







Micro-expression recognition with supervised contrastive learning基于监督对比学习的微表情识别——2022 PRL
文章链接:https://www.sciencedirect.com/science/article/abs/pii/S0167865522002690
以下为论文主要内容简述
Abstract
面部微表情是面部肌肉的不自主运动,暴露了个人的潜在情绪。由于面部肌肉变化的微妙性和多样性,提取有效的特征来识别微表情是一个挑战。本文提出了一个有监督的对比学习(MER-Supcon)的微表情识别框架,其主要目的是提取微表情的关键特征,并克服不相关的面部运动引起的噪音。首先,提出了一种新的双终端微表情采集策略,并应用于获得光流图,旨在扩大数据集并减少微表情定位的不利影响。然后,引入监督下的对比学习来学习微表情的关键表征进行分类。在CASME II和SAMM数据集上的研究结果表明,与最先进的方法相比,该方法在三类和五类评估中都是有效和有竞争力的。
Introduction
微表情识别的研究主要包括传统方法和深度学习方法。传统方法使用人工提取的特征,然而,设计通常不太稳健和繁琐。深度学习方法主要包括长短时记忆(LSTM)、卷积神经网络(CNN)和图神经网络(GNN)。由于样本不足,模型的复杂性很容易导致训练过程中的过拟合问题。数据增强可以通过增加样本的数量来缓解这个问题,但同时也会产生噪音。
为了在噪声分布下学习可信的微表情表征,我们考虑了有监督的对比学习。图1显示了传统监督学习、自监督对比学习和监督对比学习方法的比较。常见的自监督对比学习被广泛用于最大化相似样本之间的相互信息。然而,由于没有可用的信息,具有相同标签的样本可能会被误判为负面样本,正如那个快乐的女孩(图1(b)的底部)所展示的那样。由于样本有限且类别不多(少于7个),MER的误判问题更为突出。如图1(c)所示,带有标签的监督性对比学习可以避免误判。

本文的主要贡献有以下几点。
1. 提出了有监督的对比学习的微表情识别(MER-Supcon),以提取噪声分布下的关键面部特征,同时减少不相关因素(眼睛眨动、头部运动和旋转)的影响。该框架包含监督下的对比性表示学习阶段和分类阶段。
2. 提出了双终端微表情采集策略,考虑了微表情从开始到结束和从偏移到结束的变化,从而缓解了样本不足和微表情定位的不利影响。
3. 对公开的CASME II和SAMM数据集的综合评估表明,我们的方法与最先进的方法相比,在三类和五类评估中都是有效和有竞争力的。
Method
MER-Supcon的整体框架如图2所示。首先,采用运动放大法来放大ME的细微运动,然后在光流中采用双端微表情采集策略。其次,进行监督下的对比表征学习方法来训练骨干网络以提取关键的面部特征。然后,我们冻结了训练后的网络的权重和参数,用于分类阶段。最后,训练分类器来预测微表情的类别。

1、Video Motion Magnification
视频运动放大法放大了一个时期的运动矢量,并叠加权重以放大视频序列中的微妙运动。与基于手柄过滤器的方法相比,基于学习的视频运动放大方法[11]通过深度卷积神经网络直接学习过滤器。该网络从输入帧中提取表征,然后通过乘法来操纵运动,重建一个放大的帧。操纵器的工作原理是取两个给定帧的表征之间的差异,并对其乘以一个放大系数。


2、 Dual-terminal Micro-expression Acquisition Strategy
由于微表情(MEs)短暂而迅速,MEs数据集的样本通常由高速摄像机(200fps)采集,因此每一帧都非常相似。为了减少计算成本和特征冗余,[8]、[10]、[12]采用起始帧和顶点帧来表示每个微表情序列,表现良好。一般来说,起始帧、顶点帧和偏移帧的标签是同时标记的,然而,在以前的方法中,偏移帧通常被忽略。顶点帧具有最明显的微表情强度。偏移帧和起始帧表示无表达和微表达之间的界限。因此,为了扩展不充分的微表情数据,我们选择使用起始帧、顶点和偏移帧来描述MEs序列的高强度信息。图4显示了起始帧、顶点帧和偏移帧之间的划分。

在实际应用中,微表情识别通常是在微表情定点工作之后进行。如果起始帧识别不够准确,ME的持续时间会比较短,变化也会比较细微。因此,为了减少微表情定位的影响,我们提出了双终端微表情采集策略,即考虑从边界帧到顶点帧的变化(起始-顶点和偏移),这可以更好地代表微表情中的动态信息。该策略不仅可以扩展有限的数据集,还可以减少微观表达定位的不利影响。光流图描述了两幅图像之间的像素变化,可以捕捉到面部的细微运动。因此,我们在光流图中应用了双端微表情采集策略来描述微表情的时空信息。

图五显示了应用双终端微表情采集策略后的两组光流图。在(a)和(b)中,由于起始帧检测不及时,offset-apex在眉毛和眼睛区域的信息比onset-apex多。在(c)和(d)中,由于受试者在MEs持续时间的前半段有头部运动,而在后半段没有,所以偏移指数在下巴区域的头部运动的噪声干扰较小。通过对光流图采用双终端微表情采集策略,数据集中的样本数量得到扩大,样本特征信息也变得丰富。
3、Supervised Contrastive Representation Learning Stage
为了学习关键的面部特征,我们设计了一个基于对比学习的两阶段框架。受监督的对比性学习阶段由数据增强模块、表示学习模块和受监督的对比性损失组成。数据增强模块为给定的一批输入图像生成两个视图。主干网络提取这两个视图的特征表示。在训练过程中,该表征通过对齐矛进一步传播,以转换维度,而输出则用于计算监督对比损失。
3.1 Data Augment
数据增强操作A()集包含不同的操作,如水平翻转、对比度调整、灰度转换和擦除转换,每个操作都以随机的概率工作。对于输入图像,我们使用生成两个随机的增强图像和 ,每个都代表输入图像的不同视图。它制约着模型学习相应的 "不变性",使学习的模型更加稳健。
3.2Backbone Network and Align Spear Network
浅层网络Resnet18 [14]被用作骨干网络以缓解过度拟合问题。增强的样本被分别送入骨干网络,骨干网络将输入的增强样本映射成一个表示向量。表征向量被归一化为512维()的嵌入式单元超球。一个非线性变换结构(align spear)在骨干网络之后被用来将表征投射到一个可比较的流形。align spear由一个多层感知结构组成,它将特征表示从512维映射到128维的单位超球()。

3.3Supervised Contrastive Loss
在训练过程中,对于一批中的N个样本/标签对,经过数据增强操作(随机水平翻转、对比度调整、灰度转换和擦除变换),产生2N对增强图像和。对于 "锚 "来说,与 "锚 "类别相同的样本是正面的,而其他的是负面的。正面的例子预计会更接近,负面的例子会更远。我们采用监督下的对比损失函数来实现这个过程,它的定义如下。

监督对比损失的优势在于,对于任何一个锚,批次中的所有正向例子都对分子有贡献。ME的类别通常在7以下,批次大小一般大于类的数量,因此在一个批次中通常有多个正例。在这种情况下,监督损失鼓励编码器为同一类别的所有样本提供紧密一致的表示,从而使表示空间的聚类更加稳健
3.4. Classification Stage
为了使用经过训练的模型进行分类,我们冻结模型的权重和参数,并使用交叉熵损失来训练线性分类器。经过预处理的测试样本(运动放大和光流提取)被送入训练模型,然后线性分类器预测微表情的类别。第二阶段训练线性分类器的目的是隔离监督对比度丢失的影响,以便我们能够提取第一阶段网络中的关键面部特征。
4. Experiments
表1和表2显示了我们提出的MER-Supcon方法和对比方法在CASME II和SAMM数据集上对3类和5类微表情的表现。最好的结果用粗体表示,亚军则用下划线表示。为了避免对某一主体的依赖,实验采用了 " Leave-One-Subject-Out "的交叉验证方法,每次选择一个主体的所有样本作为测试集,其他样本作为训练集。
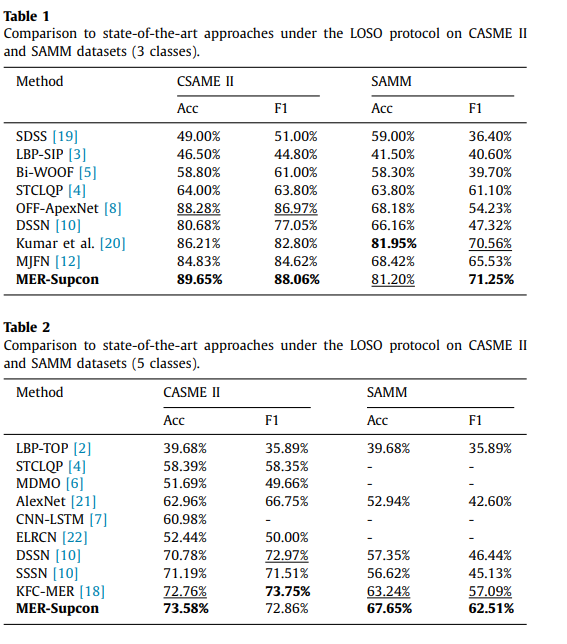
CASME II和SAMM数据集的混淆矩阵如图6所示。此外,可以观察到,对于CASME II数据集,错误判断主要集中在“其他”类,这可能与类之间的不平衡有关。其他类别之间的区别是显而易见的。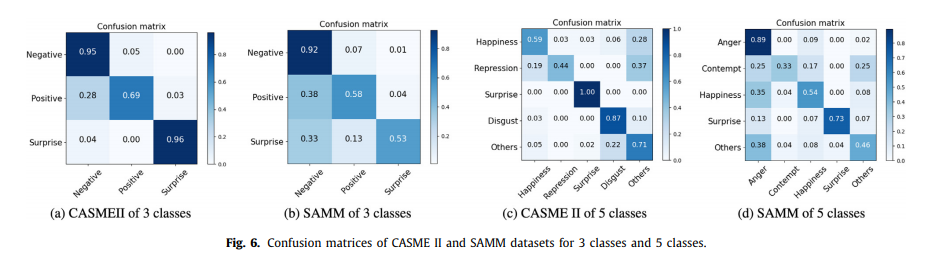
4.5. Ablation study
为了观察双终端微表情获取策略的影响,我们进行了将其融入其他方法的实验。为了进行公平的比较,我们复制了原作者在其网站上发布的三种先进的 MER 方法,并在其中添加了双终端微表达获取策略。表3分别显示了3个类的 CASME II 和 SAMM 数据集的结果。可以看出,双终端微表达获取策略对 MER 方法有增强作用。具体来说,CASME II 数据集的改善是显著的,SAMM 数据集的 F1评分改善比 ACC 的改善更为明显。
由于RCN-A方法在其实验中没有提供光流图方法,因此我们采用了我们实验中生成的光流图,这可能是RCN-A的再现结果优于最初报告值的原因。
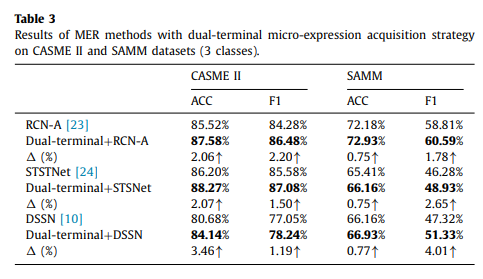
此外,为了观察 MER-Supcon 提取的特征,我们返回最终提取的图像特征的激活强度作为热图。可视化显示如图7所示。在第一行,我们可以看到,与 Resnet18相比,我们的方法 MER-Supcon 更多地关注眉毛区域抑制情绪。在第二排,MER-Supcon 不受头部旋转(右下)的影响,并且强烈地集中在触发惊讶情绪的眉毛和眼睛区域。对于第三行,热图显示,与 Resnet18相比,MER-Supcon 不会受到眨眼的干扰,并且更加关注嘴角的关键微表情。这些结果验证了该方法的有效性,表明该网络更加关注人脸的关键特征,克服了由于不相关的人脸运动而产生的噪声。
5.Conclusion
本文提出了一种基于监督对比学习的微表情识别方法(MER-Supcon)。据我们所知,这是第一次尝试用对比学习来指导微表情识别的特征学习。我们的模型集中在关键的面部特征和抑制噪声干扰。此外,本文还提出了一种双终端微表情获取策略,并将其应用于光流图中。得到了两组起始点和偏移点的光流图,从而扩展了有限的数据集,减少了微表达定点的不利影响。最后,在公共数据集上的实验结果验证了该模型的竞争性能。
欢迎大家阅读,分享或引用














 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









