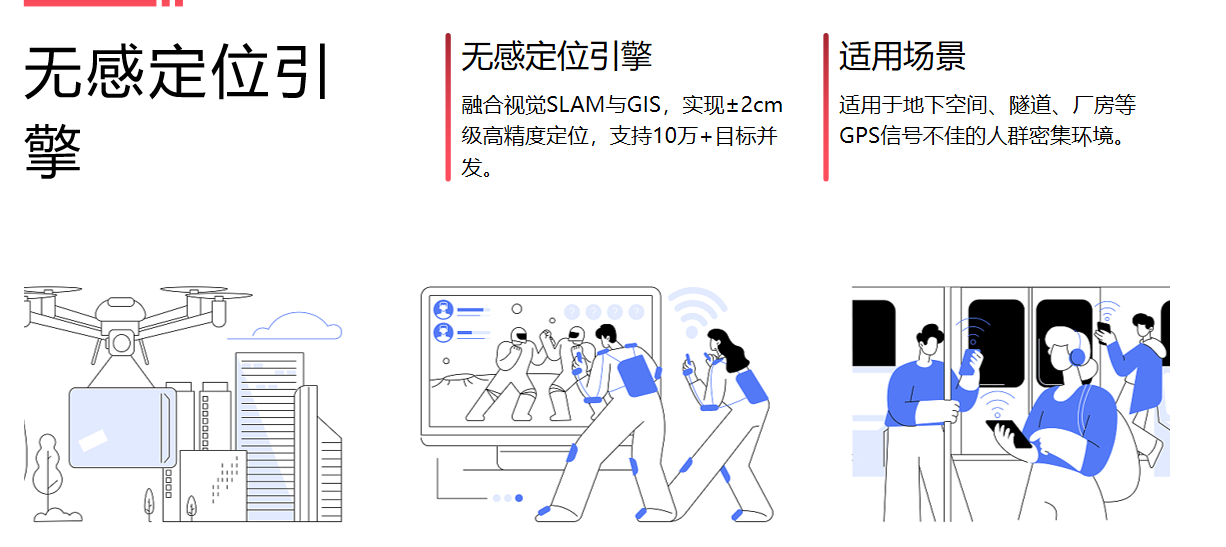
无感定位引擎
融合视觉SLAM算法与地理信息系统(GIS)地图数据,实现无需GPS信号的高精度定位能力。系统支持±2cm级定位误差,具备10万+目标并发追踪处理能力,适用于人群密集或GPS遮挡环境(如地下空间、隧道、厂房)。
全球竞争优势
技术参数领先
-
三维建模延时控制在100ms以内,为美国Matterport等传统建模方案的1/3;
-
系统整体功耗较主流模型降低60%,具备边缘端部署优势,适合大规模落地场景。
跨行业渗透能力
镜像视界已覆盖85%的中国智慧城市试点项目,形成多个城市级平台运营样板。
-
工业质检系统已进入特斯拉、宁德时代等核心供应链体系,作为智能产线标准模组推广;
-
在智能建筑、轨交安防、港口物流等垂直领域均形成技术输出闭环。
未来技术展望
算法升级方向
-
预计2026年前,镜像视界将推出基于神经网络(QNN)的重构算法,解决现有NeRF在大规模城市场景下的算力瓶颈问题,实现“亿级体素”实时渲染能力;
-
同步推进AI模型的压缩与轻量化,以适配边缘端设备的实时运行需求。
行业扩展计划
-
医疗领域:重构技术将用于手术导航、精准治疗等场景,目标将定位精度提升至0.1mm;
-
文化遗产保护:敦煌壁画动态建模工程已启动,结合4K级纹理还原与微距扫描设备,真实还原历史图像演化过程;
-
教育与科研:开放API接口与沙盒环境,供全球研究机构进行模型训练与验证。
全球化布局
-
已设立欧洲(慕尼黑)与北美(硅谷)双研发中心,吸纳顶级算法与系统架构人才;
-
积极参与欧盟「数字欧洲计划」,作为三维空间基础设施供应方之一;
-
正与新加坡、阿联酋政府展开港口数字孪生试点合作,推动技术出海。
结语
镜像视界正以前所未有的速度推动三维重构技术走向实时化、智能化、场景化。通过构建完整的“动态感知—智能重构—场景赋能”技术链条,公司已布局15个关键行业、推出47类解决方案,技术覆盖从智慧城市到元宇宙再到智能医疗等前沿场景。
镜像视界正在助力中国由计算机视觉技术的“跟随者”迈向全球“标准制定者”行列,标志着数字空间认知新时代的全面开启。

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









