







目录
0 背景
在全球气候变暖、栖息地破碎化加剧的今天,物种分布范围正以人类难以察觉的速度悄然变迁。据IPBES报告显示,全球约100万种物种正面临灭绝风险,其中栖息地丧失是首要威胁。如何精准预测物种潜在分布,为保护区规划、生态廊道建设提供科学依据,成为生物多样性保护的核心命题。
传统统计模型(如广义线性模型)在应对物种分布预测时往往捉襟见肘:标本记录数据稀疏、存在点(presence-only data)与缺失数据(absence data)严重不平衡、环境变量多维共线性等问题,使得模型鲁棒性大打折扣。而最大熵模型(MaxEnt)的崛起,恰似为生态学家打开了一扇新窗——它无需假设数据分布形态,仅需基于物种存在点与环境变量的关系,即可推演出符合生态位理论的概率分布,被誉为"小样本场景下的预测神器"。
1 最大熵模型的核心原理:从哲学到算法
最大熵原理源于信息论先驱香农的深邃洞察:在已知信息(约束条件)下,应选择不确定性最大的概率分布。这本质上是对奥卡姆剃刀原则的量化实现——不做过度假设,让数据自己"说话"。
在物种分布预测场景中,约束条件体现为物种存在点对应的环境变量特征(如年均温15-20℃,海拔800-2500m)。MaxEnt通过迭代计算,寻找满足这些约束且熵值最大的概率分布。这意味着模型会尽可能保留所有可能的环境组合,除非被观测数据明确排除。
模型的核心算法可拆解为:
目标函数:最大化熵 H(p)=−∑p(x)lnp(x)
约束条件:环境变量期望值与观测数据匹配,即 ∑p(x)fi(x)=N1∑j=1Nfi(xj)
通过拉格朗日乘数法求解,最终得到形如 p(x)=Z1exp(−∑λifi(x)) 的概率分布。其中:
fi(x) 为环境变量特征函数(如线性项、二次项、阈值函数)
λi 为对应特征的权重系数
Z 为归一化常数,确保概率和为1
优势解析:
存在点数据友好:传统模型需要缺失数据,而MaxEnt可直接利用存在点+背景点
非线性关系捕捉:通过特征组合自动学习温度与海拔的交互作用。
计算效率卓越:Java内核优化,处理栅格数据时速度比随机森林快3-5倍
典型应用场景:
濒危物种历史分布复原
入侵物种潜在扩散区预警
气候变化情景下物种范围偏移预测
2 数据准备及预处理
首先是根据自己的需求去获取相应的数据。这里提供一些数据获取的网站:
气候数据:http://wondclim.org
土地覆盖数据:https://zenodo.org/records/14729665
植被类型数据:https://www.resdc.cn
landsat9影像:EarthExplorer
DEM:ASF Data Search
地理信息资源:国家地理信息公共服务平台 天地图
当然,作者也已经将数据全部获取并预处理了,需要数据私信,待看到信息后会网盘发送。
| 序号 | 变量缩写 | 变量名称 | 单位 | 原始分辨率 |
| 1 | BIO1 | 年平均气温 | ℃ | 1km |
| 2 | BIO2 | 最热月最高温度 | ℃ | 1km |
| 3 | BIO3 | 最冷月最低温度 | ℃ | 1km |
| 4 | BIO4 | 年降水量 | mm | 1km |
| 5 | DEM | 海拔 | m | 12.5m |
| 6 | Aspect | 坡度 | 度 | 12.5m |
| 7 | Slope | 坡向 | 度 | 12.5m |
| 8 | Vege_types | 植被类型 | 分类 | shp数据 |
| 9 | FVC | 植被覆盖度 | 分类 | 250m |
| 10 | NDVI | 归一化植被指数 | 分类 | 30m |
| 11 | Animals | 距离野生动物的距离 | m | shp数据 |
| 12 | Dis_river | 距最近河流的距离 | m | shp数据 |
| 13 | Dis_rode | 距最近道路的距离 | m | shp数据 |
| 14 | Dis_settlement | 距最近居民点的距离 | m | shp数据 |
3 最大熵模型及JAVA环境安装
3.1 JAVA环境
首先电脑需要包含java环境,如果已有可以忽略该步骤,没有的话需要先安装java
java的官网为:https://www.java.com/zh-CN/
在官网上下载适配于自己电脑的jdk即可。
也可以下载本文提供的资源:【免费】JDK-64位安装包资源-CSDN文库
也可以百度网盘获取(文件失效请联系作者):
通过网盘分享的文件:jdk-8u301-windows-x64.exe
链接: https://pan.baidu.com/s/1KrcdkbC4UYJuzFlzdcfvvA?pwd=1111 提取码: 1111
安装完成后需要配置环境。
此电脑→属性→高级系统设置→环境变量→系统变量。
首先新建两个系统变量:
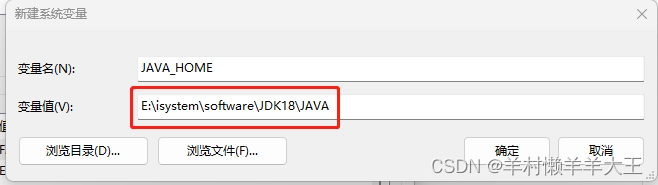
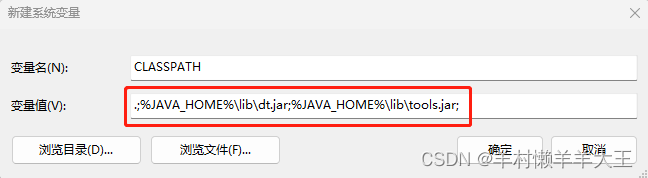
第二章图片的变量名防止键入错误,可以直接复制 ↓
.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
在”path“变量下,新建两个变量。
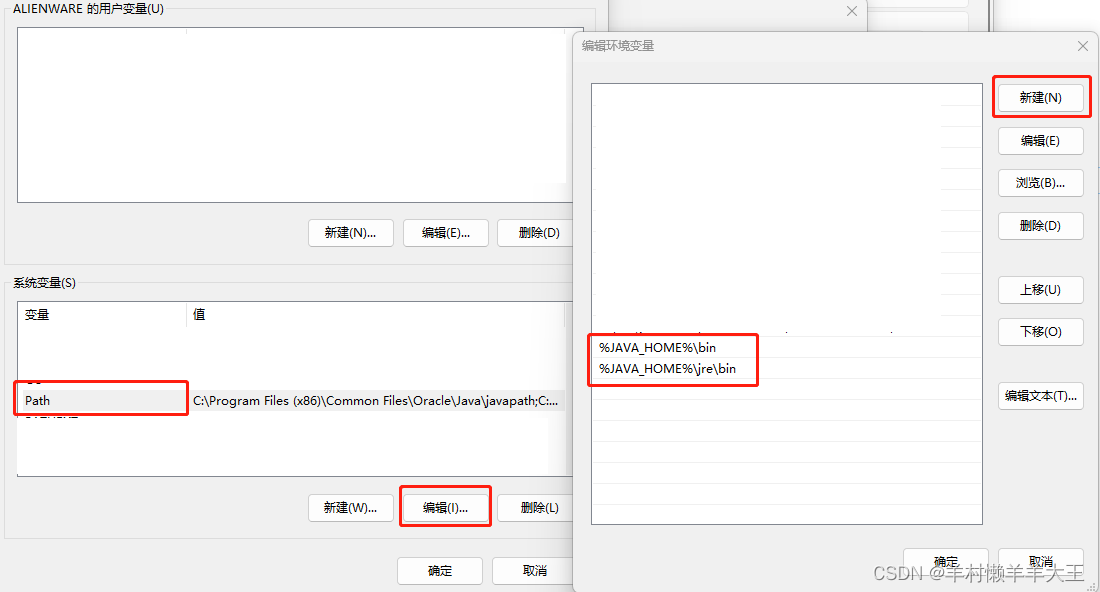
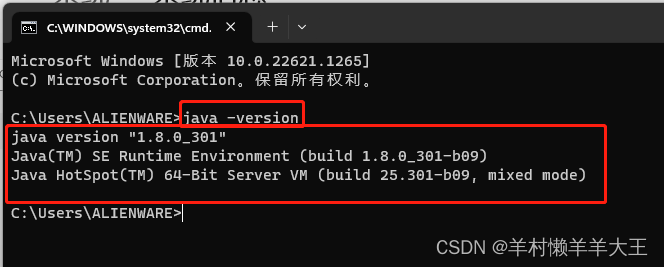
完成后,运行电脑的doi窗口(win+r,键cmd)输入”java“与”java -version“,查看Java是否安装成功,出现版本号即为成功。
3.2 最大熵模型
最大熵模型作者已上传百度网盘(文件失效请联系作者):
通过网盘分享的文件:maxent
链接: https://pan.baidu.com/s/1O8wPD_pK_unq8o5-UajaUA?pwd=1111 提取码: 1111
文件解压缩即可,无需安装,文件启动路径如下:maxent\maxent\maxent.jar
4 基础数据制备
4.1 海拔、坡度、坡向
打开arcgis软件,添加已下载的DEM数据与研究区范围数据:
首先对DEM数据进行裁剪,工具如下:工具箱→空间分析工具→提取分区→按掩膜提取。
掩膜后的数据即可作为海拔数据:
接着,处理坡度和坡向,工具位置为:工具箱→3D分析工具→栅格表面→坡度/坡向
4.2 距水源距离
加载自己所研究物种的点位数据,加载水资源数据:
本文下载的是全国地理信息平台所提供的水系分布数据,首先对全国水系进行裁剪
工具如下:地理处理→裁剪
接下来进行邻域分析,计算物种分布点距离水源的最近距离。
工具如下:工具箱→分析工具→邻域分析→近邻分析。邻近要素为水系线。
查看物种点要素字段,会多出”NEAR_DIST“字段。
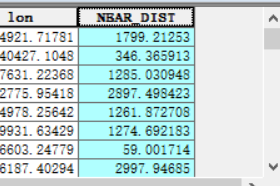
最后将点转换为栅格,我这里物种点要素较少,选择的是克里金插值为栅格。
工具:工具箱→空间分析工具→插值分析→克里金法。
4.3 人为活动干扰
添加居民点数据,居民点数据与物种分布点数据做邻域分析
工具如下:工具箱→分析工具→邻域分析→近邻分析。邻近要素为居民点。
将生成的临近点转换为栅格。
4.4 距道路距离(除铁路外)
添加交通数据,道路数据与物种分布点数据做邻域分析
工具如下:工具箱→分析工具→邻域分析→近邻分析。邻近要素为道路线。
将生成的临近点转换为栅格。
4.5 气候环境变量
我们需要加载一个专门处理环境变量的工具包:SDMtoolbox
SDMtoolbox:Downloads - SDMtoolbox
arcgis是没有这个包的,需要自己去官网下载对应版本号的包。
下载完成后是一个压缩包,解压文件,打开”arccatalog“,点击工具箱按钮,在弹出的对话框内右键”arctoolbox“,选择”添加工具箱“,在弹出的目录界面下,选中下载路径下刚刚下载的包”SDM_Toolbox_v2.6_ArcMap10.9.tbx“即可。
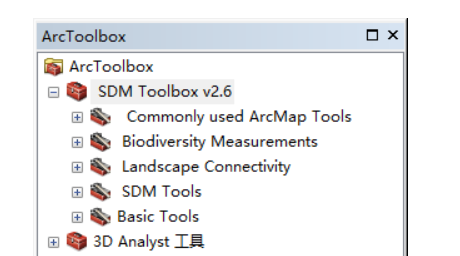
回到arcgis界面,打开已下载的气候数据。
本文选取了”最冷月最低气温tmin“,”最热月最高气温tmax“,”平均气温tavg“,”降水量prec“,”太阳辐射srad“,”风速wind“,”气压vapr“,作为气候变量数据。
分别将这些数据裁剪为本研究区的范围。
5 数据预处理
5.1 统一边界
需要将所有数据的边界统一,防止出现空间拓扑问题。
保证处理范围、行号、列号、像元一致。
在掩膜、裁剪时,采用统一的边界。
5.2 数据重采样
在输入最大熵模型前,需要统一所有数据的空间分辨率,空间分辨率建议从细化到粗话处理,所以本文将所有空间分辨率都转换为1km × 1km。
重采样工具:工具箱→数据管理工具→栅格→栅格处理→重采样。
5.3 统一坐标系
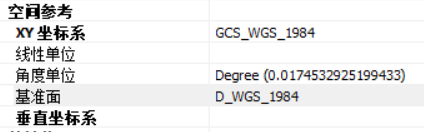
本文统一所有数据坐标系为WGS1984。
5.4 统一格式
最大熵模型的输入数据格式为.asc文件,需要将重采样的文件统一格式转换。
工具为:工具箱→SDM Toolbox→Basic tools→Raster tools→2a raster to ASCII
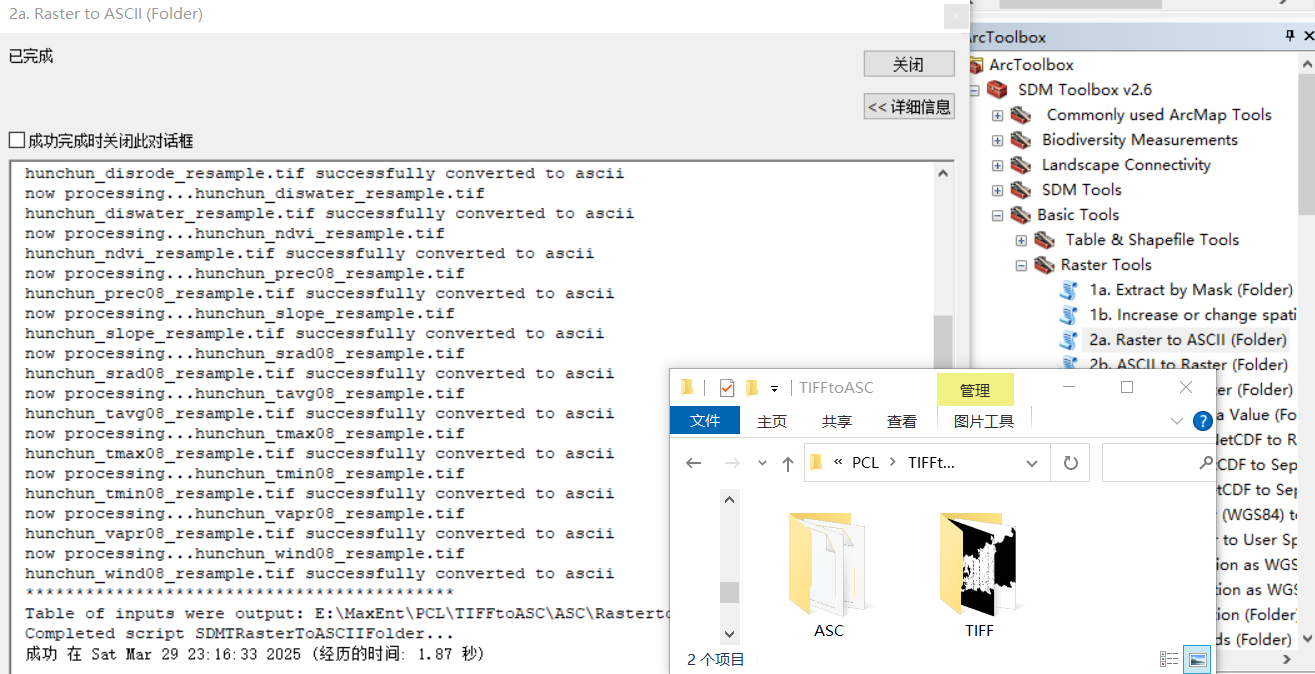
转换完成后,把.asc格式文件加载到arcgis里查看。
5.5 坐标点位预处理
这里需要一个新的软件:”ENMTools“。
通过网盘分享的文件:ENMTools
链接: https://pan.baidu.com/s/1eN5UNxvfr-eAFjoyRhLtiA?pwd=1111 提取码: 1111
双击安装”ActivePerl-5.26.exe“文件,完成后双击启动”ENMTools.pl“程序。
进入EVM后需要先设置最大熵模型的软件:
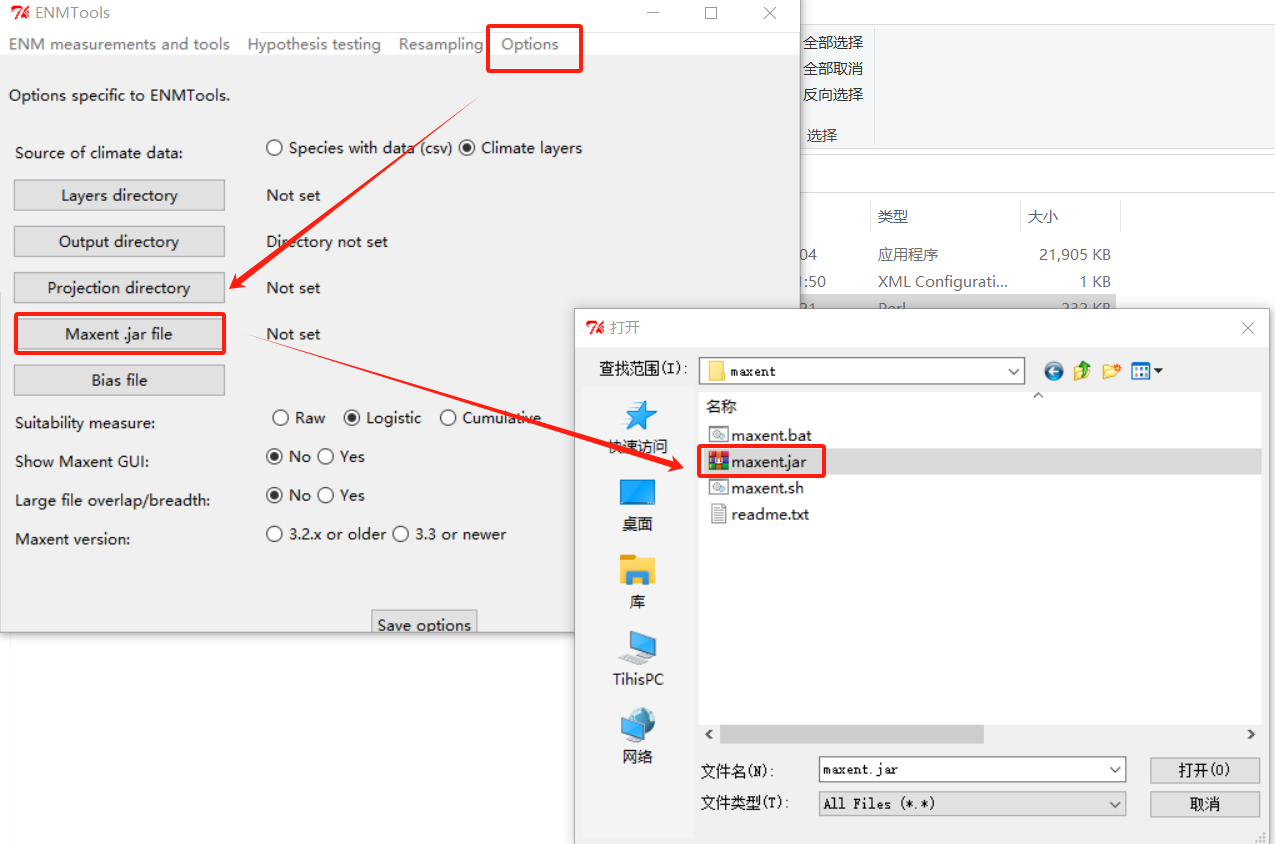
重新打开软件,在”EVM测量与工具下“点击”trim“,加载物种点位坐标。
软件会自动进行空间自相关分析,自动生成新的表格。
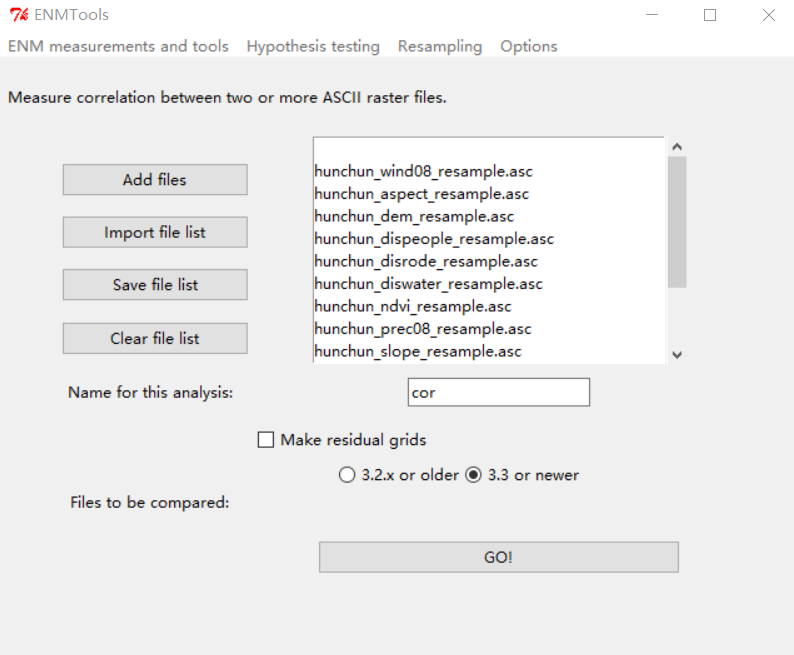
接着在EVM里进行相关性分析”correlation“,加载采样后的ASC文件,
6 最大熵模型
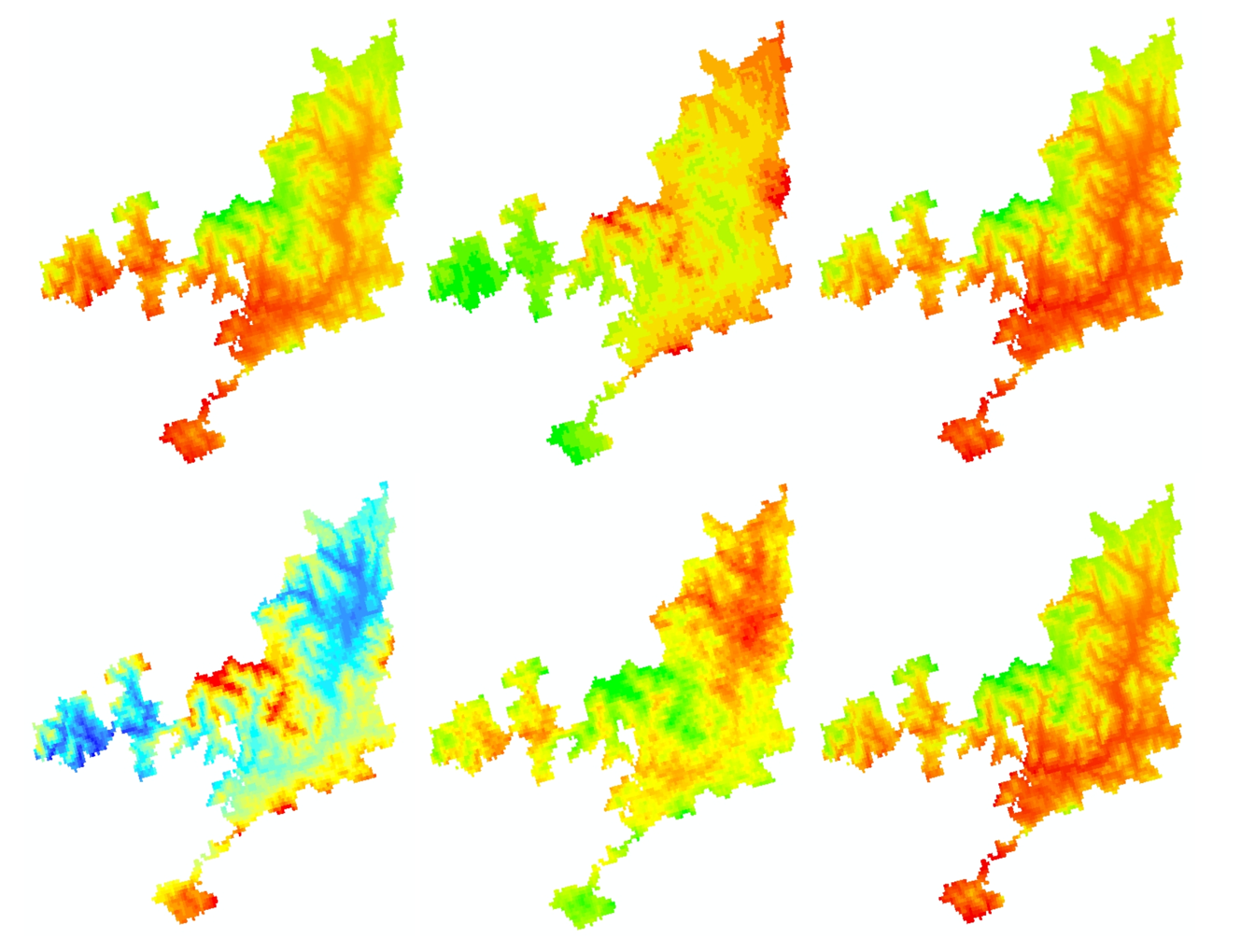
启动maxent最大熵模型软件
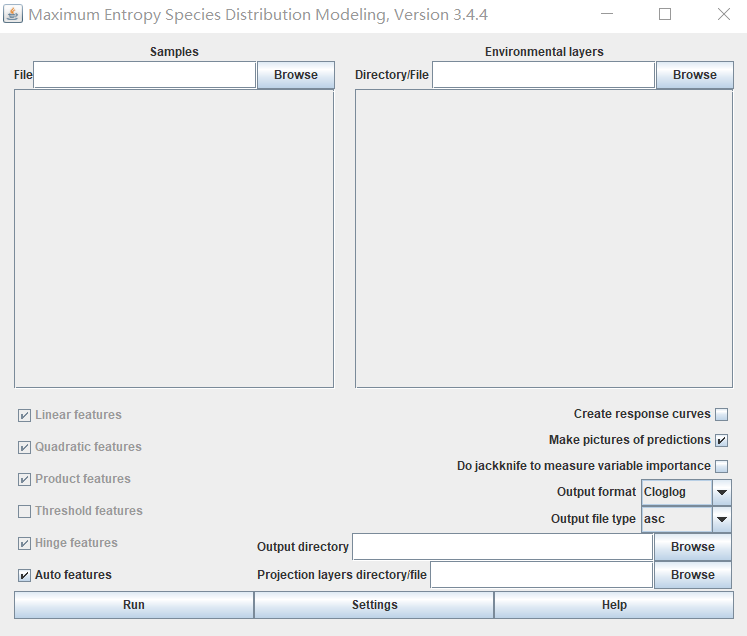
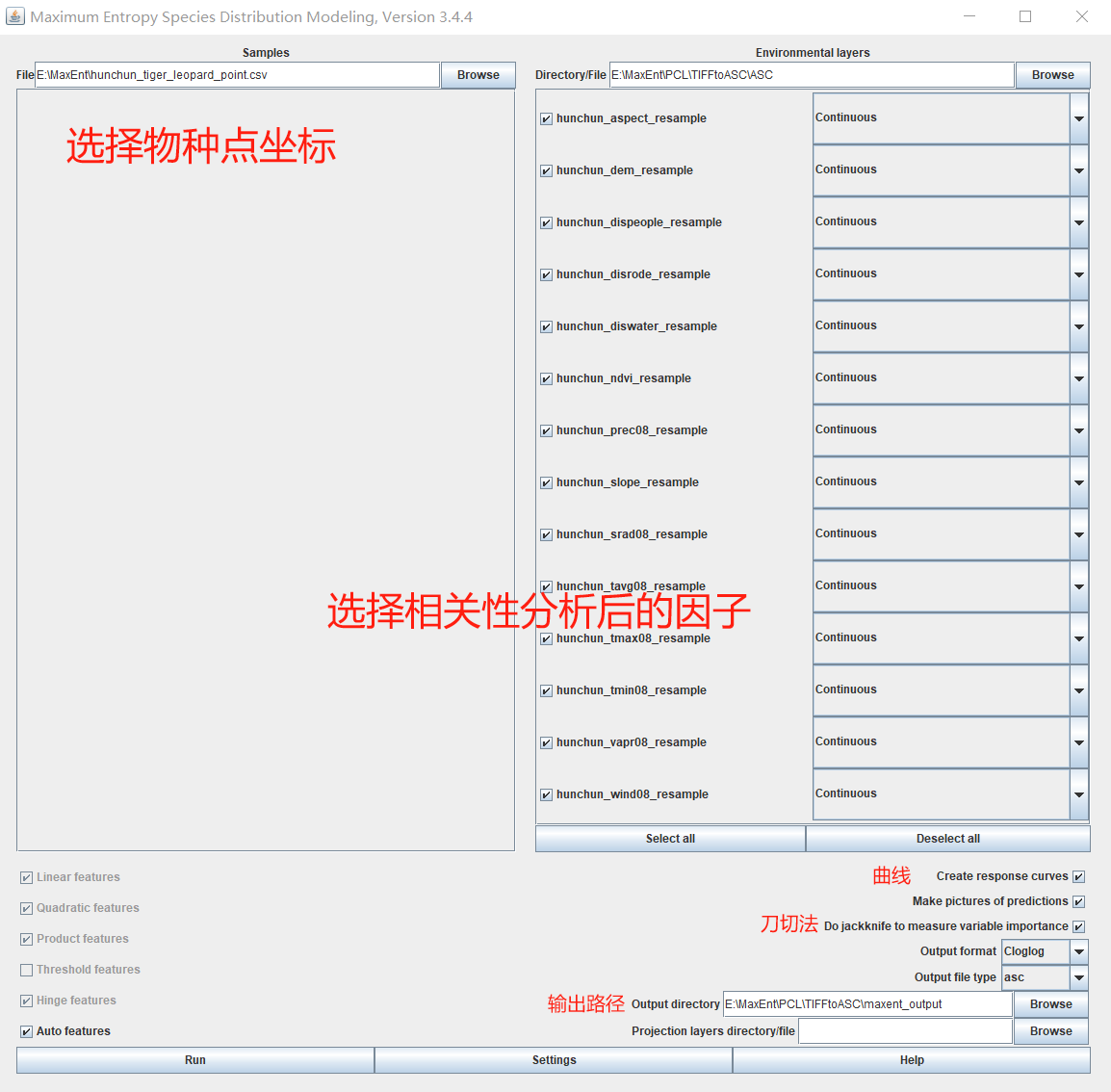
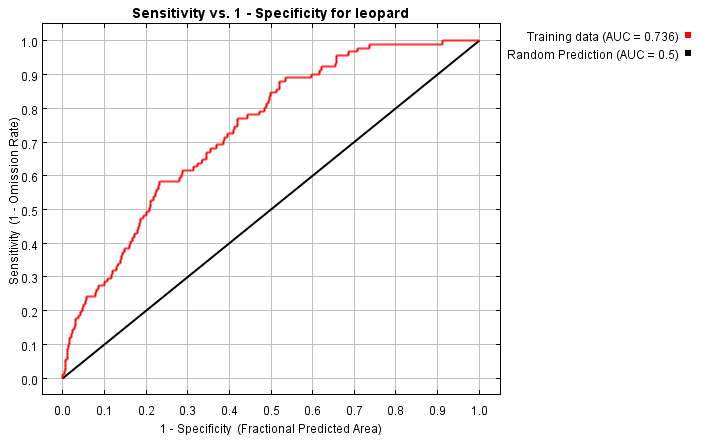
待运行完成后则得到结果,如下图所示:
(本文为模拟数据,未考虑精度)
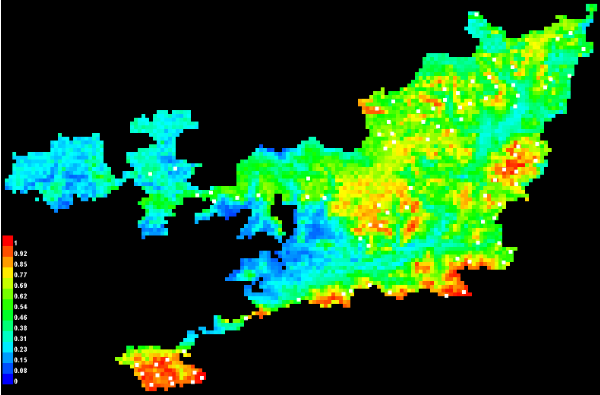
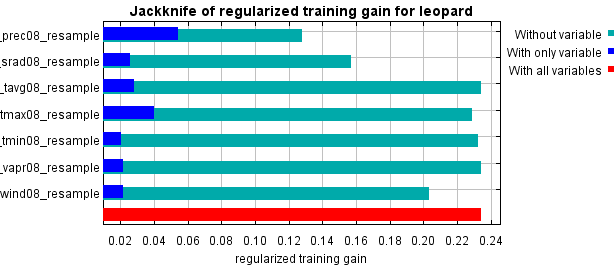
最后,讲一下最大熵模型的参数设置:
在默认情况下(Auto features),当样本不少于80个时,使用所有要类;
通常情况下Linear feature一直在运行
Quadratic feature 在物种分布点>10时使用
Hinge feature在分布点>15时使用
Threshold feature和Product feature在分布点>80时使用;
线性要素(Linear features)样本量(2~9);
二项式要素(Quadratic features)(L+Q:10~79);
乘积要素(Product features)(L+Q+P:80+);
阈值要素(Threshold features)(80+);铰链要素(Hinge features)(15+);
Random seed: 跟下面的重复次数有关,勾选后,每次运行将创建不同的随机测试/训练分区,使用不同的随机环境背景点分别用于测试数据和训练数据集。默认不选,文献推荐使用:
Give visual warnings:可视化警告,默认选;表示运行过程弹窗报错信息。
Show tooltips:显示图表工具提示,默认选;表示显示结果图表中的部分内容提示或文字解释。
Ask before overwriting:数据覆盖前询问,默认选;如果已有输出结果,再次运行时不更换保存地址会提示是否覆盖原文件。
Skip if output exists:跳过已存在输出文件,默认不选
Remove duplicate presence records:移除重复物种位点,默认选;
Write clamp grid when projecting: 默认选,对结果没有影响,只有用于未来预测时才能生效。
Do MESS analysis when projecting:默认选,当用于未来预测时,结果会显示相应的环境变量最适宜区域。
Random test percentage:随机测试数据集,默认为0,一般设置为25%;
Regularization multiplier:正则化参数,默认为1,文献推荐0-3之间;值越大,泛化能力越大,值越小拟合可能不足。
Max number of background points:采用最大的环境背景点,默认为10000
Replicates:重复运行次数默认为1,一般常设置10次。
Replicated run type:重复次数运行类型,迭代1次,选择交叉验证方式,是测试数据和训练数据的交叉验证(Crossvalidate);当重复次数大于1时,选择自助法(Bootstrap)即通过有放回抽样重新选择物种位点集合;而选子样品(subsample)则是排除点用于测试数位点据集后重采样。
Test sample file: 输入测试文件则是人为替代模型选定的测试数据集。
Add samples to background: 添加用来测试的位点到背景图,默认选。
Add all samples to background: 添加所有位点值到环境背景点中,默认不选。
Write plot data:输出图表数据文件,默认不选;推荐选,文件包含用于制作响应曲线(Response curves)的数据,以便使用外部绘图软件重新绘图。
Extrapolate:外推,默认选;预测在训练数据集模拟过程中,这些训练位点受限之外,根据环境数据来进行外推预测。
Do clamping:默认选,用于未来预测时使用“钳制”工具。
Write output grids:默认选,勾选后指在重复运行次数大于1时,每次重复运行都输出一个预测图结果;如果不勾选则只输出有标准差,均值的预测图结果
Write plots:默认选,在html网页中生成各种结果图,方便整体查看结果
Append summary results to maxentResults.csv file:默认不选,建议选,会输出一个.cvs格式的简要输出结果。
Cache ascii fles:保存.asc格式文件,默认选;用于输出预测图的.asc 格式文件。
喜欢本篇文章请多多关注,您的鼓励是我最大的动力。欢迎大家互相分享交流。(aaanimals)



















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











