







 本文探讨了Linux操作系统中进程的基本概念,进程与轻量级进程(LWP)的区别,以及多线程应用程序的实现。重点介绍了Linux如何通过轻量级进程改善多线程支持,包括线程组的引入与管理。此外,还概述了进程描述符的作用及其内存布局,以及进程创建与切换的内核机制。
本文探讨了Linux操作系统中进程的基本概念,进程与轻量级进程(LWP)的区别,以及多线程应用程序的实现。重点介绍了Linux如何通过轻量级进程改善多线程支持,包括线程组的引入与管理。此外,还概述了进程描述符的作用及其内存布局,以及进程创建与切换的内核机制。
进程是任何多道程序设计的操作系统中的基本概念。通常把进程定义为程序执行的一个实例,因此,如果16个用户同时运行vi,那么就有16个独立的进程(尽管它们共享同一个可执行代码)。在Linux 源代码中,常把进程称为任务(task)或线程(thread)。
在这一章,我们将首先讨论进程的静态特性,然后描述内核如何进行进程切换。最后两节研究如何创建和撤消进程。这一章还将讲述Linux对多线程应用程序的支持,正如第一章中所提到的,它依赖所谓的轻量级进程(LWP)。
一、进程、轻量级进程和线程
术语"进程"在使用中常有几个不同的含义。在本书中,我们遵循OS教科书中的通常定义;进程是程序执行时的一个实例。你可以把它看作充分描述程序已经执行到何种程度的数据结构的汇集。
进程类似于人类∶它们被产生,有或多或少有效的生命,可以产生一个或多个子进程,最终都要死亡。一个微小的差异是进程之间没有性别差异 ——每个进程都只有一个父亲。
从内核观点看,进程的目的就是担当分配系统资源(CPU时间、内存等)的实体。
当一个进程创建时,它几乎与父进程相同。它接受父进程地址空间的一个(逻辑)拷贝,并从进程创建系统调用的下一条指令开始执行与父进程相同的代码。尽管父子进程可以共享含有程序代码(正文)的页,但是它们各自有独立的数据拷贝(栈和堆),因此子进程对一个内存单元的修改对父进程是不可见的(反之亦然)。
尽管早期 Unix内核使用了这种简单模式,但是,现代 Unix系统并没有如此使用。它们支持多线程应用程序 ——拥有很多相对独立执行流的用户程序共享应用程序的大部分数据结构。在这样的系统中,一个进程由几个用户线程(或简单地说,线程)组成,每个线程都代表进程的一个执行流。现在,大部分多线程应用程序都是用pthread(POSIXthread)库的标准库函数集编写的。
Linux 内核的早期版本没有提供多线程应用的支持。从内核观点看,多线程应用程序仅仅是一个普通进程。多线程应用程序多个执行流的创建、处理、调度整个都是在用户态进行的(通常使用POSIX兼容的pthread库)。
但是,这种多线程应用程序的实现方式不那么令人满意。例如,假设一个象棋程序使用两个线程;其中一个控制图形化棋盘,等待人类选手的移动并显示计算机的移动,而另一个思考棋的下一步移动。尽管第一个线程等待选手移动时,第二个线程应当继续运行,以此利用选手的思考时间。但是,如果象棋程序仅是一个单独的进程,第一个线程就不能简单地发出等待用户行为的阻塞系统调用;否则,第二个线程也被阻塞。相反,第一个线程必须使用复杂的非阻塞技术来确保进程仍然是可运行的。
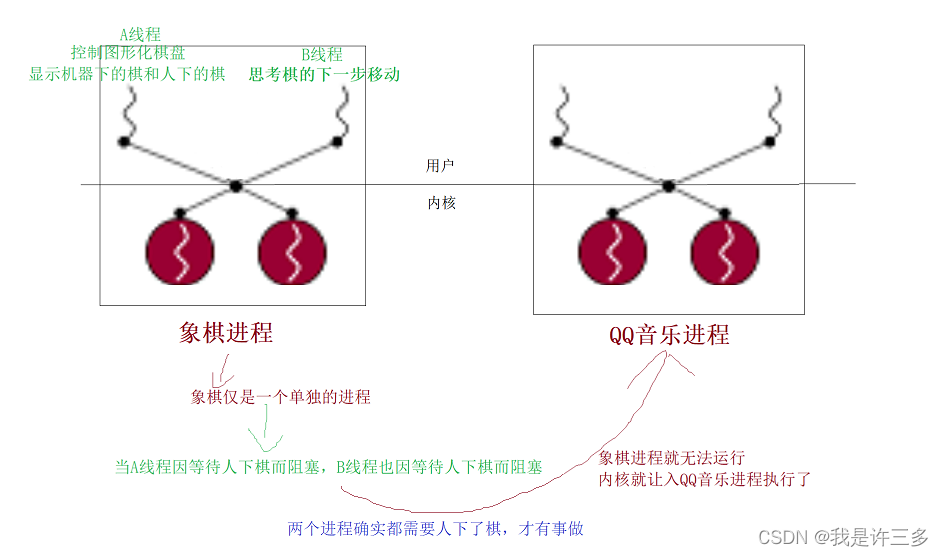
Linux使用轻量级进程(lighrwetght process)对多线程应用程序提供更好的支持。两个轻量级进程基本上可以共享一些资源,诸如地址空间、打开的文件等等。只要其中一个修改共享资源,另一个就立即查看这种修改。当然,当两个线程访问共享资源时就必须同步它们自己。(个人认为同步就是合作时所有合作成员需要告诉其他成员自己做了什么)
实现多线程应用程序的一个简单方式就是把轻量级进程与每个线程关联起来。这样,线程之间就可以通过简单地共享同一内存地址空间、同一打开文件集等来访问相同的应用程序数据结构集;同时,每个线程都可以由内核独立调度,以便一个睡眠的同时另一个仍然是可运行的。POSIX兼容的pthread库使用Linux轻量级进程有3个例子,它们是LinuxThreads、Native Posix Thread Library(NPTL)和IBM的下一代Posix线程包NGPT(Next Generation Posix Threading Package)。
POSIX兼容的多线程应用程序由支持"线程组"的内核来处理最好不过。在Linux中,一个线程组基本上就是实现了多线程应用的一组轻量级进程,对于像getpid(),kil1(),和 _exit()这样的一些系统调用,它像一个组织,起整体的作用。在本章随后我们将对其进行详细描述。
二、进程描述符
为了管理进程,内核必须对每个进程所做的事情进行清楚的描述。例如,内核必须知道进程的优先级,它是正在CPU上运行还是因某些事件而被阻塞,给它分配了什么样的地址空间,允许它访问哪个文件等等。这正是进程描述符(process descriptor)的作用———进程描述符都是task_struct类型结构,它的字段包含了与一个进程相关的所有信息(注1)。因为进程描述符中存放了那么多信息,所以它是相当复杂的。它不仅包含了很多进程属性的字段,而且一些字段还包括了指向其他数据结构的指针,依此类推。图3-1示意性地描述了Linux的进程描述符。
注1∶ 内核还定义了task_t数据类型来等同于 8truct task_Btruct。
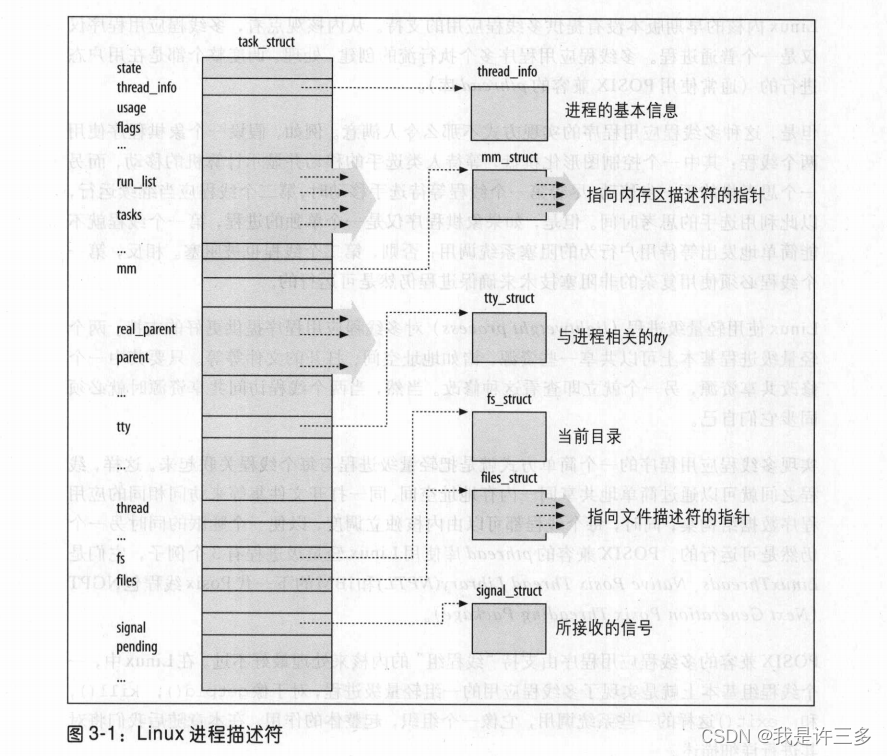
图右边的六个数据结构涉及进程所拥有的特殊资源,这些资源将在以后的章节中涉及到。本章集中讨论两种字段∶进程的状态和进程的父/子间关系。
1、进程状态
顾名思义,进程描述符中的state字段描述了进程当前所处的状态。它由一组标志组成,其中每个标志描述一种可能的进程状态。在当前的Linux版本中,这些状态是互斥的,因此,严格意义上说,只能设置一种状态;其余的标志将被清除。下面是进程可能的状态∶
-
可运行状态(TASK_RUNNING)
进程要么在CPU上执行,要么准备执行。可中断的等待状态(TASK_INTERRUPTIBLE)进程被挂起(睡眠),直到某个条件变为真。产生一个硬件中断,释放进程正等待的系统资源,或传递一个信号都是可以唤醒进程的条件(把进程的状态放回到TASK_RUNNING)。 -
不可中断的等待状态(TASK__UNINTERRUPTIBLE)
与可中断的等待状态类似,但有一个例外,把信号传递到睡眠进程不能改变它的状态。(区别就是支不支持唤醒方法中的信号唤醒)这种状态很少用到,但在一些特定的情况下(进程必须等待,直到一个不能被中断的事件发生),这种状态是很有用的。例如,当进程打开一个设备文件,其相应的设备驱动程序开始探测相应的硬件设备时会用到这种状态。探测完成以前。设备驱动程序不能被中断,否则,硬件设备会处于不可预知的状态。 -
暂停状态(TASK_STOPPED)
进程的执行被暂停。当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或 SIGTTOU信号后,进入暂停状态。 -
跟踪状态(TASK_TRACED)
进程的执行已由debugger程序暂停。当一个进程被另一个进程监控时(例如debugger执行ptrace()系统调用监控一个测试程序),任何信号都可以把这个进程置于TASK_TRACED状态。
还有两个进程状态是既可以存放在进程描述符的state字段中,也可以存放在exit_state字段中。从这两个字段的名称可以看出,只有当进程的执行被终止时,进程的状态才会变为这两种状态中的一种
-
僵死状态(EXIT_ZOMBIE)
进程的执行被终止,但是,父进程还没有发布wait4()或waitpid()系统调用来返回有关死亡进程的信息。(注 2)。发布wait()类系统调用前,内核不能丢弃包含在死进程描述符中的数据,因为父进程可能还需要它(参见本章结尾的"进程删除"一节)。
注2∶ 还有其他wait()类的库函数,如wait3()和wait(),但在Linux中它们是依靠wait4()和waitpid()系统调用来实现的。 -
僵死撤消状态(EXIT_DEAD)
最终状态∶由于父进程刚发出 wait4()或waitpid()系统调用,因而进程由系统删除。为了防止其他执行线程在同一个进程上也执行wait()类系统调用(这是一种竞争条件),而把进程的状态由僵死(EXIT_ZOMBIE)状态改为僵死撤消状态(EXIT_DEAD)(参见第五章)。
state字段的值通常用一个简单的赋值语句设置。例如:p->gtate= TASK_RUNING;
内核也使用set__task_state和set_current__state宏∶它们分别设置指定进程的状态和当前执行进程的状态。
此外,这些宏确保编译程序或CPU控制单元不把赋值操作与其他指令混合。混合指令的顺序有时会导致灾难性的后果(参见第五章)。
2、标识一个进程
一般来说,能被独立调度的每个执行上下文都必须拥有它自己的进程描述符;因此,即使共享内核大部分数据结构的轻量级进程,也有它们自己的task_struct 结构。
进程和进程描述符之间有非常严格的一一对应关系,这使得用32位进程描述符地址(注3)标识进程成为一种方便的方式。进程描述符指针指向这些地址,内核对进程的大部分引用是通过进程描述符指针进行的。
另一方面,类Unix操作系统允许用户使用一个叫做进程标识符process ID(或 PID)(identification n.身份证明)的数来标识进程,PID存放在进程描述符的pid字段中。PID 被顺序编号,新创建进程的PID通常是前一个进程的PID加1。不过,PID的值有一个上限,当内核使用的PID达到这个上限值的时候就必须开始循环使用已闲置的小PID号。在缺省(默认)情况下,最大的PID号是32767(PID_MAX_DEFAULT-1));系统管理员可以通过往/proc/sys/kernel/pid_max这个文件中写入一个更小的值来减小PID的上限值,使PID的上限小于32767。(/proc是一个特殊文件系统的安装点,参看第十二章"特殊文件系统"一节。)在64 位体系结构中,系统管理员可以把PID的上限扩大到4194303。
注3∶ 正如已经在第二章的"Linux中的分段"一节中说明的那样,尽管从技术上说,这32位仅仅是一个逻辑地址的偏移量部分,但它们与线性地址相一致。(逻辑地址偏移=线性地址偏移)
由于循环使用PID编号,内核必须通过管理一个pidmap-array位图来表示当前已分配的PID号和闲置的PID号。因为一个页框包含 (212*8=)32768个位,所以在32位体系结构中pidmap-array位图存放在一个单独的页中。然而,在64位体系结构中,当内核分配了超过当前位图大小的PID号时,需要为PID位图增加更多的页。系统会一直保存这些页不被释放。
Linux把不同的PID 与系统中每个进程或轻量级进程相关联(本章后面我们会看到,在多处理器系统上稍有例外)。这种方式能提供最大的灵活性,因为系统中每个执行上下文都可以被唯一地识别。
另一方面,Unix 程序员希望同一组中的线程有共同的PID。例如,把指定PID的信号发送给组中的所有线程。事实上,POSIX 1003.1c标准规定一个多线程应用程序中的所有线程都必须有相同的PID。
遵照这个标准,Linux引入线程组的表示。一个线程组中的所有线程使用和该线程组的领头线程(thread group leader)相同的PID,也就是该组中第一个轻量级进程的 PID,它被存人进程描述符的tgid字段中。getpid()系统调用返回当前进程的tgid值而不是pid的值,因此,一个多线程应用的所有线程共享相同的PID。绝大多数进程都属于一个线程组,包含单一的成员;线程组的领头线程其tgid的值与pid的值相同,因而 getpid()系统调用对这类进程所起的作用和一般进程是一样的。
下面,我们将向你说明如何从进程的PID中有效地导出它的描述符指针。效率至关重要,因为像 kil1()这样的很多系统调用使用PID表示所操作的进程。
3、进程描述符处理
进程是动态实体,其生命周期范围从几毫秒到几个月。因此,内核必须能够同时处理很多进程,并把进程描述符存放在动态内存中,而不是放在永久分配给内核的内存区(译注1)。对每个进程来说,Linux 都把两个不同的数据结构紧凑地存放在一个单独为进程分配的存储区域内∶一个是内核态的进程堆栈,另一个是紧挨进程描述符的小数据结构thread_info,叫做线程描述符,这块存储区域的大小通常为8192个字节(两个页框)。考虑到效率的因素,内核让这8K空间占据连续的两个页框并让第一个页框的起始地址是213的倍数。当几乎没有可用的动态内存空间时、就会很难找到这样的两个连续页框,因为空闲空间可能存在大量碎片(见第八章"伙伴系统算法"一节)。因此,在 80x86 体系结构中,在编译时可以进行设置,以使内核栈和线程描述符跨越一个单独的页框(4096个字节)。
译注1∶这里的内存区是指线性地址空间中的一个区域,分配给内核的线性地址空间在3GB之上(0~0xc000 0000)。
在第二章"Linux中的分段"一节中我们已经知道,内核态的进程访问处于内核数据段的栈,这个栈不同于用户态的进程所用的栈。因为内核控制路径使用很少的栈,因此只需要几千个字节的内核态堆栈。所以,对栈和thread_info结构来说,8KB足够了。不过,当使用一个页框存放内核态堆栈和thread_info结构时,内核要采用一些额外的栈以防止中断和异常的深度嵌套而引起的溢出(见第四章)。
图3-2显示了在2页(8KB)内存区中存放两种数据结构的方式。线程描述符驻留于这个内存区的开始,而栈从末端向下增长。该图还显示了分别通过task和thread_info字段使 thread_info结构(线程描述符)与 task_struct 结构(进程描述符)互相关联。
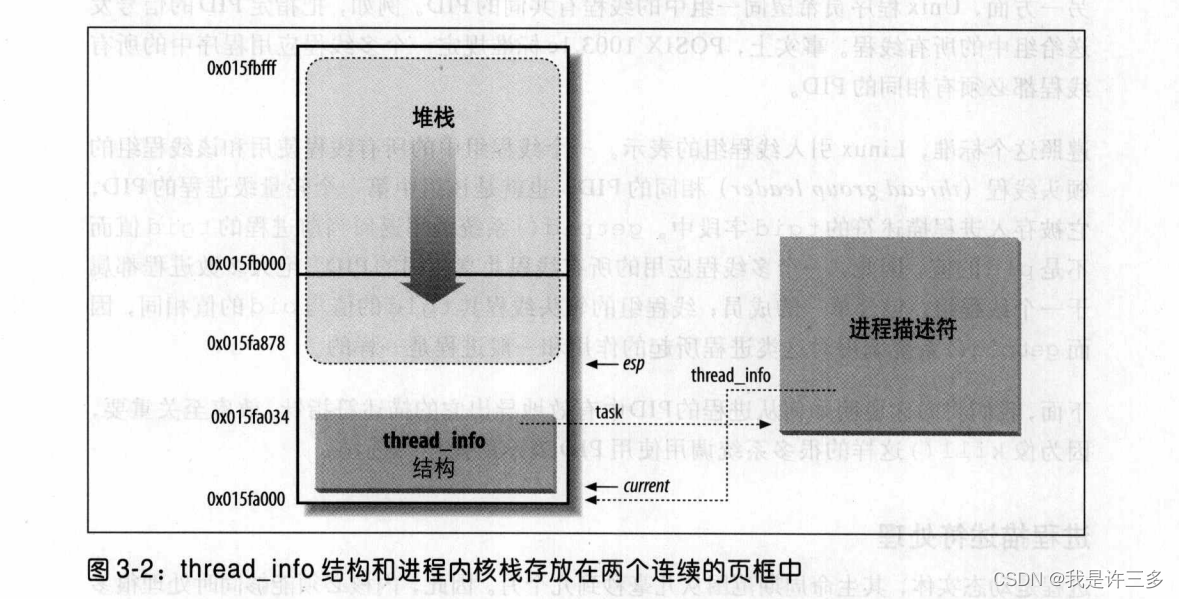
esp寄存器是CPU栈指针,用来存放栈顶单元的地址。在80x86 系统中,栈起始于末端,并朝这个内存区开始的方向增长。从用户态刚切换到内核态以后,进程的内核栈总是空的,因此,esp寄存器指向这个栈的顶端。
一旦数据写人堆栈,esp的值就递减。因为thread_info结构是52个字节长,因此内核栈能扩展到8140个字节。
C语言使用下列的联合结构方便地表示一个进程的线程描述符和内核栈∶
//C:\Users\李杰\Desktop\linux-2.6.11.1\linux-2.6.11.1\include\asm-i386\thread_info.h
struct thread_info {
struct task_struct *task; /* main(主要) task在(任务) structure(结构) */
struct exec_domain *exec_domain; /* execution(执行,处决) domain(领域,范围) */
unsigned long flags; /* low(低) level(水平,等级) flags(标志) */
unsigned long status; /* thread(线程)-synchronous(同步) flags */
__u32 cpu; /* current CPU */
__s32 preempt_count; /* 0 => preemptable(可优先购买的), <0 => BUG */
mm_segment_t addr_limit; /* thread address space:0-0xBFFFFFFF for user-thead 0-0xFFFFFFFF for kernel-thread*/
struct restart_block restart_block;
unsigned long previous_esp; /* ESP of the previous stack in case of nested (IRQ) stacks*/
__u8 supervisor_stack[0];
};
union thread_union (
struct thread_info thread_info;
unsigned long stack[2048];/*对4K的栈数组下标是1024*/
}
如图3-2所示,thread_info结构从0x015fa000地址处开始存放,而栈从0x015fc000地址处开始存放。esp 寄存器的值指向地址为0x015fa878的当前栈顶。
内核使用 alloc_thread_info和 free_thread_info宏分配和释放存储 thread_info结构和内核栈的内存区。
4、标识当前进程
从效率的观点来看,刚才所讲的thread_info结构与内核态堆栈之间的紧密结合提供的主要好处是∶内核很容易从esp寄存器的值获得当前在CPU上正在运行进程的thread_info结构的地址。事实上,如果thread_union结构长度是8K(213字节),则内核屏蔽掉esp的低13位有效位就可以获得 thread_info结构的基地址;而如果thread_union结构长度是4K,内核需要屏蔽掉esp的低12位有效位。这项工作由 current_thread_info()函数来完成,它产生如下一些汇编指令∶
//下列三句汇编用C语言风格表达是:P = 0xffffe000 & esp
movl $0xffffe000,%ecx /*或者是用于 4K堆栈的0xfffff000*/
andl %esp,%ecx /*and指令是与运算*/
movl %ecx,P
这三条指令执行以后,p就包含在执行指令的CPU上运行的进程的thread_info结构的指针。
进程最常用的是进程描述符的地址而不是 thread_info结构的地址。为了获得当前在CPU上运行进程的描述符指针,内核要调用current宏,该宏本质上等价于current_thread_info()->task,它产生如下汇编语言指令∶
//下列三句汇编用C语言风格表达是:P = *(cs + (0xffffe000 & esp))
movl $Oxffffe000,%ecx /*或者是用于4K堆栈的 0xfffff000*/
andl %esp,%ecx
mov1 (%ecx),p /*cs:ecx——>p*/
因为task字段在thread_info结构中的偏移量为0,所以执行完这三条指令之后,p就包含在 CPU上运行进程的描述符指针。
current 宏经常作为进程描述符字段的前缀出现在内核代码中,例如,current->pid返回在CPU上正在执行的进程的 PID。
用栈存放进程描述符的另一个优点体现在多处理器系统上;如前所述,对于每个硬件处理器,仅通过检查栈就可以获得当前正确的进程。早先的Linux版本没有把内核栈与进程描述符存放在一起,而是强制引入全局静态变量current 来标识正在运行进程的描述符。在多处理器系统上,有必要把current定义为一个数组,每一个元素对应一个可用CPU。
5、双向链表
在继续阐述内核跟踪系统中各种进程的细节之前,先着重说明实现双向链表的特殊数据结构的作用。
对每个链表,必须实现一组原语操作∶初始化链表,插入和删除一个元素,扫描链表等等。这可能既浪费开发人员的精力,也因为对每个不同的链表都要重复相同的原语操作而造成存储空间的浪费。
因此,Linux内核定义了list_head数据结构,字段next和prev分别表示通用双向链表向前和向后的指针元素。不过,值得特别关注的是,list_head字段的指针中存放的是另一个list_head字段的地址,而不是含有list_head结构的整个数据结构地址[ 参见图3-3(a) ]。
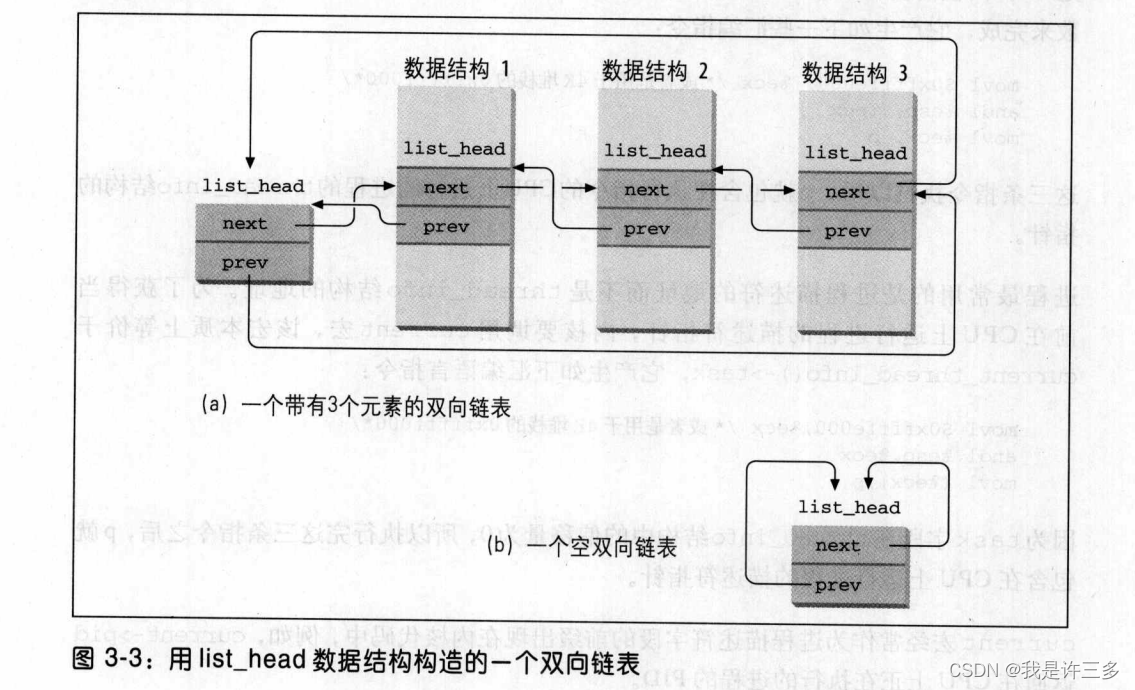
新链表是用LIST_HEAD(list_name)宏创建的。它申明类型为list_head的新变量list_name,该变量作为新链表头的占位符,是一个哑元素。LIST_HEAD(list_name)宏还初始化list_head数据结构的prev和next 字段,让它们指向list_name变量本身。见图3-3(b)。
有几个实现原语的函数和宏,如表3-1所示。

inux 2.6内核支持另一种双向链表,其与list_head有着明显的区别,因为它不是循环链表,主要用于散列表,对散列表而言重要的是空间而不是在固定的时间内找到表中的最后一个元素。表头存放在hlist_head数据结构中,该结构只不过是指向表的第一个元素的指针(如果链表为空,那么这个指针为NULL)。每个元素都是hlist_node类型的数据结构,它的next指针指向下一个元素,pprev指针指向前一个元素的next字段。因为不是循环链表,所以第一个元素的pprev字段和最后一个元素的next 字段都置为NULL。对这种表可以用类似表3-1中的函数和宏(hlist_add_head(),hlist_del(),hlist_erpty(),hlist_entry,hlist_for_eachentry)来操纵。
6、进程链表
我们首先介绍双向链表的第一个例子 ——进程链表,进程链表把所有进程的描述符链接起来。每个task_struct结构都包含一个list_head类型的tasks字段,这个类型的 prev 和 next 字段分别指向前面和后面的 task_struct 元素。
进程链表的头是init_task描述符,它是所谓的0进程(process 0)或swapper进程的进程描述符(参见本章"内核线程"一节)。init_task的 tasks.prev字段指向链表中最后插入的进程描述符的 tasks字段。
SET_LINKS和REMOVE_LINKS宏分别用于从进程链表中插入和删除一个进程描述符。这些宏考虑了进程间的父子关系(见本章后面"如何组织进程"一节)。
还有一个很有用的宏就是for_each_process,它的功能是扫描整个进程链表,其定义如下∶
#define for_each_process(p)\
for(p=&init_task;(p=list_entry((p)->tasks.next,\
struct task_struct,tasks)\
)!=&init_task;)
这个宏是循环控制语句,内核开发者利用它提供循环。注意init_task进程描述符是如何起到链表头作用的。这个宏从指向 init_task的指针开始,把指针移到下一个任务,然后继续,直到又到init_task为止(感谢链表的循环性)。在每一次循环时,传递给这个宏的参变量中存放的是当前被扫描进程描述符的地址,这与list_entry宏的返回值一样。
7、TASK_RUNNING状态的进程链表
当内核寻找一个新进程在CPU上运行时,必须只考虑可运行进程(即处在TASK_RUNNING状态的进程)。
早先的Linux版本把所有的可运行进程都放在同一个叫做运行队列(runqueue)的链表中,由于维持链表中的进程按优先级排序开销过大,因此,早期的调度程序不得不为选择"最佳"可运行进程而扫描整个队列。
Linux 2.6实现的运行队列有所不同。其目的是让调度程序能在固定的时间内选出"最佳"可运行进程,与队列中可运行的进程数无关。我们仅在此提供一些基本信息,第七章会详细描述这种新的运行队列。
提高调度程序运行速度的诀窍是建立多个可运行进程链表,每种进程优先权对应一个不同的链表。每个task_struct描述符包含一个list__head类型的字段run_list。如果进程的优先权等于k(其取值范围是0到139),run_list字段把该进程链入优先权为k的可运行进程的链表中。此外,在多处理器系统中,每个CPU都有它自己的运行队列,即它自己的进程链表集。这是一个通过使数据结构更复杂来改善性能的典型例子∶调度程序的操作效率的确更高了,但运行队列的链表却为此而被拆分成140个不同的队列!
正如我们将看到的,内核必须为系统中每个运行队列保存大量的数据,不过运行队列的主要数据结构还是组成运行队列的进程描述符链表,所有这些链表都由一个单独的prio_array_t数据结构来实现,其字段说明如表3-2所示。

nqueue_task(p,array)函数把进程描述符插入某个运行队列的链表,其代码本质上等同于∶
list_add_tail(5p->run_list,&array->queue{p->prio]);
__set_bit(p->prio,array->bitmap);
array->nr_active++;
p->array = array;
进程描述符的prio字段存放进程的动态优先权,
而array字段是一个指针,指向当前运行队列的prio_array_t上数据结构。
类似地,dequeue_task(p,array)函数从运行队列的链表中删除一个进程的描述符。
8、进程间的关系
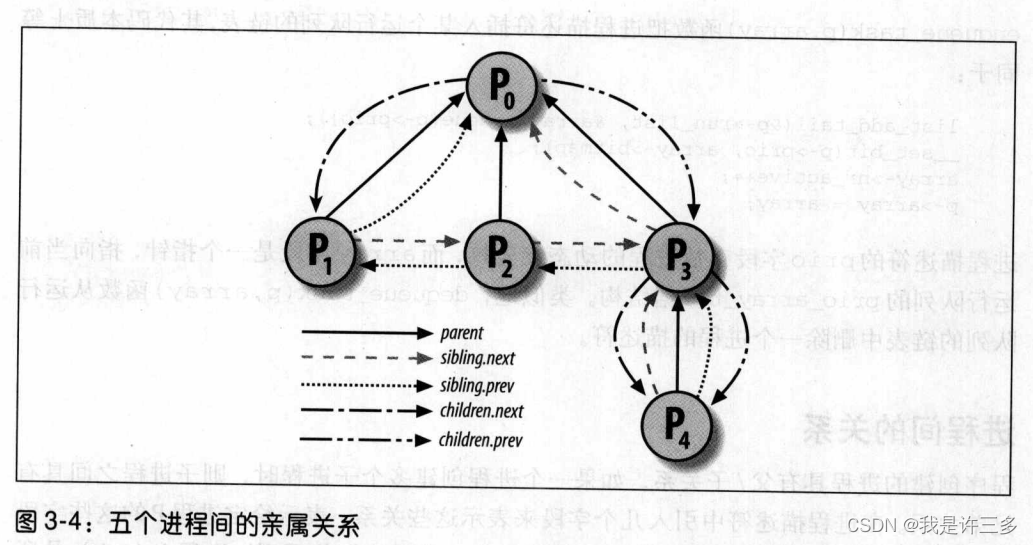
程序创建的进程具有父/子关系。如果一个进程创建多个子进程时,则子进程之间具有兄弟关系。在进程描述符中引入几个字段来表示这些关系,表示给定进程P的这些字段列在表3-3中。进程0和进程1是由内核创建的;稍后我们将看到,进程1(init)是所有进程的祖先。

图3-4显示了一组进程间的亲属关系。进程P0接连创建了P1,P2,和P3。进程P3又创建了P4。
特别要说明的是,进程之间还存在其他关系;一个进程可能是一个进程组或登录会话的领头进程(参见第一章"进程管理"一节),也可能是一个线程组的领头进程(参见本章前面"标识一个进程"一节),它还可能跟踪其他进程的执行(参见第二十章"执行跟踪"一节)。表3-4列出了进程描述符中的一些字段,这些字段建立起了进程P和其他进程之间的关系。

9、pidhash表及链表
在几种情况下,内核必须能从进程的PID导出对应的进程描述符指针。
例如,为kill()系统调用提供服务时就会发生这种情况∶
- 当进程P1希望向另一个进程P2发送一个信号时,
- P1调用kill()系统调用,其参数为P2的PID,内核从这个PID导出其对应的进程描述符,然后从P2的进程描述符中取出记录挂起信号的数据结构指针。
顺序扫描进程链表并检查进程描述符的pid字段是可行但相当低效的。为了加速查找,引入了4个散列表。需要4个散列表是因为进程描述符包含了表示不同类型PID的字段(见表3-5),而且每种类型的 PID需要它自己的散列表。

内核初始化期间动态地为4个散列表分配空间,并把它们的地址存入pid_hash数组。一个散列表的长度依赖于可用RAM的容量,例如:一个系统拥有512 MB 的RAM、那么每个散列表就被存在4个页框中,可以拥有2048个表项。
用pid_hashfn宏把 PID转化为表索引,pid_hashfn宏展开为∶
define pid_hashfn(x) hash_long((unsigned long)x,pidhash_shift)
变量 pidhash_shif 用来存放表索引的长度(以位为单位的长度,在我们的例子里是11位)。很多散列函数都使用hash_long(),在32位体系结构中它基本等价于∶
unsigned long hash_long(unsigned long val,unsigned int bits)
{
unsigned long hash = val* 0×9e370001UL;
return hash S >> (32-bits);
}
因为在我们的例子中 pidhash_shift等于11,所以pid_hashfn的取值范围是0到211-1=2047。
正如计算机科学的基础课程所阐述的那样,散列(hash)函数并不总能确保PID与表的索引一一对应。两个不同的PID 散列(hash)到相同的表索引称为冲突(colliding)。
魔数常量
也许你会想常量0x9e370001(=2654 404 609)究竟是怎么得出的。这种散列函数是基于表索引乘以一个适当的大数,于是结果溢出,就把留在32位变量中的值作为模数操作的结果。Knuth建议,要得到满意的结果,这个大柬数就应当是接近黄金比例的2"的一个素数(32位是80x86寄存器的大小)。这里,2654 404 609就是接近22×(√5-1)/2的一个素数,这个数可以方便地通过加运算和位移运算得到,因为它等于∶ 2’+29-25+2-219-216+1。
Linux利用链表来处理冲突的PID;每一个表项是由冲突的进程描述符组成的双向链表。图3-5显示了具有两个链表的PID散列表。进程号(PID)为2890和29384的两个进程散列到这个表的第 200个元素,而进程号(PID)为29385的进程散列到这个表的第1466个元素。
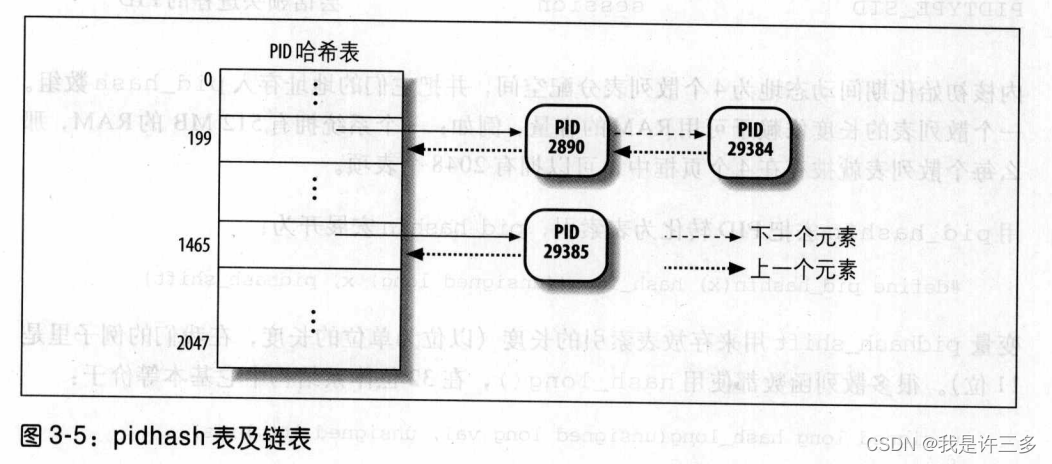
具有链表的散列法比从PID到表索引的线性转换更优越,这是因为在任何给定的实例中,系统中的进程数总是远远小于32768(所允许的进程PID的最大数)。如果在任何给定的实例中大部分表项都不使用的话,那么把表定义为32768项会是一种存储浪费。
由于需要跟踪进程间的关系,PID散列表中使用的数据结构非常复杂。看一个例子∶假设内核必须回收一个指定线程组中的所有进程,这意味着这些进程的tgid的值是相同的,都等于一个给定值。如果根据线程组号查找散列表,只能返回一个进程描述符,就是线程组领头进程的描述符。为了能快速返回组中其他所有进程,内核就必须为每个线程组保留一个进程链表。在查找给定登录会话或进程组的进程时也会有同样的情形。
PID散列表的数据结构解决了所有这些难题,因为它们可以为包含在一个散列表中的任何PID号定义进程链表。最主要的数据结构是四个pid结构的数组,它在进程描述符的pid字段中,表3-6显示了 pid结构的字段。

根据pid结构做下图

图3-6给出了PIDTYPE_TGID类型散列表的例子。pid_hash数组的第二个元素存放散列表的地址,也就是用hlist_head结构的数组表示链表的头。在散列表第71项为起点形成的链表中,有两个PID号为246 和 4351的进程描述符(双箭头线表示一对向前和向后的指针)。PID的值存放在pid结构的nr字段中,而pid结构在进程描述符中。(顺便提一下,由于线程组的号和它的首创者的PID相同,因此这些PID值也存在进程描述符的pid字段中。)我们考虑线程组4351的 PID 链表∶散列表中的进程描述符的pid_list字段中存放链表的头,同时每个PID链表中指向前一个元素和后一个元素的指针也存放在每个链表元素的pid_list 字段中。
下列函数和宏中的参数:type:用于指定是4个散列表中的哪个。nr:进程标识符 task:进程描述符
下面是处理PID散列表的函数和宏∶
-
do_each_task_pid(nr, type, task)
-
while_each_task_pid(nr,type, task)
标记do-while 循环的开始和结束,循环作用在PID进程标识符值等于nr的PID进程标识符的链表上,链表的类型由参数type 给出,task 参数指向当前被扫描的元素的进程描述符。
(个人认为:在type指定的散列表中查找,标识符为nr的进程,将它的进程描述符写入task) -
find_task_by_pid_type(type,nr)
在 type 类型的散列表中查找PID等于nr的进程。该函数返回所匹配的进程描述符指针,若没有匹配的进程,函数返回NULL。 -
find_task_by_pid(nr)
与find_task_by_pid_type(PIDTYPE_PID,nr)相同。 -
attach_pid(task,type,nr)
把task指向的PID等于nr的进程描述符插入type类型的散列表中。如果一个PID等于nr的进程描述符已经在散列表中,这个函数就只把task插入已有的PID进程链表中。 -
detach_pid(task,type)
从type类型的PID进程链表中删除task 所指向的进程描述符。如果删除后PID进程链表没有变为空,则函数终止,否则,该函数还要从type类型的散列表中删除进程描述符。最后,如果PID的值没有出现在任何其他的散列表中,为了这个值能够被反复使用,该函数还必须清除 PID位图中的相应位。 -
next_thread(task)
返回PIDTYPE_TGID类型的散列表链表中task指示的下一个轻量级进程的进程描述符。由于散列链表是循环的,若应用于传统的进程,那么该宏返回进程本身的描述符地址
10、如何组织进程
运行队列链表把处于TASK_RUNNING状态的所有进程组织在一起。当要把其他状态的进程分组时,不同的状态要求不同的处理,Linux 选择了下列方式之一∶
- 没有为处于TASK_STOPPED、EXIT_ZOMBIE或EXIT_DEAD状态的进程建立专门的链表。由于对处于暂停、僵死、死亡状态进程的访问比较简单,或者通过PID,或者通过特定父进程的子进程链表,所以不必对这三种状态进程分组。
1)等待队列
等待队列在内核中有很多用途,尤其用在中断处理、进程同步及定时。因为这些主题将在以后的章节中讨论,所以我们只在这里说明,进程必须经常等待某些事件的发生,例如,等待一个磁盘操作的终止,等待释放系统资源,或等待时间经过固定的间隔。等待队列实现了在事件上的条件等待:希望等待特定事件的进程把自己放进合适的等待队列,并放弃控制权。因此,等待队列表示一组睡眠的进程,当某一条件变为真时,由内核唤醒它们。
等待队列由双向链表实现,其元素包括指向进程描述符的指针。每个等待队列都有一个等待队列头(wait queue head),等待队列头是一个类型为wait_queue_head_t的数据结构∶
struct __wait_queue_head{
spinlock_t lock;
struct 1ist_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
因为等待队列是由中断处理程序和主要内核函数修改的,因此必须对其双向链表进行保护以免对其进行同时访问,因为同时访问会导致不可预测的后果(参见第五章)。同步是通过等待队列头中的lock 自旋锁达到的。task_1ist字段是等待进程链表的头。
等待队列链表中的元素类型为wait_queue_t∶
struct __wait_queue{
unsigned int flags;
struct task_struct * task;
wait_queue_func_t func;
struct list_head task_list;
};
typedef struct __wait_queue wait_queue_t;
等待队列链表中的每个元素代表一个睡眠进程,该进程等待某一事件的发生;它的描述符地址存放在task字段中。task_list字段中包含的是指针,由这个指针把一个元素链接到等待相同事件的进程链表中。
然而,要唤醒等待队列中所有睡眠的进程有时并不方便。例如,如果两个或多个进程正在等待互斥访问某一要释放的资源,仅唤醒等待队列中的一个进程才有意义。这个进程占有资源,而其他进程继续睡眠。(这就避免了所谓"雷鸣般兽群"问题,即唤醒多个进程只为了竞争一个资源,而这个资源只能有一个进程访问,结果是其他进程必须再次回去睡眠。)
因此,有两种睡眠进程∶互斥进程(等待队列元素的flags字段为1)由内核有选择地唤醒,而非互斥进程(falgs值为0)总是由内核在事件发生时唤醒。等待访问临界资源的进程就是互斥进程的典型例子。等待相关事件的进程是非互斥的。例如,我们考虑等待磁盘传输结束的一组进程∶一但磁盘传输完成,所有等待的进程都会被唤醒。正如我们将在下面所看到的那样,等待队列元素的func字段用来表示等待队列中睡眠进程应该用什么方式唤醒。
2)等待队列的操作
可以用DECLARE_WAIT_QUEUE_HEAD(name)宏定义一个新等待队列的头,它静态地声明一个叫name的等待队列的头变量并对该变量的lock和task_list字段进行初始化。函数 init_waitqueue_head()可以用来初始化动态分配的等待队列的头变量。
函数init_waitqueue_entry(q,p )如下所示初始化wait_queue_t 结构的变量 q∶
q->flags = 0;
q->task = p;
q->func = default_wake_function; //default默认
非互斥进程p将由default_wake_function()唤醒,default_wake_function()是在第七章中要讨论的 try_to_wake_up()函数的一个简单的封装。
也可以选择DEFINE_WAIT宏声明一个wait_queue_t类型的新变量,并用CPU上运行的当前进程的描述符和唤醒函数autoremove_wake_function()的地址初始化这个新变量。这个函数调用默认唤醒函数default_wake_function()来唤醒睡眠进程,然后从等待队列的链表中删除对应的元素(每个等待队列链表中的一个元素其实就是指向睡眠进程描述符的指针)。最后,内核开发者可以通过init_waitqueue_func_entry()函数来自定义唤醒函数,该函数负责初始化等待队列的元素。
一但定义了一个元素,必须把它插入等待队列。
add_wait_queue() //函数把一个非互斥进程插入等待队列链表的第一个位置。
add_wait_queue_exclusive() //函数把一个互斥进程插入等待队列链表的最后一个位置。
remove_wait_gueue() //函数从等待队列链表中删除一个进程。
waitqueue_active() //函数检查一个给定的等待队列是否为空。
要等待特定条件的进程可以调用如下列表中的任何一个函数。
- sleep_on()对当前进程进行操作∶
void sleep_on(wait_queue_head_t *wq)
{
wait_queue_t wait;
init_waitqueue_entry(&wait,current); /*初始化wait_queue_t结构的变量wait*/
current->state = TASK_UNINTERRUPTIBLE; /*设置当前进程的状态为不可中断的等待状态*/
add_wait_queue(wq,&wait); /*wq指向当前队列的头*/
schedule(); /*主动调度*/
remove_wait_queue(wq,&wait);
}
该函数把当前进程的状态设置为TASK_UNINTERRUPTIBLE,并把它插入到特定的等待队列。
然后,它调用调度程序,而调度程序重新开始另一个程序的执行。
当睡眠进程被唤醒时,调度程序重新开始执行sleep_on()函数,把该进程从等待队列中删除。
-
interruptible_sleep_on()与sleep_on()函数是一样的,但稍有不同,前者把当前进程的状态设置为TASK_INTERUPTIELE而不是TASK_UNINTERRUPTIEBLE,因此,接受一个信号就可以唤醒当前进程。
-
sleep_on_timeout()和interruptible_sleep_on_timeout()与前面函数类似,但它们允许调用者定义一个时间间隔,过了这个间隔以后,进程将由内核唤醒。为了做到这点,它们调用schedule_timeout()函数而不是 schedule()函数(参见第六章中"动态定时器的应用"一节)。
-
在Linux 2.6中引入的prepare_to_wait()、prepare_to_wait_exclusive()和finish_wait()函数提供了另外一种途径来使当前进程在一个等待队列中睡眠。它们的典型应用如下(prepare v.准备 exclusive adj.独占的)∶

函数prepare_to_wait()和prepare_to_wai_exclusive()用传递的第三个参数设置进程的状态,然后把等待队列元素的互斥标志flag 分别设置为0(非互斥)或1(互斥),最后,把等待元素wait插入到以wq为头的等待队列的链表中。进程一但被唤醒就执行finishwait()函数,它把进程的状态再次设置为TASK_RUNNINCG(仅发生在调用schedule()之前,唤醒条件变为真的情况下),并从等待队列中删除等待元素(除非这个工作已经由唤醒函数完成)。 -
wait_event和wait_event_interruptible宏使它们的调用进程在等待队列上睡眠,一直到修改了给定条件为止。例如,宏wait_event(wg,condition)本质上实现下面的功能∶

对上面列出的函数做一些说明;sleep_on()类函数在以下条件下不能使用,那就是必须测试条件并且当条件还没有得到验证时又紧接着让进程去睡眠;由于那些条件是众所周知的竞争条件产生的根源,所以不鼓励这样使用。此外,为了把一个互斥进程插入等待队列,内核必须使用prepare_to_wait_exclusive()函数 [或者只是直接调用add_wait_queue_exclusive() ]。所有其他的相关函数把进程当作非互斥进程来插入。
最后,除非使用DEFINE_WAIT 或finish_wait(),否则内核必须在唤醒等待进程后从等待队列中删除对应的等待队列元素。
内核通过下面的任何一个宏唤醒等待队列中的进程并把它们的状态置为TASK_RUNING∶
wake_up,wake_up_nr,wake_up__alL,wake_up_interruptible,wake_up_interruptible_nr,wake_up_interruptible_all,wake_up_interruptible_sync和wake_up_locked。从每个宏的名字我们可以明白其功能∶
-
所有宏都考虑到处于TASK_INTERRUPTIBLE状态的睡眠进程;如果宏的名字中不含字符串"interruptible",那么处于TASK_UNINTERRUPTIBLE状态的睡眠进程也被考虑到。
-
所有宏都唤醒具有请求状态的所有非互斥进程(参见上一项)。
-
名字中含有"nr"字符串的宏唤醒给定数的具有请求状态的互斥进程;这个数字是宏的一个参数。名字中含有"all"字符串的宏唤醒具有请求状态的所有互斥进程。最后,名字中不含"nr"或"all"字符串的宏只唤醒具有请求状态的一个互斥进程。
-
名字中不含有"sync"字符串的宏检查被唤醒进程的优先级是否高于系统中正在运行进程的优先级,并在必要时调用schedule()。这些检查并不是由名字中含有"sync"字符串的宏进行的,造成的结果是高优先级进程的执行稍有延迟。
-
wake_up_locked宏和wake_up宏相类似,仅有的不同是当wait_queue_head_t中的自旋锁已经被持有时要调用 wake_up_locked。
例如,wake_up 宏等价于下列代码片段∶
/*默认唤醒函数:int default_wake_function(wait_queue_t *curr, unsigned mode, int sync, void *key)*/
void wake_up(wait_queue_head_t *q)
{
struct list_head *tmp;
wait_queue_t *curr;
list_for_each(tmp, &q->task_list){
curr=list_entry(tmp,wait_queue_t,task_list);
/*如果一个进程已经被有效地唤醒(函数返回1)并且进程是互斥的(curr->flags等于1),循环结束。*/
if(curr->func(curr,TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE,0,NULL) && curr->flags)
break;
}
}
list_for_each宏扫描双向链表q->task_list中的所有项,即等待队列中的所有进程。
对每一项,list_entry宏都计算wai_queue_t变量对应的地址。
这个变量的func 字段存放唤醒函数的地址,它试图唤醒由等待队列元素的task字段标识的进程。
如果一个进程已经被有效地唤醒(函数返回1)并且进程是互斥的(curr->flags等于1),循环结束。
因为所有的非互斥进程总是在双向链表的开始位置,而所有的互斥进程在双向链表的尾部,所以函数总是先唤醒非互斥进程然后再唤醒互斥进程,如果有进程存在的话(注4)。
注4∶ 顺便提一下,一个等待队列中同时包含互斥进程和非互斥进程的情况是非常罕见的。
11、进程资源限制
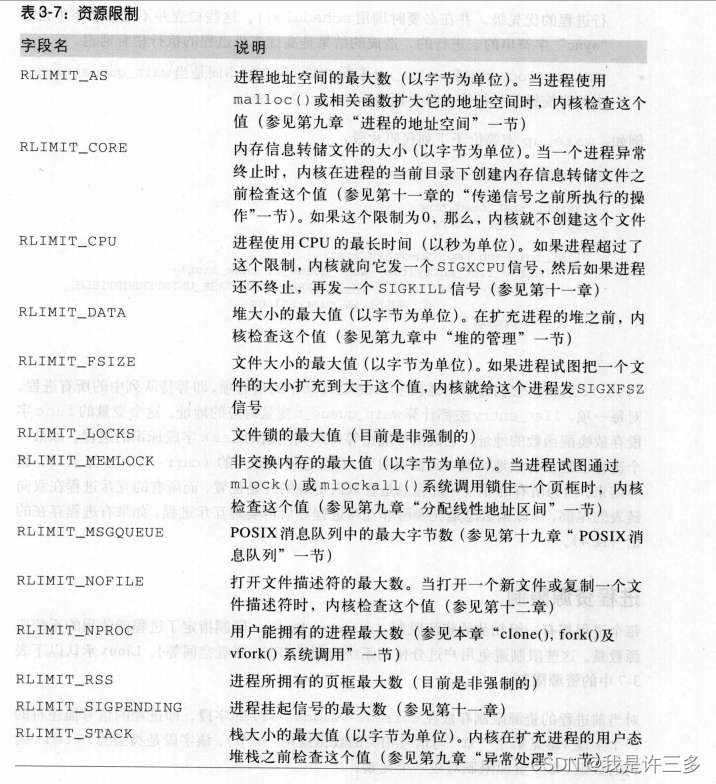
每个进程都有一组相关的资源限制(resource limit),限制指定了进程能使用的系统资源数量。这些限制避免用户过分使用系统资源(CPU、磁盘空间等)。Linux承认以下表3-7中的资源限制。
对当前进程的资源限制存放在 current->signal->rlim字段,即进程的信号描述符的一个字段(参见第十一章"与信号相关的数据结构"一节)。该字段是类型为rlimit结构的数组,每个资源限制对应一个元素∶
struct rlimit{
unsigned long rlim_cur;
unsigned long rlim_max;
}
rlim_cur字段是资源的当前资源限制。例如,current->signal->rlim[RLIMIT_CPU].rlim_cur表示正运行进程所占用CPU时间的当前限制。
rlim_max字段是资源限制所允许的最大值。利用getrlimit()和 setrlimit()系统调用,用户总能把一些资源的rlim_cur限制增加到rlim_max。然而,只有超级用户(或更确切地说,具有CAP_SYS_RESOURCE权能的用户)才能改变rlim_max字段,或把rlim_cur 字段设置成大于相应rlim_max字段的一个值。
大多数资源限制包含值 RLIMIT_INFINITY(0xffffffff),它意味着没有对相应的资源施加用户限制(当然,由于内核设计上的限制,可用RAM、可用磁盘空间等,实际的限制还是存在的)。然而,系统管理员可以给一些资源选择施加更强的限制。只要用户注册进系统,内核就创建一个由超级用户拥有的进程,超级用户能调用setrlimit()以减少一个资源rlim_max和rlim__cur字段的值。随后,同一进程执行一个login shell,该进程就变为由用户拥有。由用户创建的每个新进程都继承其父进程rlim数组的内容,因此,用户不能忽略系统强加的限制。
三、进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换(process switch)、任务切换(task switch)或上下文切换(context switch)。下面几节描述在Linux中进行进程切换的主要内容。
1、硬件上下文
尽管每个进程可以拥有属于自己的地址空间,但所有进程必须共享CPU寄存器。因此,在恢复一个进程的执行之前,内核必须确保每个寄存器装入了挂起进程时的值。
进程恢复执行前必须装入寄存器的一组数据称为硬件上下文(hardware context)。硬件上下文是进程可执行上下文的一个子集,因为可执行上下文包含进程执行时需要的所有信息。在Linux中,进程硬件上下文的一部分存放在TSS段,而剩余部分存放在内核态堆栈中。
在下面的描述中,我们假定用prev局部变量表示切换出的进程的描述符,next表示切换进的进程的描述符。因此,我们把进程切换定义为这样的行为∶保存prev硬件上下文,用next硬件上下文代替prev。因为进程切换经常发生,因此减少保存和装入硬件上下文所花费的时间是非常重要的。
早期的Linux版本利用80x86体系结构所提供的硬件支持,并通过 far jmp 指令(注5)跳到next 进程TSS描述符的选择符来执行进程切换。当执行这条指令时,CPU通过自动保存原来的硬件上下文,装入新的硬件上下文来执行硬件上下文切换。但基于以下原因,Linux 2.6使用软件执行进程切换∶
-
通过一组mov指令逐步执行切换,这样能较好地控制所装入数据的合法性。尤其是,这使检查ds和es段寄存器的值成为可能,这些值有可能被恶意用户伪造。当用单独的 far jmp 指令时,不可能进行这类检查。
-
旧方法和新方法所需时间大致相同。然而,尽管当前的切换代码还有改进的余地,却不能对硬件上下文切换进行优化。
进程切换只发生在内核态。在执行进程切换之前,用户态进程使用的所有寄存器内容都已保存在内核态堆栈上(参见第四章),这也包括ss和esp这对寄存器的内容(存储用户态堆栈指针的地址)。
注5∶ far jmp指令既修改cs寄存器,也修改eip寄存器,而简单的jmp指令只修改eip寄存器。
2、任务状态段
80x86 体系结构包括了一个特殊的段类型,叫任务状态段(Task State Segment,TSS)来存放硬件上下文。尽管Linux并不使用硬件上下文切换,但是强制它为系统中每个不同的 CPU 创建一个TSS。这样做的两个主要理由为∶
-
当80x86的一个CPU从用户态切换到内核态时,它就从TSS中获取内核态堆栈的地址(参见第四章"中断和异常的硬件处理"一节和第十章"通过sysenter指令发送系统调用"一节)。
-
当用户态进程试图通过in或out指令访问一个I/O端口时,CPU需要访问存放在TSS中的I/O许可权位图(Permission Bitmap)以检查该进程是否有访问端口的权力。更确切地说,当进程在用户态下执行in或out指令时,控制单元执行下列操作∶
1.它检查eflags寄存器中的2位IOPL字段。如果该字段值为3,控制单元就执行I/O指令。否则,执行下一个检查。
2.访问tr寄存器以确定当前的TSS和相应的I/O 许可权位图。
3.检查I/O指令中指定的I/O端口在I/O许可权位图中对应的位。如果该位清0,这条 I/O指令就执行,否则控制单元产生一个"General protection"异常。
tss_struct结构描述TSS的格式。正如第二章所提到的,init_tss数组为系统上每个不同的CPU存放一个TSS。在每次进程切换时,内核都更新TSS的某些字段以便相应的CPU控制单元可以安全地检索到它需要的信息。因此,TSS反映了CPU上的当前进程的特权级,但不必为没有在运行的进程保留TSS。
每个TSS有它自己8字节的任务状态段描述符(Task State Segment Descriptor,TSSD)。这个描述符包括指向TSS起始地址的32位Base字段,20位Limit字段。TSSD的S标志位被清0,以表示相应的TSS是系统段的事实(参见第二章"段描述符"一节)。
Type字段置为11或9以表示这个段实际上是一个TSS。在Intel的原始设计中,系统中的每个进程都应当指向自己的TSS;Type字段的第二个有效位叫做Busy位;如果进程正由CPU执行,则该位置1,否则置0。在Linux的设计中,每个CPU只有一个TSS,因此,Busy 位总置为1。
由Linux 创建的TSSD存放在全局描述符表(GDT)中,GDT的基地址存放在每个CPU的gdtr寄存器中。每个CPU的tr寄存器包含相应TSS的TSSD选择符,也包含了两个隐藏的非编程字段∶TSSD的Base字段和Limi字段。这样,处理器就能直接对TSS寻址而不用从GDT中检索TSS的地址。
thread 字段
在每次进程切换时,被替换进程的硬件上下文必须保存在别处。不能像Intel原始设计那样把它保存在TSS中,因为Linux 为每个处理器而不是为每个进程使用TSS。
因此,每个进程描述符包含一个类型为 thread_struct的thread字段,只要进程被切换出去,内核就把其硬件上下文保存在这个结构中。随后我们会看到,这个数据结构包含的字段涉及大部分CPU寄存器,但不包括诸如eax、 ebx等等这些通用寄存器,它们的值保留在内核堆栈中。
3、执行进程切换
进程切换可能只发生在精心定义的点;schedule()函数(在第七章会用很长的篇幅来讨论)。这里,我们仅关注内核如何执行一个进程切换。
从本质上说,每个进程切换由两步组成∶
- 切换页全局目录以安装一个新的地址空间,我们将在第九章描述这一步。
- 切换内核态堆栈和硬件上下文,因为硬件上下文提供了内核执行新进程所需要的所有信息,包含CPU寄存器。
我们又一次假定prev指向被替换进程的描述符,而 next 指向被激活进程的描述符。我们在第七章会看到,prev 和next是 schedule()函数的局部变量。
1)switch_to宏
进程切换的第二步由switch_to宏执行。它是内核中与硬件关系最密切的例程之一,要理解它到底做了些什么我们必须下些功夫。
首先,该宏有三个参数,它们是prev,next和last。你可能很容易猜到prev和next的作用∶它们仅是局部变量prev和next的占位符,即它们是输入参数,分别表示被替换进程和新进程描述符的地址在内存中的位置。
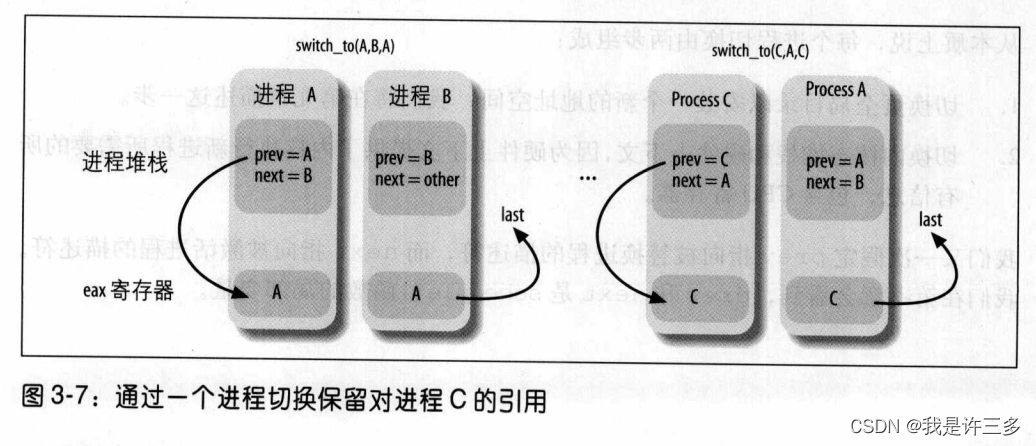
那第三个参数last呢?在任何进程切换中,涉及到三个进程而不是两个。假设内核决定暂停进程A而激活进程 B。在schedule()函数中,prev指向A的描述符而next指向B的描述符。switch_to宏一但使A暂停,A的执行流就冻结。
随后,当内核想再次此激活A,就必须暂停另一个进程C(这通常不同于B),于是就要用prev指向C而next指向A来执行另一个switch__to宏。当A恢复它的执行流时,就会找到它原来的内核栈,于是prev局部变量还是指向 A的描述符而next指向 B的描述符。此时,代表进程A执行的内核就失去了对C的任何引用。但是,事实表明这个引用对于完成进程切换是很有用的(更多细节参见第七章)。
switch_to宏的最后一个参数是输出参数,它表示宏把进程C的描述符地址写在内存的什么位置了(当然,这是在A恢复执行之后完成的)。在进程切换之前,宏把第一个输入参数prey(即在A的内核堆栈中分配的prev局部变量)表示的变量的内容存入CPU的eax寄存器。在完成进程切换,A 已经恢复执行时,宏把CPU的eax寄存器的内容写入由第三个输出参数——last 所指示的A在内存中的位置。因为CPU寄存器不会在切换点发生变化,所以C的描述符地址也存在内存的这个位置。在 schedule()执行过程中,参数last指向A的局部变量 prev,所以prev 被C的地址覆盖。
图 3-7显示了进程A,B,C内核堆栈的内容以及 eax 寄存器的内容。必须注意的是∶图中显示的是在被 eax寄存器的内容覆盖以前的 prev 局部变量的值。
由于switch_to宏采用扩展的内联汇编语言编码,所以可读性比较差;实际上这段代码通过特殊位置记数法使用寄存器,而实际使用的通用寄存器由编译器自由选择。我们将采用标准汇编语言而不是麻烦的内联汇编语言来描述switch_to宏在80x86微处理器上所完成的典型工作。
-
1.在 eax和edx寄存器中分别保存prev 和next的值∶
movl prev,%eax
movl next,%edx -
2.把eflags和ebp寄存器的内容保存在prev内核栈中。必须保存它们的原因是编译器认为在 switch_to 结束之前它们的值应当保持不变。
puahf1
pushl %ebp -
3.把esp的内容保存到prev->thread.esp中以使该字段指向prev 内核栈的栈顶∶
mov1 tesp,484(%eax)
484(号eax)操作数表示内存单元的地址为eax内容加上484。 -
4.把next->thread.esp装入esp。此时,内核开始在next的内核栈上操作,因此这条指令实际上完成了从prev到next的切换。由于进程描述符的地址和内核栈的地址紧挨着(就像我们在本章前面"标识一个进程"一节所解释的),所以改变内核栈意味着改变当前进程。
mov1 484(edx),%esp -
5.把标记为1的地址(本节后面所示)存入prev->thread.eip。当被替换的进程重新恢复执行时,进程执行被标记为1的那条指令;
mov1 $1f,480(%eax) -
6.宏把next->thread.eip的值(绝大多数情况下是一个被标记为1的地址)压入next的内核栈∶
push1 480(%edx) -
7.跳到__switch__to()C函数(见下面)∶
jmp___switch_to -
8.这里被进程B替换的进程A再次获得CPU;它执行一些保存eflags和ebp寄存器内容的指令,这两条指令的第一条指令被标记为1。
1:
popl ebp
popfl
注意这些pop 指令是怎样引用 prev 进程的内核栈的。当进程调度程序选择了prev作为新进程在CPU上运行时,将执行这些指令。于是,以prev作为第二个参数调用 switch_to。因此,esp寄存器指向 prev 的内核栈。 -
9.拷贝eax寄存器(上面步骤1中被装载)的内容到switch_to宏的第三个参数last标识的内存区域中∶
mov1 %eax,last
正如先前讨论的,eax 寄存器指向刚被替换的进程的描述符(注6)。
2)_switch_to()函数
__switch_to()函数执行大多数开始于switch_to()宏的进程切换。这个函数作用于prev_p和next_p参数,这两个参数表示前一个进程和新进程。这个函数的调用不同于一般函数的调用,因为__switch_to()从eax和edx取参数prev_p和next_p(我们在前面已看到这些参数就是保存在那里),而不像大多数函数一样从栈中取参数。为了强迫函数从寄存器取它的参数,内核利用__attribute__和regparm关键字,这两个关键字是C语言非标准的扩展名,由gcc 编译程序实现。在include /asm-i386/system.h头文件中,__switch_to()函数的声明如下∶
__switch_to(struct task_struct *prev_p,struct task_struct *next_p)
__attribute__ (regparm(3));
函数执行的步骤如下∶
-
1.执行由__unlazy_fpu()宏产生的代码(参见本章稍后"保存和加载FPU、MMX及XMM寄存器"一节),以有选择地保存prev_p进程的FPU、MMX及XMM寄存器的内容。
__unlazy_fpu(prev_D)); -
2.执行smp_processor_id()宏获得本地(local)CPU/的下标,即执行代码的CPU。该宏从当前进程的thread_info结构的cpu字段获得下标并将它保存到cpu局部变量。
-
- 把next_p-thread.esp0装入对应于本地CPU的TSS的esp0字段;我们将在第十章的"通过 sysenter指令发生系统调用"一节看到,以后任何由sysenter 汇编指令产生的从用户态到内核态的特权级转换将把这个地址拷贝到esp寄存器中∶
init_tss[cpu].esp0= next_p->thread.esp0;
注6∶ 正如本节前面所叙述的,当前执行的schedule()函数重新使用了prev局部变量,于是汇编语言指令就是∶movl 笔eax,prev。
- 把next_p-thread.esp0装入对应于本地CPU的TSS的esp0字段;我们将在第十章的"通过 sysenter指令发生系统调用"一节看到,以后任何由sysenter 汇编指令产生的从用户态到内核态的特权级转换将把这个地址拷贝到esp寄存器中∶
-
- 把next_p进程使用的线程局部存储(TLS)段装入本地CPU的全局描述符表;三个段选择符保存在进程描述符内的tls_array数组中(参见第二章的"Linux中的分段"一节)。
cpu_gdt_table[cpu][6]= next_p->thread.tls_array[0];
cpu_gdt_table[cpu][7]= next_p->thread.tls_array[1];
cpu_gdt_table[cpu][8]= next_p->thread.tl8_array[2];
- 把next_p进程使用的线程局部存储(TLS)段装入本地CPU的全局描述符表;三个段选择符保存在进程描述符内的tls_array数组中(参见第二章的"Linux中的分段"一节)。
-
5.把fs和gs段寄存器的内容分别存放在prev-P->thread.fs和prev-P->thread.gs
中,对应的汇编语言指令是;
movl f8,40('esi)
mov1 电gs,44{$eai)
esi寄存器指向 prev_p->thread结构。 -
- 如果fs或gs段寄存器已经被prev_p或next_p进程中的任意一个使用(也就
是说如果它们有一个非0的值),则将next_p进程的 thread_struct描述符中保
存的值装入这些寄存器中。这一步在逻辑上补充了前一步中执行的操作。主要的汇
编语言指令如下∶
mov1 40(名ebx》,常fs
mov】 44(笔ebx>,gs
ebx寄存器指向next_p->thread结构。代码实际上更复杂,因为当它检测到一个
无效的段寄存器值时,CPU可能产生一个异常。代码采用一种"修正(fix-up)"途
径来考虑这种可能性(参见第十章"动态地址检查∶修正代码"一节)。
- 如果fs或gs段寄存器已经被prev_p或next_p进程中的任意一个使用(也就
-
- 用next_p->thread.debugreg数组的内容装载dr0,…,dr7中的6个调试寄存
器(注7)。只有在next_p被挂起时正在使用调试寄存器(也就是说,next_p
->thread.debugreg【7】字段不为0),这种操作才能进行。这些寄存器不需要被保
存,因为只有当一个调试器想要监控prev时 prev_p->thread.debugreg才会被
修改。
if(next_p->thread.debugreg [7]){
loaddebug(8next_p->thread,0);
loaddebug(反next_p->thread,1);
1oaddebug(&next_p->thread,2);
1oaddebug(Enext_p->thread,3);
/* 没有生和5*/
loaddebug(Enext_p->thread,6);
一 loaddebug(&next_p->thread,7);
注7∶ 80×86调试寄存器允许进程被硬件监拉。最多可定义4个断点区域。一个被监控的进程
只要产生的一个线性地址位于个断点区城中之一,就会产生一个异常。114 第三章
- 用next_p->thread.debugreg数组的内容装载dr0,…,dr7中的6个调试寄存
-
- 如果必要,更新TSS中的I/O位图。当next_p或prev_p有其自己的定制I/O权限
位图时必须这么做∶
if(prev_p->thread.io_bitmap_ptrI next_p->thread.io_bitmap_ptr}
handle_io_bitmap(Enext_p->thread,&init_tss[cpu]);
因为进程很少修改I/O权限位图,所以该位图在"懒"模式中被处理∶当且仅当一
个进程在当前时间片内实际访问I/O端口时,真实位图才被拷贝到本地CPU的TSS
中。进程的定制I/O权限位图被保存在 thread_info结构的io_bitmap_ptr字段
指向的缓冲区中。handle_io_bitmap()函数为next_p 进程设置本地 CPU 使用
的TSS的io_bitmap字段如下∶
·如果next_p进程不拥有自己的I/O权限位图,则TSS的io_bitmap字段被设
为0x8000。
如果next_p进程拥有自己的I/O权限位图,则TSS的io_bitmap字段被设为
0×9000。
TSS的 io_bitmap字段应当包含一个在TSS中的偏移量,其中存放实际位图。无论何
时用户态进程试图访问一个I/O端口,0x8000和0x9000指向TSS界限之外并将因此
引起"General protection"异常(参见第四章的"异常"一节)。do_general_protection()
异常处理程序将检查保存在io_bitmap 字段的值∶如果是 0x8000,函数发送一个
SIGSEGV信号给用户态进程;如果是0x9000,函数把进程位图(由 thread_info结
构中的io_bitmap_ptr字段指示)拷贝到本地CPU的TSS中,把io_bitmap字段设
为实际位图的偏移(104),并强制再一次执行有缺陷的汇编语言指令。
- 如果必要,更新TSS中的I/O位图。当next_p或prev_p有其自己的定制I/O权限
-
- 终止。_switch_to()C 函数通过使用下列声明结束;
return prev_D;
由编译器产生的相应汇编语言指令是∶
mov1 号edi,eax
ret
prev_p 参数(现在在edi中)被拷贝到 eax,因为缺省情况下任何C函数的返
回值被传递给eax寄存器。注意eax的值因此在调用__switch_to()的过程中被
保护起来;这非常重要,因为调用 switch_to宏时会假定eax总是用来存放将被
替换的进程描述符的地址。
汇编语言指令ret把栈顶保存的返回地址装入eip程序计数器。不过,通过简单地
跳转到__switch_to《)函数来调用该函数。因此,ret汇编指令在栈中找到标号为
1的指令的地址,其中标号为1的地址是由switch_to()宏推入栈中的。如果因为进程 115
next_p第一次执行而以前从未被挂起,_switch_to()就找到ret_from_fork()
函数的起始地址(参见本章后面"clone()),fork())和vfork()系统调用一节")。
- 终止。_switch_to()C 函数通过使用下列声明结束;
4、保存和加载 FPU、MMX及 XMM寄存器
从Intel 80486DX开始,算术浮点单元(floating-point unit,FPU)已被集成到CPU中。数学协处理这个名词使人想起使用昂贵的专用芯片执行浮点计算的岁月。然而,为了维持与旧模式的兼容,浮点算术函数用ESCAPE指令来执行,这个指令的一些前缀字节在0xd8 和0xdf 之间。这些指令作用于包含在CPU中的浮点寄存器集。显然,如果一个进程正在使用ESCAPE指令,那么,浮点寄存器的内容就属于它的硬件上下文,并且应该被保存。
在最近的Pentium模型中,Intel在它的微处理器中引入一个新的汇编指令集,叫做MMX指令,用来加速多媒体应用程序的执行。MMX指令作用于FPU的浮点寄存器。选择这种体系结构的明显缺点是编程者不能把浮点指令与MMX指令混在一起使用。优点是操作系统设计者能忽视新指令集,因为保存浮点单元状态的任务切换代码可以不加修改地应用到保存MMX状态。
MMX指令加速了多媒体应用程序的执行,因为它们在处理器内部引入了单指令多数据(single-instruction multiple-data,SIMD)流水线。Pentium Ⅱ模型扩展了这种 SIMD能力∶它引入SSE扩展(Streaming SIMD Extensions),该扩展为处理包含在8个128位寄存器(叫做XMM寄存器)的浮点值增加了功能。这样的寄存器不与FPU和MMX寄存器重叠,因此 SSE和FPU/MMX指令可以随意地混合。Pentium 4模型指令还引入另一种特点∶SSE2扩展,该扩展基本上是SSE的一个扩展,支持高精度浮点值。SSE2与SSE 使用同一XMM寄存器集。
80x86微处理器并不在TSS中自动保存FPU、MMX和 XMM寄存器。不过,它们包含某种硬件支持,能在需要时保存这些寄存器的值。硬件支持由cr0寄存器中的一个TS(Task-Switching)标志组成遵循以下规则∶
- 每当执行硬件上下文切换时,设置TS标志。
- 每当TS标志被设置时执行ESCAPE、MMX、SSE或SSE2指令,控制单元就产生一个"Device not available"异常(参见第四章)。
TS标志使得内核只有在真正需要时才保存和恢复FPU、MMX和 XMM寄存器。为了说明它如何工作,让我们假设进程A使用数学协处理器。当发生上下文切换时,内核置TS标志并把浮点寄存器保存在进程A的TSS中。如果新进程B不利用协处理器,内核就不必恢复浮点寄存器的内容。但是,只要B打算执行ESCAPE或MMX指令,CPU就产生一个"Device not available"异常,并且相应的异常处理程序用保存在进程B中的TSS的值装载浮点寄存器。
现在,让我们描述为处理FPU、MMX和 XMM寄存器的选择性装入而引入的数据结构。
它们存放在进程描述符的thread.i387子字段中,其格式由i387_union联合体描述;
union 1387_union {
struct i387_fsave_Struct fsave;
struct i387__fxsave_struct fxsave;
struct i387_soft_struct soft;
);
正如你看到的,这个字段只可以存放三种不同数据结构中的一种。i387_soft_struct
结构由无数学协处理器的CPU模型使用;Linux内核通过软件模拟协处理器来支持这些
老式芯片。不过,我们不打算进一步讨论这种遗留问题。i387_fsave_struct结构由具
有数学协处理器、也可能有MMX单元的CPU模型使用。最后,i387_Exsave_struct
结构由具有SSE 和SSE2扩展功能的 CPU模型使用。
进程描述符包含两个附加的标志∶
- 包含在thread_info 描述符的status字段中的TS_USEDFPU标志。它表示进
程在当前执行的过程中是否使用过 FPU、MMX和 XMM寄存器。 - 包含在 task_struct描述符的flags字段中的PF_USED_MATH标志。这个标志
表示thread.i387子字段的内容是否有意义。该标志在两种情况下被清0(没有
意义),如下所示∶
1) 当进程调用execve()系统调用(参见第二十章)开始执行一个新程序时。因
为控制权将不再返回到前一个程序,所以当前存放在thread.i387中的数据也
不再使用。
2)当在用户态下执行一个程序的进程开始执行一个信号处理程序时(参见第十一
章)。因为信号处理程序与程序的执行流是异步的,因此,浮点寄存器对信号处
理程序来说可能是毫无意义的。不过,内核开始执行信号处理程序之前在
thread.i387中保存浮点寄存器,处理程序结束以后恢复它们。因此,信号处
理程序可以使用数学协处理器。
1)保存FPU 寄存器
如前所述,__switch_to()函数把被替换进程prev的描述符作为参数传递给__unlazy_fpu宏,并执行该宏。这个宏检查prev的TS_USEDFPU标志值。如果该标志被设进程 117置,说明prev在这次执行中使用了FPU、MMX、SSE或SSE2指令;因此内核必须保存相关的硬件上下文∶
if(prev->thread_info->status & TS_USEDFPU)
gave_init_fpu(prev);
save_init__fpu ()函数依次执行下列操作∶
-
把FPU寄存器的内容转储到prev进程描述符中,然后重新初始化FPU。如果CPU
使用SSE/SSE2扩展,则还应该转储XMM寄存器的内容,并重新初始化SSE/SSE2
单元。一对功能强大的嵌入式汇编语言指令处理每件事情,如果CPU使用SSE/
SSE2扩展,则∶
asm volatille(·fx8ave 00;fnclex"
:“=m”(tsk->thread.i387.fxsave));
否则∶
asm volatile(“fnsave 00;fwait*
;”=m"(t容k->thread.i387.fsave)); -
重置 prev的TS_USEDFPU标志∶
prev->thread_info->8tatus &= -TS_USEDFPU; -
用stts()宏设置cr0的TS标志,实际上,该宏产生下面的汇编语言指令∶
movl %cr0,%eax
or1 $8,%eax
movl %eax,%cr0
2)装载 FPU寄存器
当next 进程刚恢复执行时,浮点寄存器的内容还没有被恢复,不过,cr0的TS标志位已由__unlazy_fpu()设置。因此,next 进程第一次试图执行ESCAPE、MMX或SSE/SSE2指令时,控制单元产生一个"Device not available"异常,内核(更确切地说,由异常调用的异常处理程序)运行math_state_restore()函数。处理程序把next进程当作 current 进程。
void math_state_restore()
asm volatlle("clts";/* clear the TS flag of cr0*/
if(!(current->flags & PF_USED_MATH》)
init_fpu(current);
restore__fpu(current);
current->thread.statusI=TS_USEDFPU;
这个函数清cr0的TS标志,以便进程以后执行FPU、MMX或SSE/SSE2指令时不再触发"设备不可用"的异常。如果thread.i387子字段中的内容是无效的,也就是说,如果PF_USED_MATH标志等于0,就调用init__fpu()重新设置thread.i387子字段,并把PF_USED_MATH标志的当前值置为1。restore_fpu()函数把保存在thread.i387子字段中的适当值载入FPU寄存器。为此,根据CPU是否支持SSE/SSE2扩展来使用Exrstor或 frstor汇编语言指令。最后,math_state_restore()设置TS_USEDFPU标志。
3)在内核态使用 FPU、MMX和 SSE/SSE2单元
内核也可以使用FPU、MMX和 SSE/SSE2单元。当然,这样做的时候,应该避免干扰用户态进程所进行的任何计算。因此∶
-
在使用协处理器之前,如果用户态进程使用了FPU(TS_USEDFPU标志),内核必须调用kernel_fpu_begin(),其本质就是调用save_init_fpu()来保存寄存器的内容,然后重新设置 cr0寄存器的 TS标志。
-
在使用完协处理器之后,内核必须调用kernel_fpu_end()设置cr0寄存器的TS标志。
稍后,当用户态进程执行协处理器指令时,math_state_restore()函数将恢复寄存器的内容(就像处理进程切换那样)。
但是,应该注意,当前用户态进程正在使用协处理器时,kernel_fpu_begin()的执行时间相当长,以至于无法通过使用FPU、MMX或 SSE/SSE2单元达到加速的目的。实际上,内核只在有限的场合使用FPU、MMX或 SSE/SSE2单元,典型的情况有∶当移动或清除大内存区字段时,或者当计算校验和函数时。
四、创建进程
Unix操作系统紧紧依赖进程创建来满足用户的需求。例如,只要用户输入一条命令,shell 进程就创建一个新进程,新进程执行shell的另一个拷贝。
传统的Unix 操作系统以统一的方式对待所有的进程∶子进程复制父进程所拥有的资源。这种方法使进程的创建非常慢且效率低,因为子进程需要拷贝父进程的整个地址空间。实际上,子进程几乎不必读或修改父进程拥有的所有资源,在很多情况下,子进程立即调用 execve(),并清除父进程仔细拷贝过来的地址空间。
现代 Unix 内核通过引入三种不同的机制解决了这个问题∶
- 写时复制技术允许父子进程读相同的物理页。只要两者中有一个试图写一个物理页,内核就把这个页的内容拷贝到一个新的物理页,并把这个新的物理页分配给正在写的进程。第九章将全面地解释这种技术在 Linux中的实现。
- 轻量级进程允许父子进程共享每进程在内核的很多数据结构,如页表(也就是整个用户态地址空间))、打开文件表及信号处理。
- vfork()系统调用创建的进程能共享其父进程的内存地址空间。为了防止父进程重写子进程需要的数据,阻塞父进程的执行,一直到子进程退出或执行一个新的程序为止。我们将在下一节了解有关vfork()系统调用更多的知识。
1、clone()、fork()及vfork()系统调用
在Linux中,轻量级进程是由名为clone()的函数创建的,这个函数使用下列参数;
-
fn
指定一个由新进程执行的函数。当这个函数返回时,子进程终止。函数返回一个整
数、表示子进程的退出代码。 -
arg
指向传递给 fn()函数的数据。 -
flags
各种各样的信息。低字节指定子进程结束时发送到父进程的信号代码,通常选择
SIGCHLD信号。剩余的3个字节给一clone标志组用于编码,如表3-8所示。 -
child_stack
表示把用户态堆栈指针赋给子进程的esp寄存器。调用进程(指调用clone()的
父进程)应该总是为子进程分配新的堆栈。 -
tl8
表示线程局部存储段(TLS)数据结构的地址,该结构是为新轻量级进程定义的(参
见第二章"Linux GDT"一节)。只有在CLONE_SETTLS标志被设置时才有意义。 -
pti
表示父进程的用户态变量地址,该父进程具有与新轻量级进程相同的PID。只有在
CLONE__PARENT_SETTID标志被设置时才有意义。 -
ctia
表示新轻量级进程的用户态变量地址,该进程具有这一类进程的PID。只有在
CLONE__CHILD_SETTID标志被设置时才有意义。



实际上,clone()是在C语言库中定义的一个封装(wrapper)函数(参见第十章"POSIX
API和系统调用"一节),它负责建立新轻量级进程的堆栈并且调用对编程者隐藏的clone()系统调用。实现clone()系统调用的 sys_clone()服务例程没有fn和arg参数。实际上,封装函数把 fn指针存放在子进程堆栈的某个位置处,该位置就是该封装函数本身返回地址存放的位置。arg指针正好存放在子进程堆栈中 fn 的下面。当封装函数结束时,CPU从堆栈中取出返回地址,然后执行fn(arg)函数。
传统的 fork()系统调用在Linux中是用clone()实现的,其中 clone()的 flags参数指定为 sIGCHLD信号及所有清0的 clone标志,而它的 child_stack参数是父进程当前的堆栈指针。因此,父进程和子进程暂时共享同一个用户态堆栈。但是,要感谢写时复制机制,通常只要父子进程中有一个试图去改变栈,则立即各自得到用户态堆栈的一份拷贝。
前一节描述的vfork()系统调用在Linux中也是用clone()实现的,其中 clone()的参数flags指定为SIGCHLD信号和CLONE_VM及CLONE_VFORK标志,clone()的参数child_stack等于父进程当前的栈指针。
2、do_fork()函数
do_fork()函数负责处理clone()、fork()和vfork()系统调用,执行时使用下列参数∶
- clone_flags
与clone()的参数flags相同。 - stack_start
与clone()的参数child_stack相同。 - regs
指向通用寄存器值的指针,通用寄用器的值是在从用户态切换到内核态时被保存到内核态堆栈中的(参见第四章"do_IRQ0)函数"一节)。 - stack_size
未使用(总是被设置为0)。122 第三章 - parent_tidptr,child_tidptr
与clone()中的对应参数ptid和 ctid相同。
do_fork()利用辅助函数copy_process()来创建进程描述符以及子进程执行所需要的所有其他内核数据结构。下面是 do_fork()执行的主要步骤∶
-
1.通过查找pidmap_array位图,为子进程分配新的PID(参见本章前面"标识一个进程"一节)。
-
2.检查父进程的ptrace字段(current->ptrace)∶如果它的值不等于0,说明有另外一个进程正在跟踪父进程,因而,do__fork()检查 debugger程序是否自己想跟踪子进程(独立于由父进程指定的CLONE_PTRACE标志的值)。在这种情况下,如果子进程不是内核线程(CLONE_UNTRACED标志被清0),那么do_fork()函数设置 CLONE_PTRACE标志。
-
3.调用copy_process()复制进程描述符。如果所有必须的资源都是可用的,该函数
返回刚创建的 task_struct描述符的地址。这是创建过程的关键步骤,我们将在
do_fork()之后描述它。 -
4.如果设置了CLONE_STOPPED标志,或者必须跟踪子进程,即在p->ptrace中设
置了PT_PTRACED标志,那么子进程的状态被设置成TASK_STOPPED,并为子进
程增加挂起的SIGSTOP信号(参见第十一章"信号的作用一节)。在另外一个进程
(不妨假设是跟踪进程或是父进程)把子进程的状态恢复为TASK_RUNNING 之前
(通常是通过发送SIGCONT信号),子进程将一直保持TASK__STOPPED状态。 -
5.如果没有设置CLONE_sTOPPED标志,则调用wake_up_new_task()函数以执行
下述操作∶
a. 调整父进程和子进程的调度参数(参见第七章"调度算法"一节)
b. 如果子进程将和父进程运行在同一个CPU上(注8),而且父进程和子进程不
能共享同一组页表(CLONE_VM标志被清0),那么,就把子进程插入父进程运
行队列,插入时让子进程恰好在父进程前面,因此而迫使子进程先于父进程运
行。如果子进程刷新其地址空间,并在创建之后执行新程序,那么这种简单的
处理会产生较好的性能。而如果我们让父进程先运行,那么写时复制机制将会
执行一系列不必要的页面复制。
c. 否则,如果子进程与父进程运行在不同的CPU上,或者父进程和子进程共享同
一组页表(CLONE_VM标志被设置),就把子进程插入父进程运行队列的队尾。 -
6.如果CLONE_STOPPED标志被设置,则把子进程置为TASK_STOPPED状态。
注8∶ 当内核创建一个新进程时父进程有可能会被转移到另一个CPU 上执行。进程 123 -
7.如果父进程被跟踪,则把子进程的PID存入 current的 ptrace_message字段并调
用 ptrace_notify()。ptrace_notify()使当前进程停止运行,并向当前进程的
父进程发送 S工GCHLD信号。子进程的祖父进程是跟踪父进程的debugger进程。
SIGCHLD信号通知debugger进程∶current已经创建了一个子进程,可以通过查
找 current->ptrace_message 字段获得子进程的 PID。 -
8.如果设置了CLONE_VFORK标志,则把父进程插入等待队列,并挂起父进程直到子
进程释放自己的内存地址空间(也就是说,直到子进程结束或执行新的程序)。 -
9.结束并返回子进程的PID。
3、copy_process()函数
copy_process()创建进程描述符以及子进程执行所需要的所有其他数据结构。它的参数与 do_fork()的参数相同,外加子进程的PID。下面描述copy_process()的最重要的步骤∶
-
- 检查参数clone_flags所传递标志的一致性。尤其是,在下列情况下,它返回错误代号∶
a.CLONE_NEWNS 和CLONE_FS标志都被设置。
b. CLONE_THREAD标志被设置,但CLONE_SIGHAND标志被清0(同一线程组中的轻量级进程必须共享信号)。CLONE_SIGHAND标志被设置,但CLONE_VM被清O(共享信号处理程序的轻量级进程也必须共享内存描述符)。
- 检查参数clone_flags所传递标志的一致性。尤其是,在下列情况下,它返回错误代号∶
-
- 通过调用security_task_create())以及稍后调用的 security_task_alloc()执行所有附加的安全检查。Linux 2.6提供扩展安全性的钩子函数,与传统Unix相比,它具有更加强壮的安全模型。详情参见第二十章。
-
- 调用dup_task_struct〈)为子进程获取进程描述符。该函数执行如下操作∶
a. 如果需要,则在当前进程中调用__unlazy_fpu(),把FPU、MMX和SSE/SSE2寄存器的内容保存到父进程的thread_info结构中。稍后,dup_task_struct()将把这些值复制到子进程的 thread_info结构中。
b.执行 alloc_task_struct()宏,为新进程获取进程描述符(task_struct结构),并将描述符地址保存在 tsk 局部变量中。
c. 执行alloc_thread_info宏以获取一块空闲内存区,用来存放新进程的thread_info结构和内核栈,并将这块内存区字段的地址存在局部变量ti中。正如在本章前面"标识一个进程"一节中所述;这块内存区字段的大小是8KB或4KB。
d. 将current进程描述符的内容复制到tsk所指向的task_struct结构中,然后把 tsk->thread_info 置为ti。
e. 把current进程的thread_info 描述符的内容复制到ti所指向的结构中,然后把ti->task 置为tsk。
f. 把新进程描述符的使用计数器(tsk->usage)置为2,用来表示进程描述符正
在被使用而且其相应的进程处于活动状态(进程状态即不是 EXIT_zOMBIE,也不是 EXIT_DEAD)。
g. 返回新进程的进程描述符指针(tsk)。
- 调用dup_task_struct〈)为子进程获取进程描述符。该函数执行如下操作∶
-
- 检查存放在current->signal->rlim【RLIMIT_NPROC】.rlim_cur变量中的值是否小于或等于用户所拥有的进程数。如果是,则返回错误码,除非进程没有root权限。该函数从每用户数据结构 user_struct中获取用户所拥有的进程数。通过进程描述符 user字段的指针可以找到这个数据结构。
-
- 递增user_struct结构的使用计数器(tsk->user->__count字段)和用户所拥有的进程的计数器(tsk->user->processes)。
-
- 检查系统中的进程数量(存放在nr_threads变量中)是否超过max_chreads变量的值。这个变量的缺省值取决于系统内存容量的大小。总的原则是∶所有thread_info描述符和内核栈所占用的空间不能超过物理内存大小的1/8。不过,系统管理员可以通过写/proc/sys/kernel/threads-max文件来改变这个值。
-
- 如果实现新进程的执行域和可执行格式的内核函数(参见第二十章)都包含在内核模块中,则递增它们的使用计数器(参见附录二)。
-
- 设置与进程状态相关的几个关键字段∶
a. 把大内核锁计数器 tsk->lock_depth初始化为-1(参见第五章"大内核锁"一节)。
b.把tsk->did_exec字段初始化为0∶它记录了进程发出的 execve()系统调用的次数。
c. 更新从父进程复制到tsk→>flags字段中的一些标志∶首先清除PF_SUPERPRIV标志,该标志表示进程是否使用了某种超级用 户权限。然后设 置PF_FORKNOEXEC 标志,它表示子进程还没有发出execve()系统调用。
- 设置与进程状态相关的几个关键字段∶
-
- 把新进程的PID 存入 tsk->pid字段。
- 10.如果clone_flags参数中的CLONE_PARENT_SETTID标志被设置,就把子进程的PID复制到参数 parent_tidptr指向的用户态变量中。进程 125
-
- 初始化子进程描述符中的1ist_head数据结构和自旋锁,并为与挂起信号、定时器及时间统计表相关的几个字段赋初值。
-
- 调用copy_semundo(),copy_files(),copy_fs(),copy_sighand(),copy_sigmal(),copy_mm()和copy_namespace()来创建新的数据结构,并把父进程相应数据结构的值复制到新数据结构中,除非 clone_flags参数指出它们有不同的值。
- 13.调用copy_thread(),用发出clone()系统调用时CPU寄存器的值(正如第十章所述,这些值已经被保存在父进程的内核栈中)来初始化子进程的内核栈。不过,copy_thread()把 eax寄存器对应字段的值【这是 fork()和clone()系统调用在子进程中的返回值】字段强行置为0。子进程描述符的 thread.esp字段初始化为子进程内核栈的基地址,汇编语言函数(ret_from fork())的地址存放在 thread.eip字段中。如果父进程使用I/O权限位图,则子进程获取该位图的一个拷贝。最后,如果CLONE_SETTLS标志被设置,则子进程获取由clone()系统调用的参数tls指向的用户态数据结构所表示的TLS段(注9)。
-
- 如果clane_flags参数的值被置为CLONE_CHILD_SETPID或CLONE_CHILD_CLEARTID,就把childtiaptr参数的值分别复制到tsk->set_chid_tid 或tsk->clear_child_tid字段。这些标志说明∶必须改变子进程用户态地址空间的child_tidptr所指向的变量的值,不过实际的写操作要稍后再执行。
- 15.清除子进程thread_info 结构的TIF__SYSCALL_TRACE标志,以使ret_from_fork()函数不会把系统调用结束的消息通知给调试进程(参见第十章"进入和退出系统调用"一节)。(因为对子进程的跟踪是由tsk->ptrace中的 PTRACE_SYSCALL标志来控制的,所以子进程的系统调用跟踪不会被禁用。)
-
- 用 clone_flags参数低位的信号数字编码初始化tsk->exi_signal字段,如果CLONE_THREAD标志被置位,就把 tsk->exit_signal字段初始化为-1。正如我们将在本章稍后"进程终止"一节所看见的,只有当线程组的最后一个成员(通常是线程组的领头)“死亡”,才会产生一个信号,以通知线程组的领头进程的父进程。
-
- 调用sched_Fork()完成对新进程调度程序数据结构的初始化。该函数把新进程的状态设置为TASK_RUNNING,并把 thread_info结构的 preempt_count字段设置为注9∶ 细心的读者可能想知道copy_thread()怎样茨得clone()的t1s参数的值,因为tls并不被传递给do_Fork()和嵌套画数。我们将在第十章看到,通常通过拷贝系统调用的泰数的值到某个CPU寄存器来把它们传递给内核;因此,这些值与其他寄存器一起被保存在内核态堆栈中。copy_thread()面数只查看esi的值在内核堆栈中对应的位置保存的地址。从而禁止内核抢占(参见第五章"内核抢占"一节)。此外,为了保证公平的进程调度,该函数在父子进程之间共享父进程的时间片(参见第七章"scheduler_tick()函数"一节)。
- 18.把新进程的thread_info结构的cpu字段设置为由smp_processor_id()所返回的本地CPU号。
-
- 初始化表示亲子关系的字段。尤其是,如果CLONE_PARENT或CLONE_THREAD被设置,就用current->real_parent的值初始化 tsk->real_parent和tsk->parent,因此,子进程的父进程似乎是当前进程的父进程。否则,把tsk->real_parent和tsk->parent置为当前进程。
-
- 如果不需要跟踪子进程(没有设置CLONE_PTRAC标志),就把tsk->ptrace字段设置为0。tsk->ptrace字段会存放一些标志,而这些标志是在一个进程被另外一个进程跟踪时才会用到的。采用这种方式,即使当前进程被跟踪,子进程也不会被跟踪。
-
- 执行SET__LINKS宏,把新进程描述符插入进程链表。
-
- 如果子进程必须被跟踪(tsk->ptrace字段的PT_PTRACED标志被设置),就把current->parent赋给 tsk->parent,并将子进程插入调试程序的跟踪链表中。
- 23.调用 attach_pid()把新进程描述符的PID插入 pichash【PIDTYPE_PID】散列表。
-
- 如果子进程是线程组的领头进程(CLONE_THREAD标志被清0)∶
a. 把tsk->tgid的初值置为tsk->pid。
b.把 tsk->group_leader的初值置为tsk。
c.调用三次attach_pid(),把子进程分别插入PIDTYPE_TGID、PIDTYPE_PGID
和 PIDTYPE_SID类型的 PID散列表。
- 如果子进程是线程组的领头进程(CLONE_THREAD标志被清0)∶
-
- 否则,如果子进程属于它的父进程的线程组(CLONE_THREAD标志被设置)∶
a.把tsk->tgid的初值置为tsk->current->tgid。
b. 把 tsk->group_leader的初值置为 current->group_leader的值。
c. 调用 attach_pid(),把子进程插入PIDTYPE_TGID类型的散列表中(更具体地说,插入 current->group_leader进程的每个PID链表)。
- 否则,如果子进程属于它的父进程的线程组(CLONE_THREAD标志被设置)∶
-
- 现在,新进程已经被加入进程集合;递增nr_threads变量的值。
-
- 递增 total__forks变量以记录被创建的进程的数量。
-
- 终止并返回子进程描述符指针(tsk)。进程 127
让我们回头看看在do_fork()结束之后都发生了什么。现在,我们有了处于可运行状态的完整的子进程。但是,它还没有实际运行,调度程序要决定何时把CPU 交给这个子进程。在以后的进程切换中,调度程序继续完善子进程∶把子进程描述符 thread字段的值装入几个CPU寄存器。特别是把thread.esp(即把子进程内核态堆栈的地址)装入esp寄存器,把函数ret_Erom_fork()的地址装入eip寄存器。这个汇编语言函数调用schedule_tail()函数(它依次调用finish_task_switch()来完成进程切换,参见第七章"schedule()函数"一节),用存放在栈中的值再装载所有的寄存器,并强迫 CPU返回到用户态。然后,在 fork()、vfork()或clone()系统调用结束时,新进程将开始执行。系统调用的返回值放在eax寄存器中;返回给子进程的值是0,返回给父进程的值是子进程的PID。回顾copy_thread()对子进程的eax寄存器所执行的操作(copy_process()的第13步),就能理解这是如何实现的。
除非fork系统调用返回0,否则,子进程将与父进程执行相同的代码(参见copy_process()的第13步)。应用程序的开发者可以按照Unix编程者熟悉的方式利用这一事实,在基于PID 值的程序中插入一个条件语句使子进程与父进程有不同的行为。
4、内核线程
传统的Unix系统把一些重要的任务委托给周期性执行的进程,这些任务包括刷新磁盘高速缓存,交换出不用的页框,维护网络连接等等。事实上,以严格线性的方式执行这些任务的确效率不高,如果把它们放在后台调度,不管是对它们的函数还是对终端用户进程都能得到较好的响应。因为一些系统进程只运行在内核态,所以现代操作系统把它们的函数委托给内核线程(kernel thread),内核线程不受不必要的用户态上下文的拖累。在 Linux 中,内核线程在以下几方面不同于普通进程∶
- 内核线程只运行在内核态,而普通进程既可以运行在内核态,也可以运行在用户态。
- 因为内核线程只运行在内核态,它们只使用大于PAGE__OFFSET的线性地址空间。另一方面,不管在用户态还是在内核态,普通进程可以用4GB的线性地址空间。
1)创建一个内核线程
kernel_thread()函数创建一个新的内核线程,它接受的参数有∶所要执行的内核函数的地址(fn)、要传递给函数的参数(arg)、一组clone标志(flags)。该函数本质上以下面的方式调用do_fork()∶
do_fork(flagsICLONE_VMICLONE_UNTRACED,0,pregs,0,NULL,NULL);
CLONEVM标志避免复制调用进程的页表;由于新内核线程无论如何都不会访问用户态地址空间,所以这种复制无疑会造成时间和空间的浪费。CLONE_UNTRACED标志保证不会有任何进程跟踪新内核线程,即使调用进程被跟踪。
传递给 do_fork()的参数pregs表示内核栈的地址,copy_thread()函数将从这里找到为新线程初始化CPU寄存器的值。kernel_thread()函数在这个栈中保留寄存器值的目的是∶
- 通过 copy_thread()把 ebx和 edx分别设置为参数fn和arg 的值。
- 把 eip寄存器的值设置为下面汇编语言代码段的地址∶
mov1 edx, eax
push1 $edx
call *ebx
push1 号eax
Call do_exi
因此,新的内核线程开始执行En(arg)函数,如果该函数结束,内核线程执行系统调用_exit(),并把 En()的返回值传递给它(参见本章稍后"撤消进程"一节)。
2)进程0
所有进程的祖先叫做进程0,idle 进程 或因为历史的原因叫做 swapper进程,它是在Linux的初始化阶段从无到有创建的一个内核线程(参见附录一)。这个祖先进程使用下列静态分配的数据结构(所有其他进程的数据结构都是动态分配的);
-
存放在 init_task变量中的进程描述符,由INIT_TASK宏完成对它的初始化。
-
存放在init_thread_union变量中的thread_info 描述符和内核堆栈,由
INIT_THREAD_INFO宏完成对它们的初始化。 -
由进程描述符指向的下列表∶
一init_mm
init_f8
一 init_files
一 init__signals
一 init_sighand
这些表分别由下列宏初始化∶
— INIT_MM进程 129
一 INIT_FS
一 INIT_FILES
— INIT_SIGNALS
一 INIT_SIGHAND -
主内核页全局目录存放在 swapper_pg_dir中(参见第二章"内核页表"一节)。
start_kerne1()函数初始化内核需要的所有数据结构,激活中断,创建另一个叫进程1的内核线程(一般叫做 init 进程)∶
kernel_thread(init,NUL,CLONE_FSICLONE_sIGHAND));
新创建内核线程的 PID为1,并与进程0共享每进程所有的内核数据结构。此外,当调度程序选择到它时,init 进程开始执行 init()函数。
创建init进程后,进程0执行cpu_idle()函数,该函数本质上是在开中断的情况下重复执行hlt 汇编语言指令(参见第四章)。只有当没有其他进程处于TASK_RUNNING状态时,调度程序才选择进程0。
在多处理器系统中,每个CPU都有一个进程0。只要打开机器电源,计算机的BIOS就启动某一个CPU,同时禁用其他 CPU。运行在CPU0上的 swapper进程初始化内核数据结构,然后激活其他的CPU,并通过copy_process()函数创建另外的swapper进程,把0传递给新创建的swapper进程作为它们的新PID。此外,内核把适当的CPU索引赋给内核所创建的每个进程的 thread_info描述符的 cpu字段。
3)进程 1
由进程0创建的内核线程执行ini()函数,init()依次完成内核初始化。init()调用execve()系统调用装入可执行程序init。结果,init 内核线程变为一个普通进程,且拥有自己的每进程(per-process)内核数据结构(参见第二十章)。在系统关闭之前,init进程一直存活,因为它创建和监控在操作系统外层执行的所有进程的活动。
4)其他内核线程
Linux使用很多其他内核线程。其中一些在初始化阶段创建,一直运行到系统关闭;而其他一些在内核必须执行一个任务时"按需"创建,这种任务在内核的执行上下文中得到很好的执行。
一些内核线程的例子(除了进程0和进程1)是∶
- keventd(也被称为事件)
执行 keventd_wg工作队列(参见第四章)中的函数。 - kapmd
处理与高级电源管理(APM)相关的事件。 - kswapd
执行内存回收,在第十七章"周期回收"一节将进行描述。 - pdfush
刷新"脏"缓冲区中的内容到磁盘以回收内存,在第十五章"pdflush内核线程"一节将进行描述。 - kblockd
执行 kblockd_workqueue 工作队列中的函数。实质上,它周期性地激活块设备驱动程序,将在第十四章"激活块设备驱动程序"一节给予描述。 - kSoftired
运行 tasklet(参看第四章"软中断及 tasklet"一节);系统中每个CPU都有这样一个内核线程。
五、撤消进程
很多进程终止了它们本该执行的代码,从这种意义上说,这些进程"死"了。当这种情况发生时,必须通知内核以便内核释放进程所拥有的资源,包括内存、打开文件及其他我们在本书中讲到的零碎东西,如信号量。
进程终止的一般方式是调用exit()库函数,该函数释放C函数库所分配的资源,执行编程者所注册的每个函数,并结束从系统回收进程的那个系统调用。exit()函数可能由编程者显式地插入。另外,C编译程序总是把exit《)函数插入到main()函数的最后一条语句之后。
内核可以有选择地强迫整个线程组死掉。这发生在以下两种典型情况下∶当进程接收到一个不能处理或忽视的信号时(参见十一章),或者当内核正在代表进程运行时在内核态产生一个不可恢复的CPU异常时(参见第四章)。
1、进程终止
在 Linux 2.6中有两个终止用户态应用的系统调用∶进程 13
-
edit_group()系统调用,它终止整个线程组,即整个基于多线程的应用。do_group_exdit()是实现这个系统调用的主要内核函数。这是C库函数exit()应该调用的系统调用。
-
exit()系统调用,它终止某一个线程,而不管该线程所属线程组中的所有其他进程。do_exit()是实现这个系统调用的主要内核函数。这是被诸如pthread_exit()的 Linux 线程库的函数所调用的系统调用。
2、do_group_exit()函数
do_group_exit()函数杀死属于current 线程组的所有进程。它接受进程终止代号作为参数,进程终止代号可能是系统调用 exit_group()(正常结束)指定的一个值,也可能是内核提供的一个错误代号(异常结束)。该函数执行下述操作∶
-
检查退出进程的SIGNAL__GROUP_EXIT标志是否不为0,如果不为0,说明内核已经开始为线程组执行退出的过程。在这种情况下,就把存放在current->gignal->group_exit_code中的值当作退出码,然后跳转到第 4步。
-
否则,设置进程的SIGNAL_GROUP_EXIT标志并把终止代号存放到current->signal->group_exit_code字段。
-
调用zap_other_threads()函数杀死current线程组中的其他进程(如果有的话)。为了完成这个步骤,函数扫描与current->tgid对应的PIDTYPE_TGID类型的散列表中的每个PID链表,向表中所有不同于current的进程发送SIGKILL信号(参见第十一章),结果,所有这样的进程都将执行do_exit()函数,从而被杀死。
4.调用do_exit()函数,把进程的终止代号传递给它。正如我们将在下面看到的,do_exit()杀死进程而且不再返回。
3、do_exit()函数
所有进程的终止都是由do_exit(》函数来处理的,这个函数从内核数据结构中删除对终
止进程的大部分引用。do_exit()函数接受进程的终止代号作为参数并执行下列操作∶
-
把进程描述符的 f1ag字段设置为 PF_EXITING标志,以表示进程正在被删除。
-
如果需要,通过函数deltimer_sync()(参见第六章)从动态定时器队列中删除进程描述符。
-
分别调用exit_mm()、exit_sem()、__exit_files()、_exit_fs()、exit
namespace()和exit_thread()函数从进程描述符中分离出与分页、信号量、文件
系统、打开文件描述符、命名空间以及I/O权限位图相关的数据结构。如果没有其
他进程共享这些数据结构,那么这些函数还删除所有这些数据结构中。/132 第三章 -
如果实现了被杀死进程的执行域和可执行格式(参见第二十章)的内核函数包含在
内核模块中,则函数递减它们的使用计数器。 -
把进程描述符的exit__co de 字段设置成进程的终止代号,这个值要么是
_exit()或exit_group()系统调用参数(正常终止),要么是由内核提供的一个
错误代号(异常终止)。 -
调用 exit_notify《)函数执行下面的操作∶
a. 更新父进程和子进程的亲属关系。如果同一线程组中有正在运行的进程,就让终止进程所创建的所有子进程都变成同一线程组中另外一个进程的子进程,否则让它们成为init的子进程。
b. 检查被终止进程其进程描述符的exit_signal字段是否不等于-1,并检查进程是否是其所属进程组的最后一个成员(注意∶正常进程都会具有这些条件,参见前面"clone()、fork()和 vfork()系统调用"一节中对 copy_process()的描述,第16步)。在这种情况下,函数通过给正被终止进程的父进程发送一个信号(通常是SIGCHLD),以通知父进程子进程死亡。
c. 否则,也就是exit_signal字段等于-1,或者线程组中还有其他进程,那么只要进程正在被跟踪,就向父进程发送一个S工GCHLD信号(在这种情况下,父进程是调试程序,因而,向它报告轻量级进程死亡的信息)。
d. 如果进程描述符的exit_signal字段等于-1,而且进程没有被跟踪,就把进程描述符的exit_state字段置为EX工T_DEAD,然后调用release_task()回收进程的其他数据结构占用的内存,并递减进程描述符的使用计数器(见下一节)。使用记数器变为1(参见 copy_process()函数的第3f步),以使进程描述符本身正好不会被释放。
e. 否则,如果进程描述符的exit_sigmnal字段不等于-1,或进程正在被跟踪,就把exit_state字段置为 EXIT_ZOMBIE。在下一节我们将看到如何处理僵死进程。
f.把进程描述符的flags字段设置为PF_DEAD标志(参见第七章"schedule(函数"一节)。 -
调用 schedule,()函数(参见第七章)选择一个新进程运行。调度程序忽略处于EX工T_ZOMBIE状态的进程,所以这种进程正好在 schedule()中的宏switch_to被调用之后停止执行。正如在第七章我们将看到的∶调度程序将检查被替换的僵死进程描述符的PF_DEAD标志并递减使用计数器,从而说明进程不再存活的事实。进程 133
4、进程删除
Unix允许进程查询内核以获得其父进程的PID.或者其任何子进程的执行状态。例如,进程可以创建一个子进程来执行特定的任务,然后调用诸如wait()这样的一些库函数检查子进程是否终止。如果子进程已经终止,那么,它的终止代号将告诉父进程这个任务是否已成功地完成。
为了遵循这些设计选择,不允许Unix内核在进程一终止后就丢弃包含在进程描述符字段中的数据。只有父进程发出了与被终止的进程相关的wai()类系统调用之后,才允许这样做。这就是引入僵死状态的原因∶尽管从技术上来说进程已死,但必须保存它的描述符,直到父进程得到通知。
如果父进程在子进程结束之前结束会发生什么情况呢?在这种情况下,系统中会到处是僵死的进程,而且它们的进程描述符永久占据着RAM。如前所述,必须强迫所有的孤儿进程成为init 进程的子进程来解决这个问题。这样,init 进程在用wai()类系统调用检查其合法的子进程终止时,就会撤消僵死的进程。
release_task()函数从僵死进程的描述符中分离出最后的数据结构;对僵死进程的处理有两种可能的方式∶如果父进程不需要接收来自子进程的信号,就调用do_exit();如果已经给父进程发送了一个信号,就调用wait4()或waitpid()系统调用。在后一种情况下,函数还将回收进程描述符所占用的内存空间,而在前一种情况下,内存的回收将由进程调度程序来完成(参见第七章)。该函数执行下述步骤∶
-
递减终止进程拥有者的进程个数。这个值存放在本章前面提到的user_struct结构中(参见 copy__process()的第4步)。
-
如果进程正在被跟踪,函数将它从调试程序的ptrace_children链表中删除,并让该进程重新属于初始的父进程。
-
调用__exit_signal()删除所有的挂起信号并释放进程的signal_struct描述符。如果该描述符不再被其他的轻量级进程使用,函数进一步删除这个数据结构。此外,函数调用exit_itimers{)从进程中剥离掉所有的 POSIX时间间隔定时器。
-
调用__exit_sighand()删除信号处理函数。
-
调用__unhash_process《),该函数依次执行下面的操作;
a. 变量nr_threads减1。
b. 两次调用detach_pid(),分别从PIDTYPE_PID和PIDTYPE_TGID类型的 PID 散列表中删除进程描述符。/134 第三章
c.如果进程是线程组的领头进程,那么再调用两次detach_pid(),从PIDTYPE_
PGID和 PIDTYPE__SID类型的散列表中删除进程描述符。
d. 用宏REMOVE_L工NKS 从进程链表中解除进程描述符的链接。 -
如果进程不是线程组的领头进程,领头进程处于僵死状态,而且进程是线程组的最后一个成员,则该函数向领头进程的父进程发送一个信号,通知它进程已死亡。
-
调用sched_exit()函数来调整父进程的时间片(这一步在逻辑上作为对copy_process()第17步的补充)。
-
调用put_task_struct()递减进程描述符的使用计数器,如果计数器变为0,则函数终止所有残留的对进程的引用。
a. 递减进程所有者的 user_struct数据结构的使用计数器(__count字段)(参见 copy_process()的第5步),如果使用计数器变为0,就释放该数据结构。
b. 释放进程描述符以及 thread_info描述符和内核态堆栈所占用内存区域。

















 1147
1147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









